
奥特曼回斯坦福认错:思考外包给AI,一代人大脑正在萎缩
奥特曼回斯坦福认错:思考外包给AI,一代人大脑正在萎缩学校没变,但奥特曼警告人类正在慢慢失掉思考的训练场。
来自主题: AI资讯
5897 点击 2026-07-16 14:44
 搜索
搜索
学校没变,但奥特曼警告人类正在慢慢失掉思考的训练场。
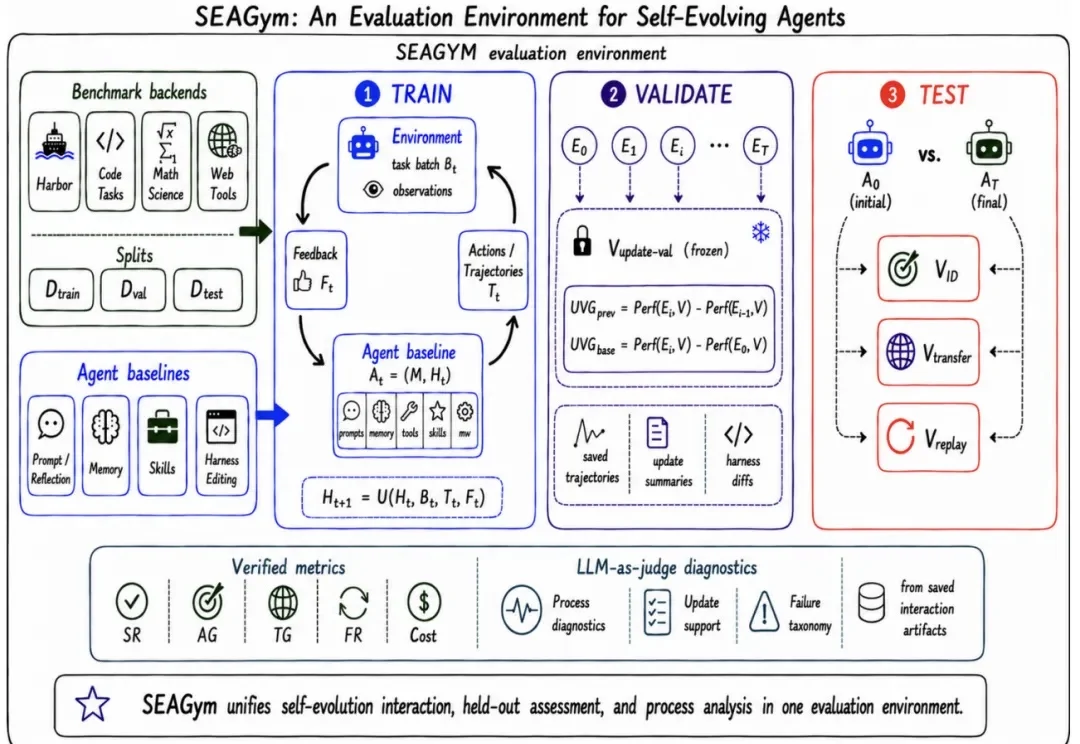
近日,翁荔发布长文 《Harness Engineering for Self-Improvement》,系统梳理了 harness engineering 在 AI 自我改进中的作用。
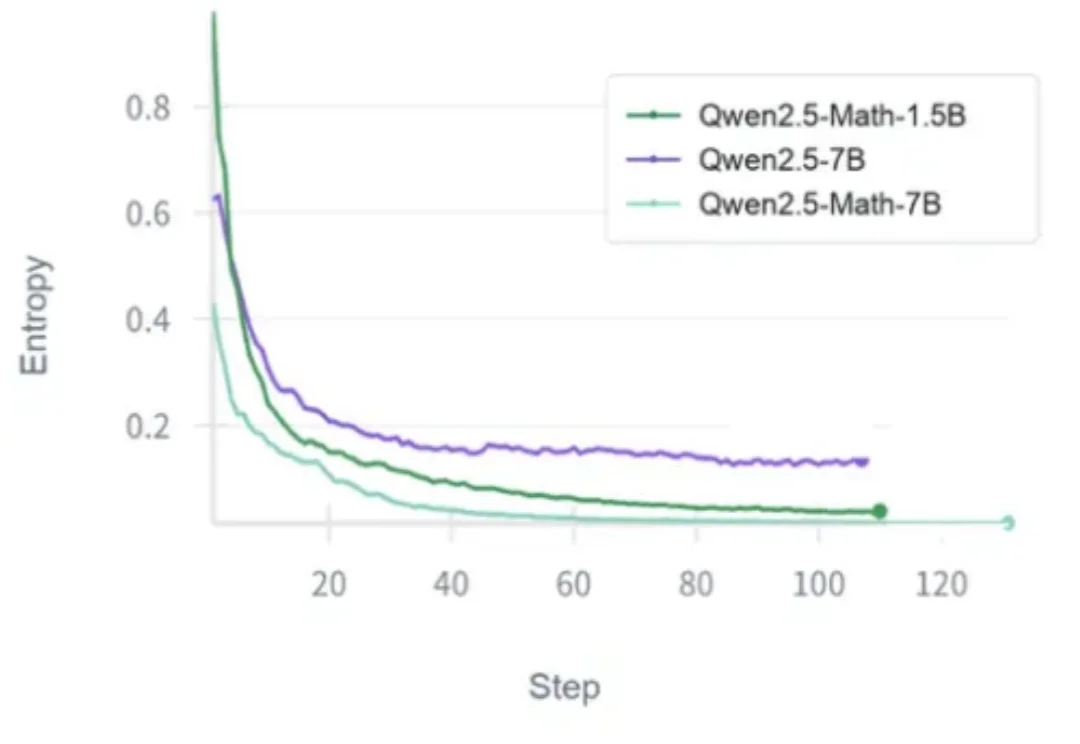
