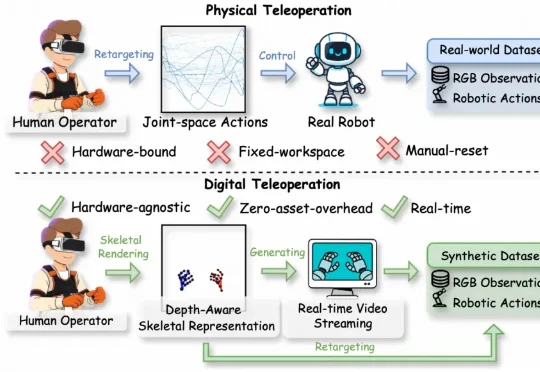
具身数采新方案:数字遥操作,现已开源,达摩院出品
具身数采新方案:数字遥操作,现已开源,达摩院出品阿里巴巴达摩院的最新工作RynnWorld-Teleop对此给出的方案是:用生成式世界模型替代真实机器人。操作员的手势驱动一个实时视频生成器,由“数字世界中的机器人”完成全部视觉演示,同时自动获得关节级的动作标签。该方案被称为数字遥操作(Digital Teleoperation)。
来自主题: AI技术研报
9564 点击 2026-07-18 10:11
 搜索
搜索
阿里巴巴达摩院的最新工作RynnWorld-Teleop对此给出的方案是:用生成式世界模型替代真实机器人。操作员的手势驱动一个实时视频生成器,由“数字世界中的机器人”完成全部视觉演示,同时自动获得关节级的动作标签。该方案被称为数字遥操作(Digital Teleoperation)。

最近,来自 Google、哥本哈根大学、牛津大学等机构的研究者提出了 VGGRPO(Visual Geometry GRPO,收录于 ECCV 2026)。这项工作聚焦于一个核心问题:如何在不牺牲预训练模型泛化能力的前提下,高效地提升视频生成的几何一致性,并使其适用于动态场景。其核心思路是,在隐空间(latent space)中利用 4D 几何奖励,进行几何感知的视频后训练。
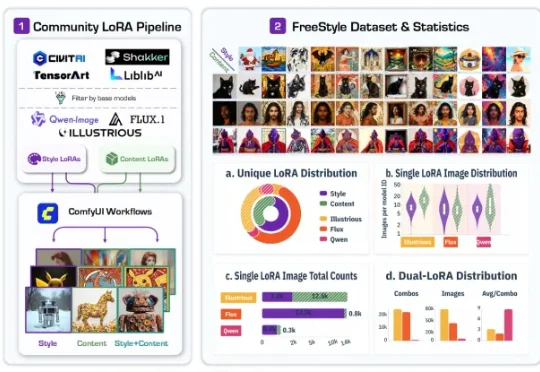
最近,一篇名为 FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining 的工作引起了不少关注。换句话说,FreeStyle 研究的是 style-content dual-reference generation,也就是「内容 - 风格双参考生成」。

曾推出 RoboTwin 系列基准的团队发布了 RoboDojo,一套统一覆盖仿真与真实机器人操作的具身智能评测体系。它包含 42 个仿真任务、18 个真实机器人任务,并将 30 个代表性机器人策略放到同一套标准下比较。

