「你是专家」竟成AI幻觉毒药?新论文一巴掌揭穿提示词最大骗局
「你是专家」竟成AI幻觉毒药?新论文一巴掌揭穿提示词最大骗局AI最强幻觉,原来不是不会,而是太会「装会」。 「你是专家」这句咒语,可能骗了整个AI圈一年。
来自主题: AI技术研报
6854 点击 2026-03-24 10:14
 搜索
搜索
AI最强幻觉,原来不是不会,而是太会「装会」。 「你是专家」这句咒语,可能骗了整个AI圈一年。
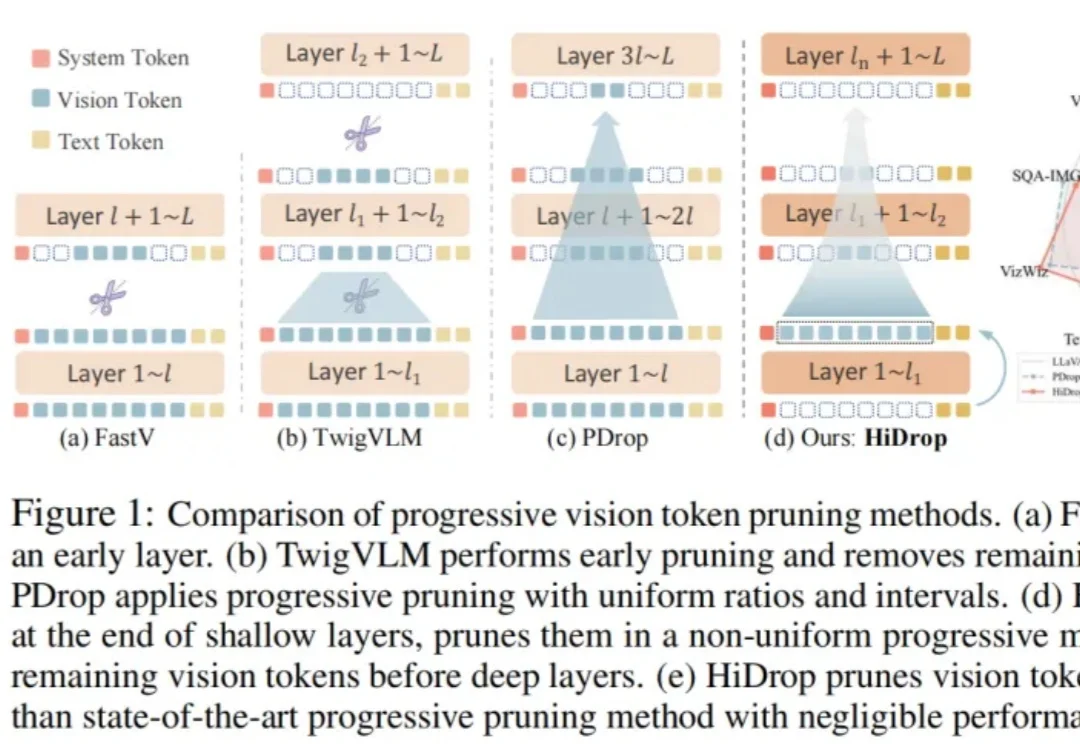
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