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)正在成为大模型后训练的关键技术。数学题能判对错,代码能跑测试,可验证奖励让大模型可以通过强化学习持续提升推理能力。

WorldArena 1.0 的核心意义,在于将世界模型评测从 “好不好看” 推进到 “是否真的有用”。它不再只关注视频观感,而是把物理一致性、可控性、3D 准确性和具身任务功能性纳入统一评测框架,使许多看似流畅的生成结果第一次在机器人具身任务中接受检验。

推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
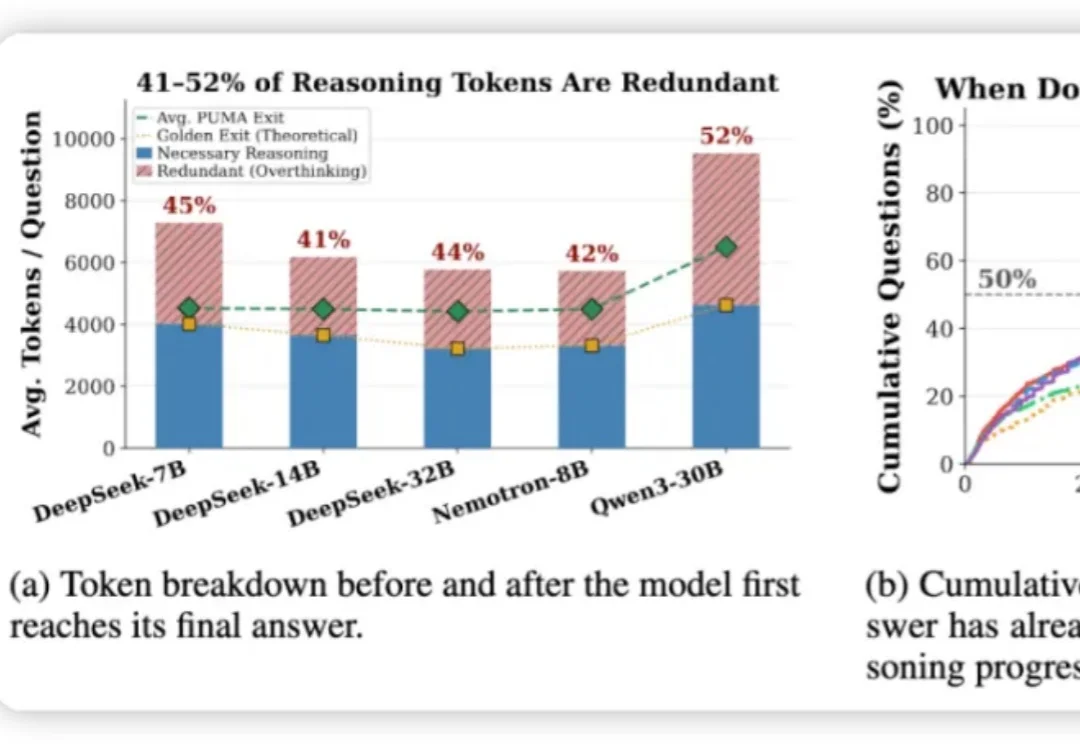