「解释的本质,不在于凝视机器本身,而在于审视机器所凝视的世界」。
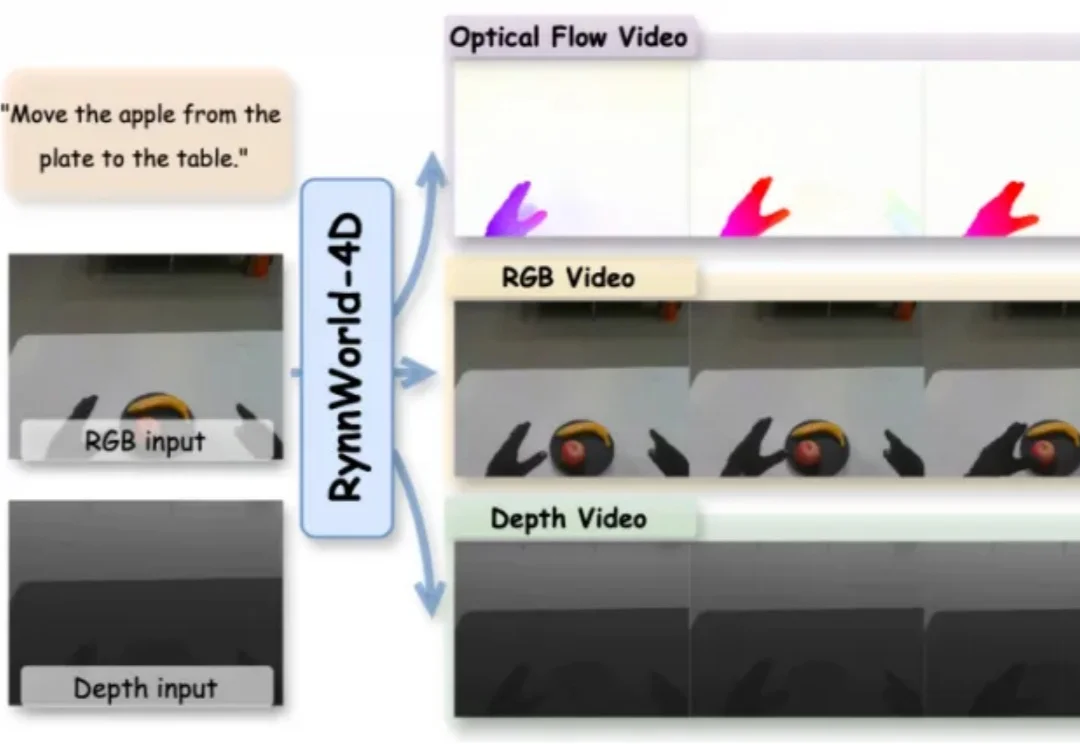
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。
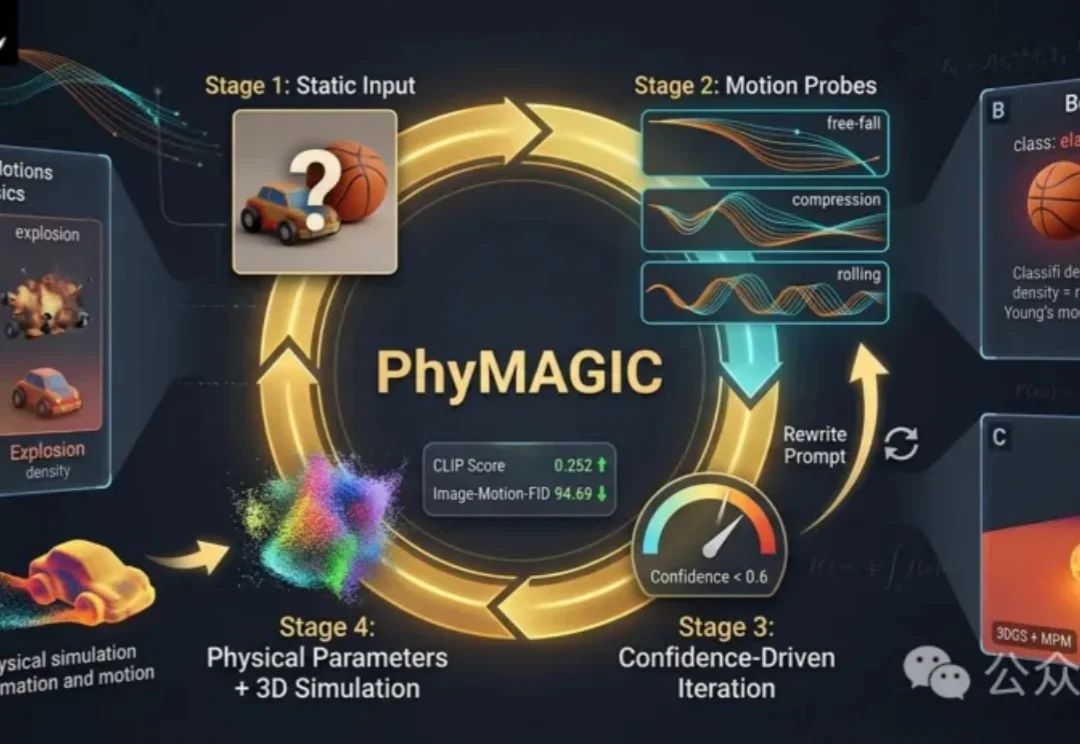
PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。
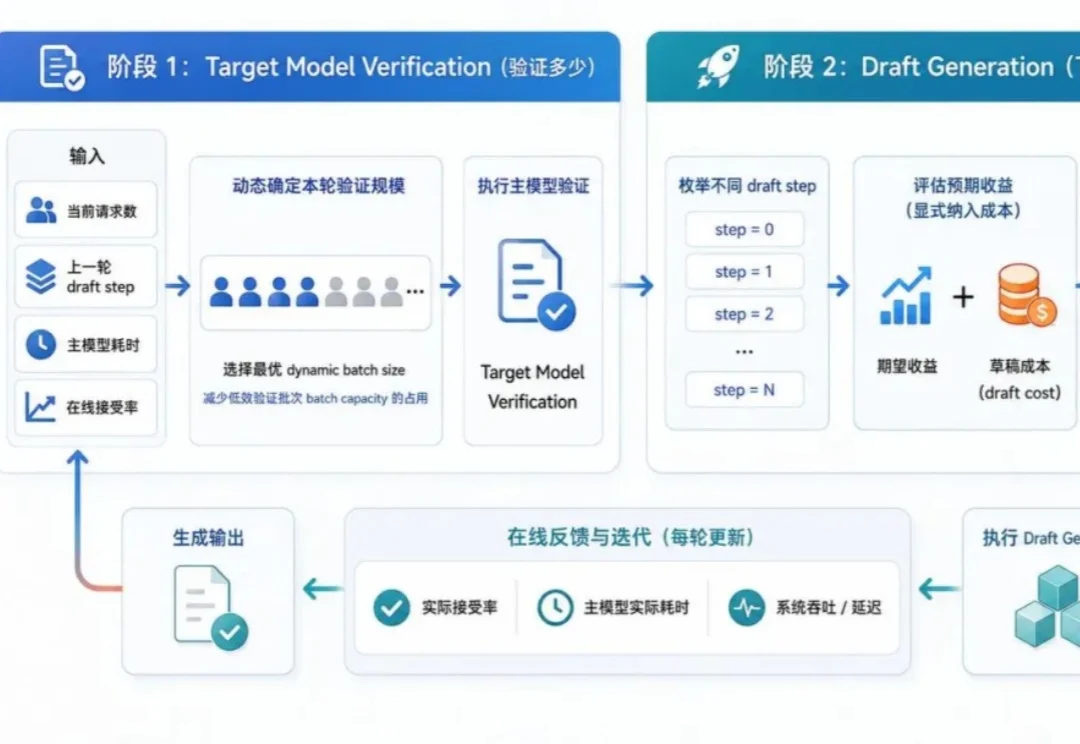
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

今天,小米刚刚扔出一颗“深水炸弹”——Xiaomi-Robotics-1具身基座模型,试图改变这一局面。Xiaomi-Robotics-1基于10万小时真实世界操作轨迹进行预训练,再用约1.1万小时跨本体数据完成后训练。据悉,这是国内首次在机器人策略模型中,对Scaling Law进行较为完整的系统验证。

时至今日,全球大模型格局已成定数,还有必要耗费巨资从零开始训练一个新模型吗?