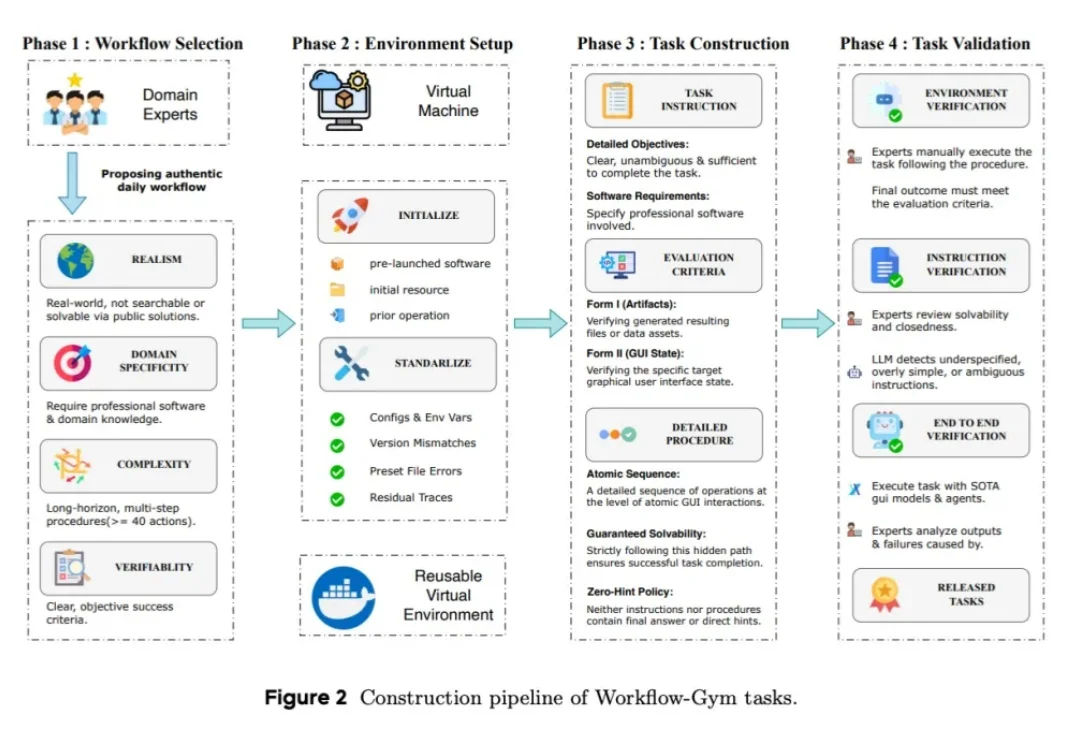
Workflow Gym:告别仿真测试,抹平Agent落地鸿沟
Workflow Gym:告别仿真测试,抹平Agent落地鸿沟你可能已经在各种 benchmark 榜单上看过 GUI Agent 的 "大胜" 了。
来自主题: AI技术研报
6934 点击 2026-07-24 10:45
 搜索
搜索
你可能已经在各种 benchmark 榜单上看过 GUI Agent 的 "大胜" 了。