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。

扩散语言模型(DLM)正逐渐成为自回归(Autoregressive, AR)语言模型之外一种新兴的建模范式。

80年前,阿根廷作家博尔赫斯写过一个寓言,叫《博闻强记的富内斯》。博尔赫斯笔下的富内斯,拥有过目不忘、堪称完美的记忆,却无法思考,因为思考依赖于遗忘和抽象。
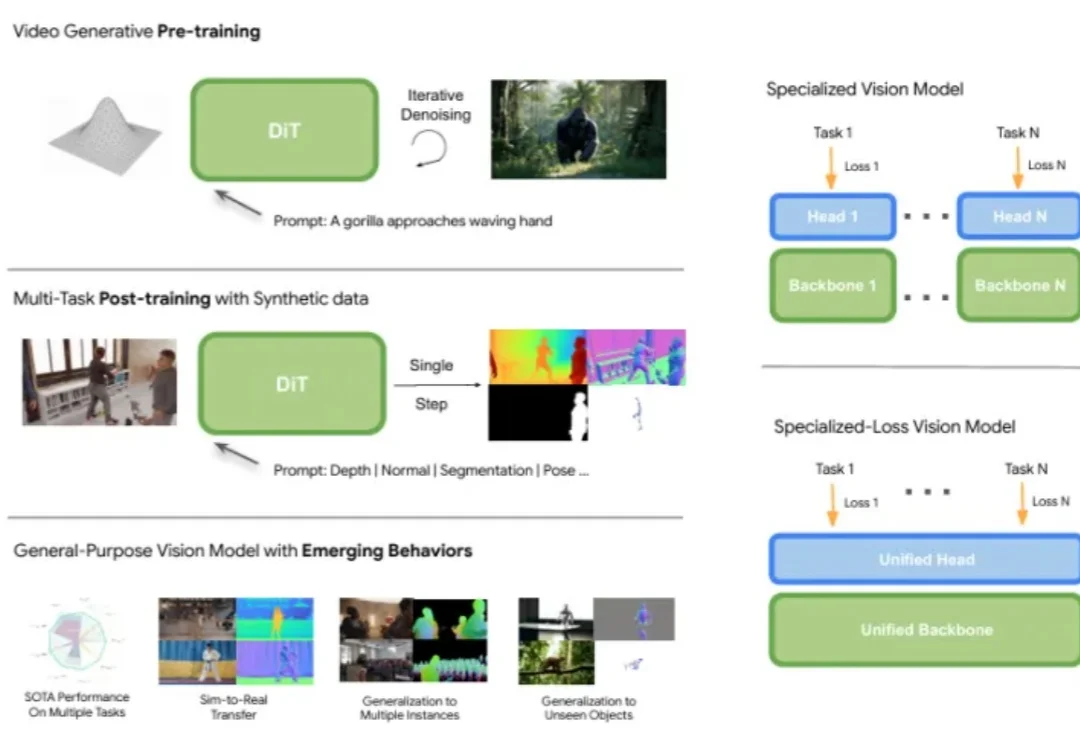
如果想开发一个视频理解应用,你会怎么做?
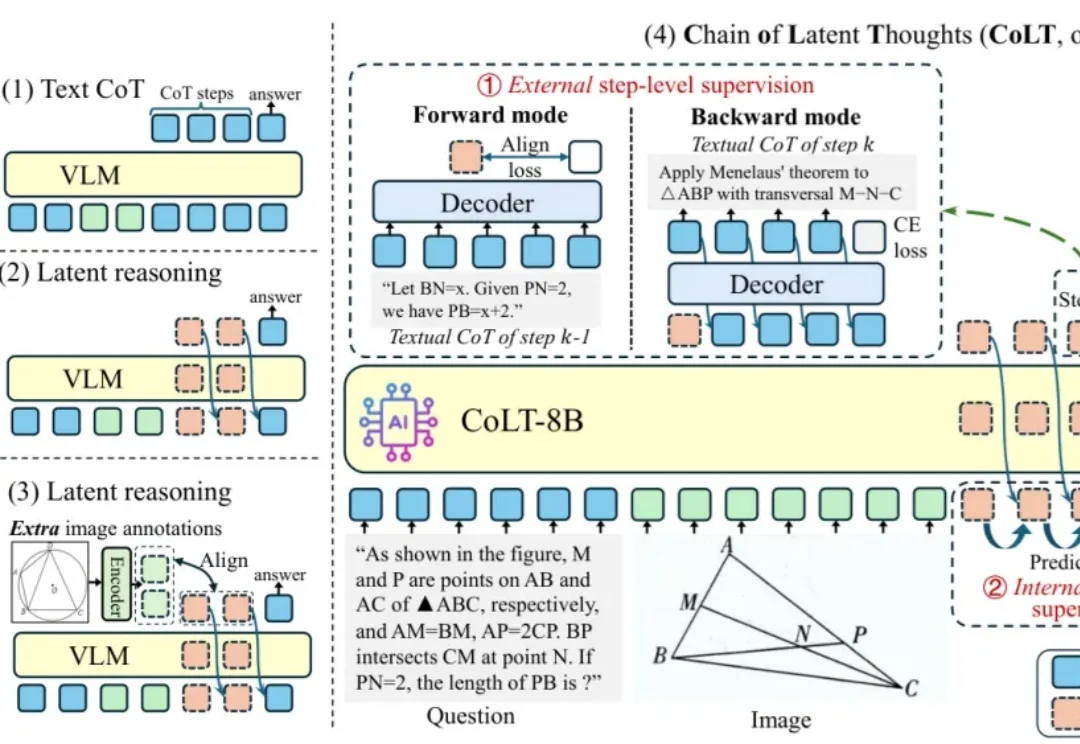
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。