ACL 2024 | 对25个开闭源模型数学评测,GPT-3.5-Turbo才勉强及格
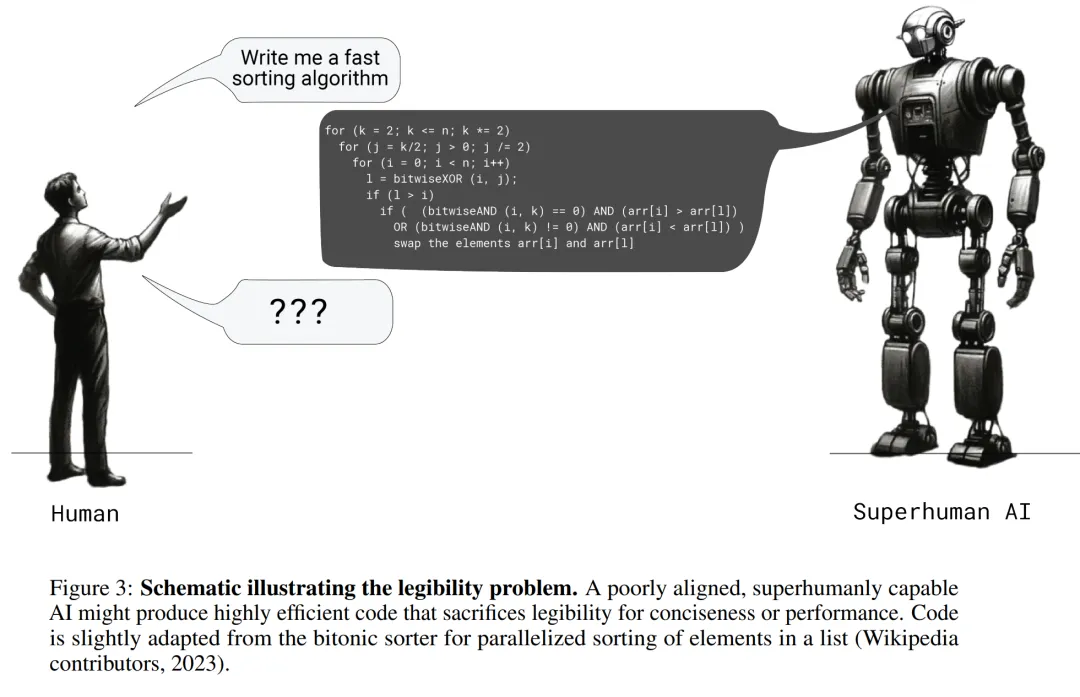
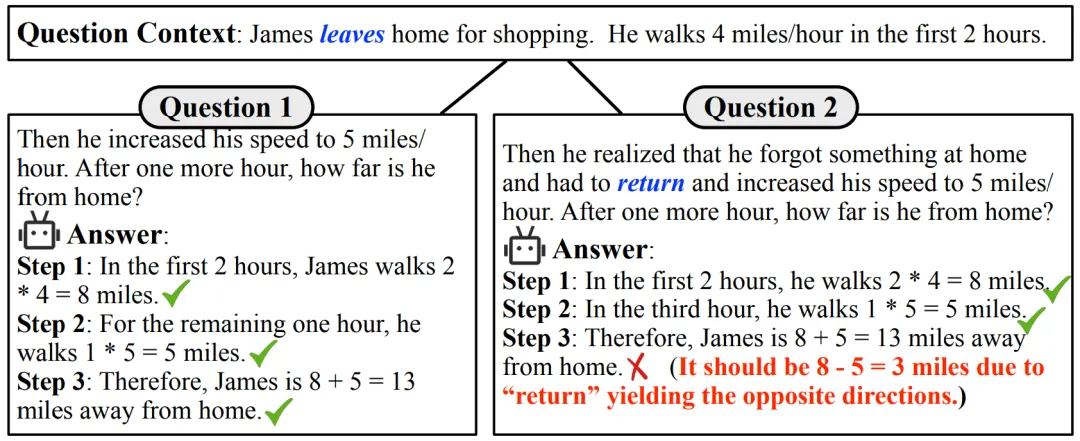
ACL 2024 | 对25个开闭源模型数学评测,GPT-3.5-Turbo才勉强及格大型语言模型(LLMs)在解决问题方面的非凡能力日益显现。最近,一个值得关注的现象是,这些模型在多项数学推理的基准测试中获得了惊人的成绩。以 GPT-4 为例,在高难度小学应用题测试集 GSM8K [1] 中表现优异,准确率高达 90% 以上。同时,许多开源模型也展现出了不俗的实力,准确率超过 80%。
来自主题: AI资讯
9070 点击 2024-07-18 16:57