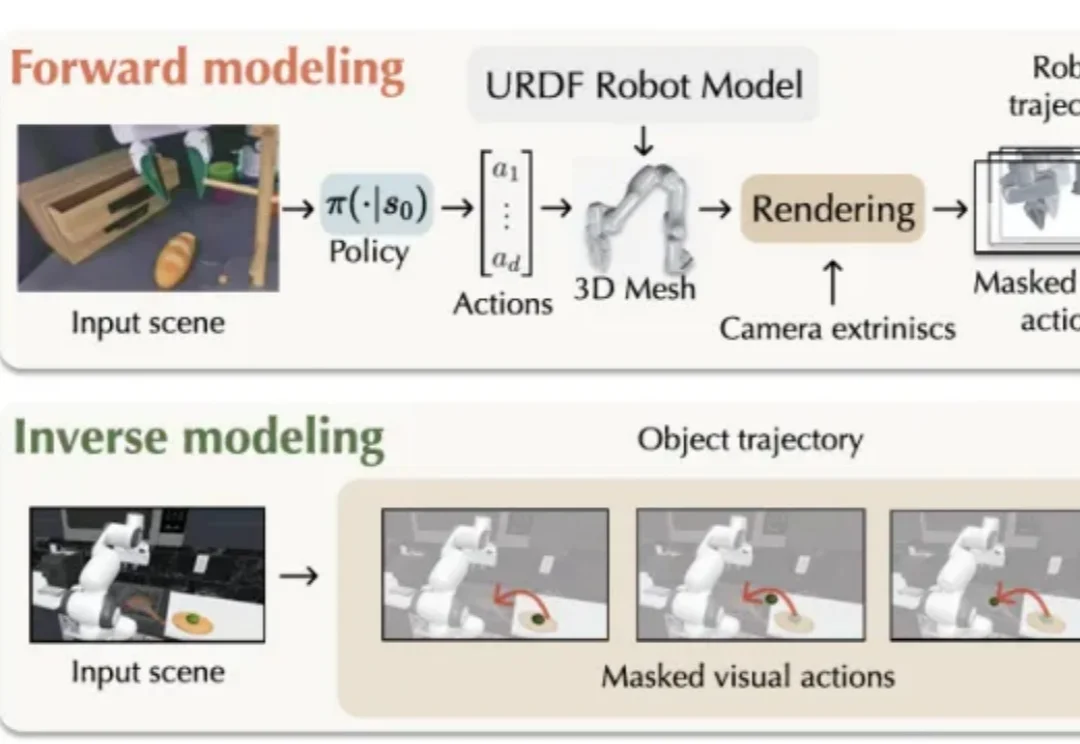
如果要让机械臂把咖啡机旁的杯子移到桌上,需要经历哪几个步骤?
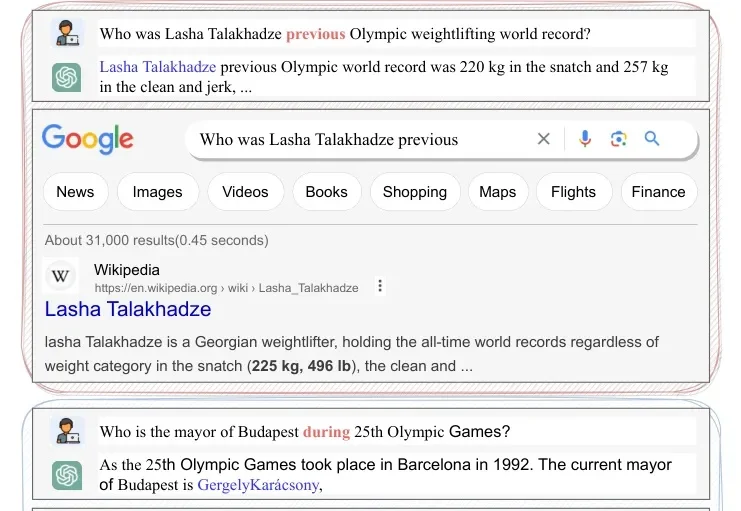
向ChatGPT问一个看起来挺简单的问题:“Lasha Talakhadze之前的奥运举重纪录是多少?”
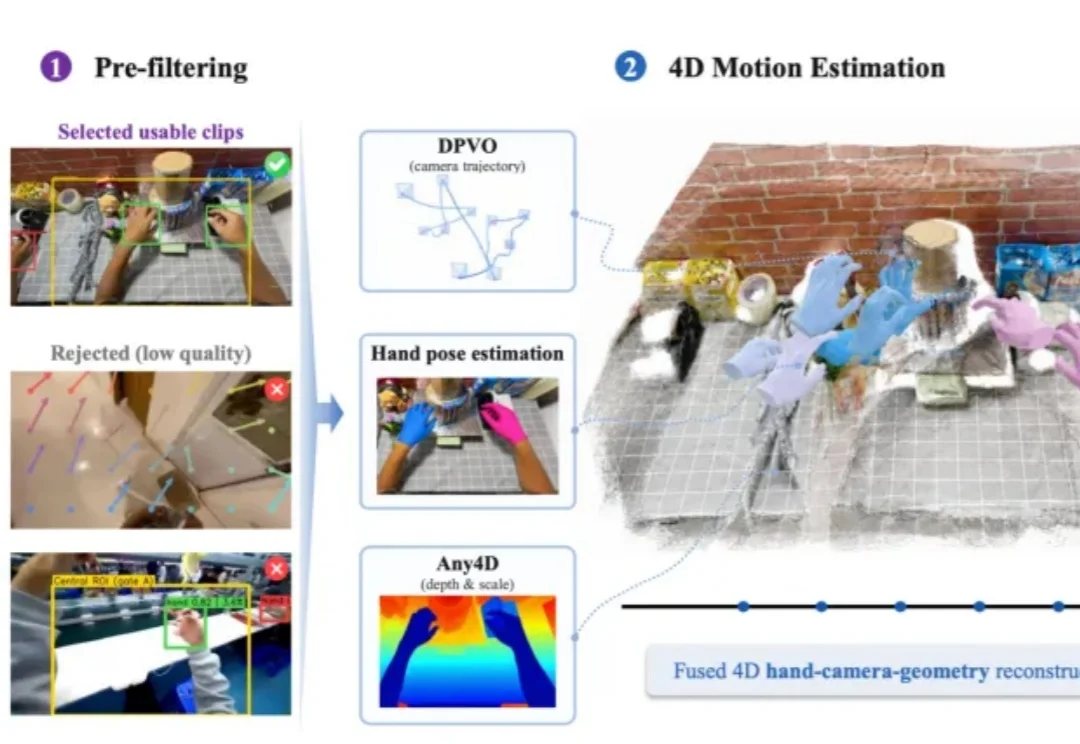
记得何同学做过一个超复杂的流水线项目吗?

逛过WAIC具身智能展区的人,多半有同一个疑问: 都2026年了,机器人干活,怎么还是慢吞吞的?

最新研究发现,AI幻觉不只会骗你了,还能喂大你的自信心、削弱你的判断力。

国防科技大学虚拟现实与视觉计算团队(SAW Lab)联合先进制导与控制技术国家级重点实验室等推出面向航拍几何 3D 视觉的统一大规模数据集与评测基准 「AirZoo」。
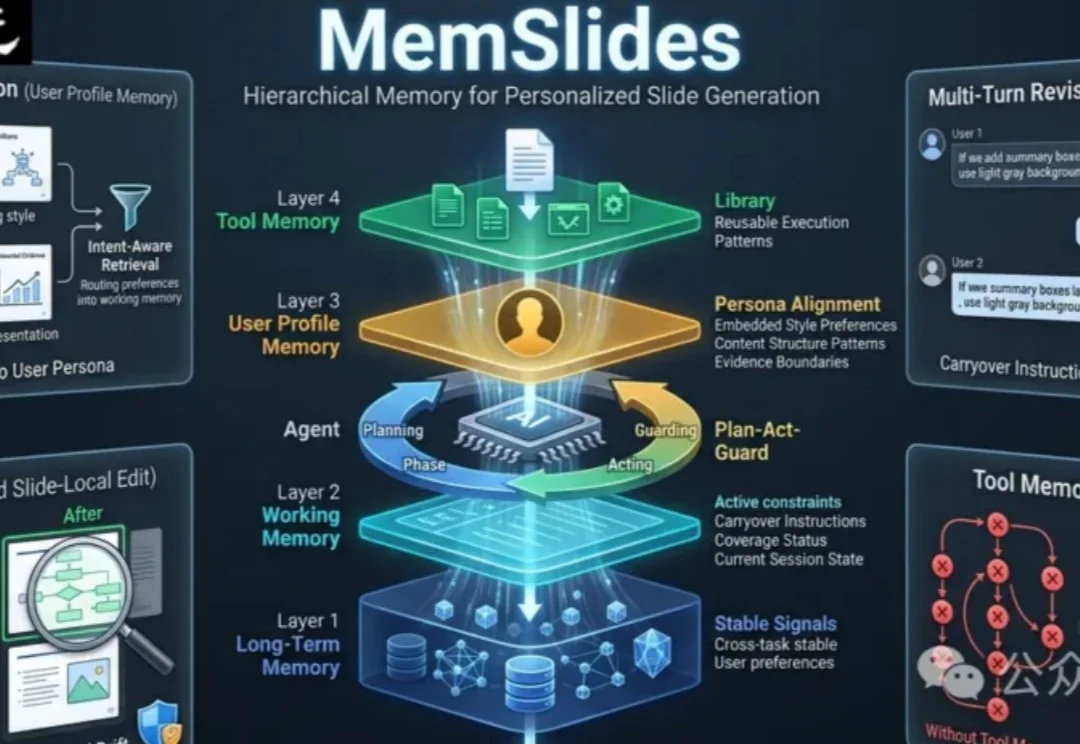
最尴尬的一刻,往往不是AI PPT生成失败。

智能的下一阶段,已从“模型”转向“系统可靠性和进化性”的比拼。

今天,世界模型几乎成为 AI 领域最受关注的话题之一,但对于“什么才是真正的世界模型”却依然存在巨大分歧。有人认为它只是视频生成的延伸,也有人认为只有能够理解物理规律、支持机器人行动的系统才是真正的世界模型。