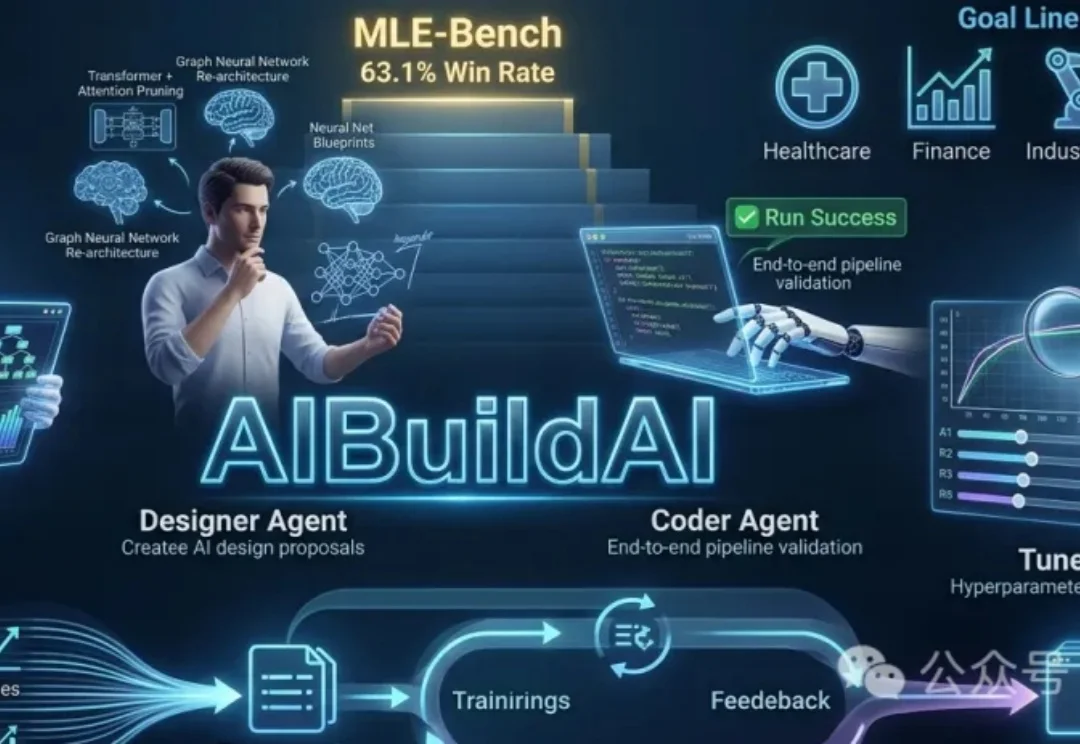
UCSD团队推出AIBuildAI智能体,无需编程,仅用自然语言描述任务,即可自动设计、编码、训练、调参并优化AI模型,分工协作,端到端完成AI开发。在OpenAI MLE-Bench测试中,AIBuildAI以63.1%的获奖率位居第一,性能媲美人类专家,推动AI开发迈向全自动化新时代。
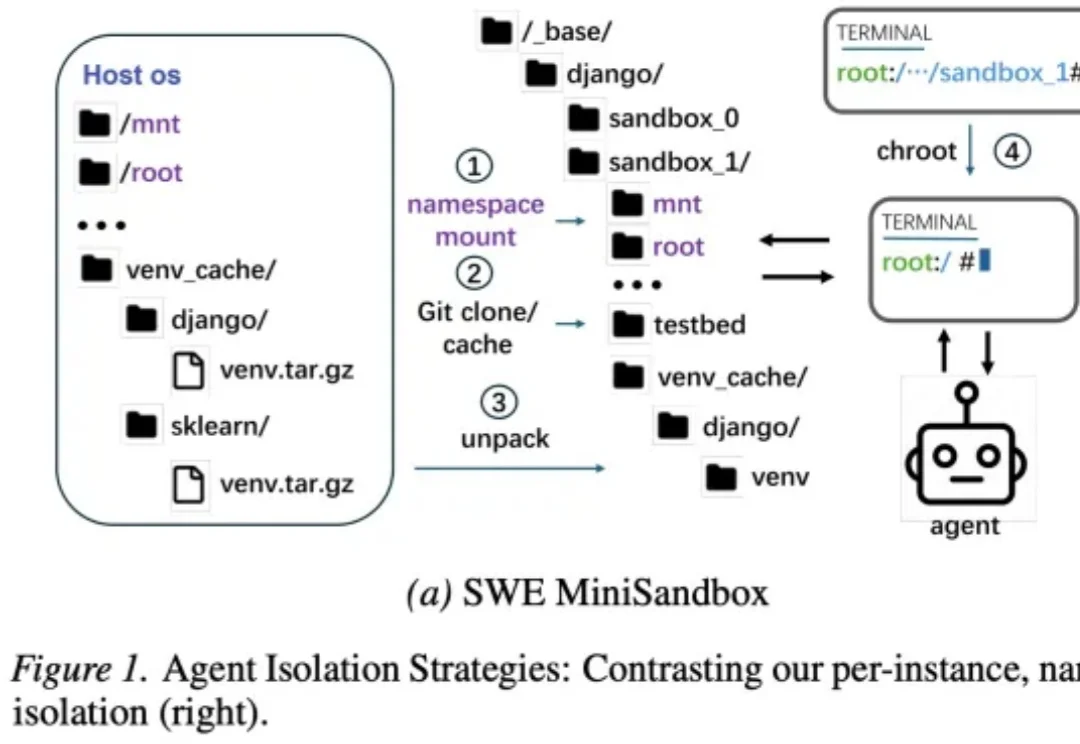
AI 编程这么火,想训练个 SWE Agent 却没有资源怎么办?
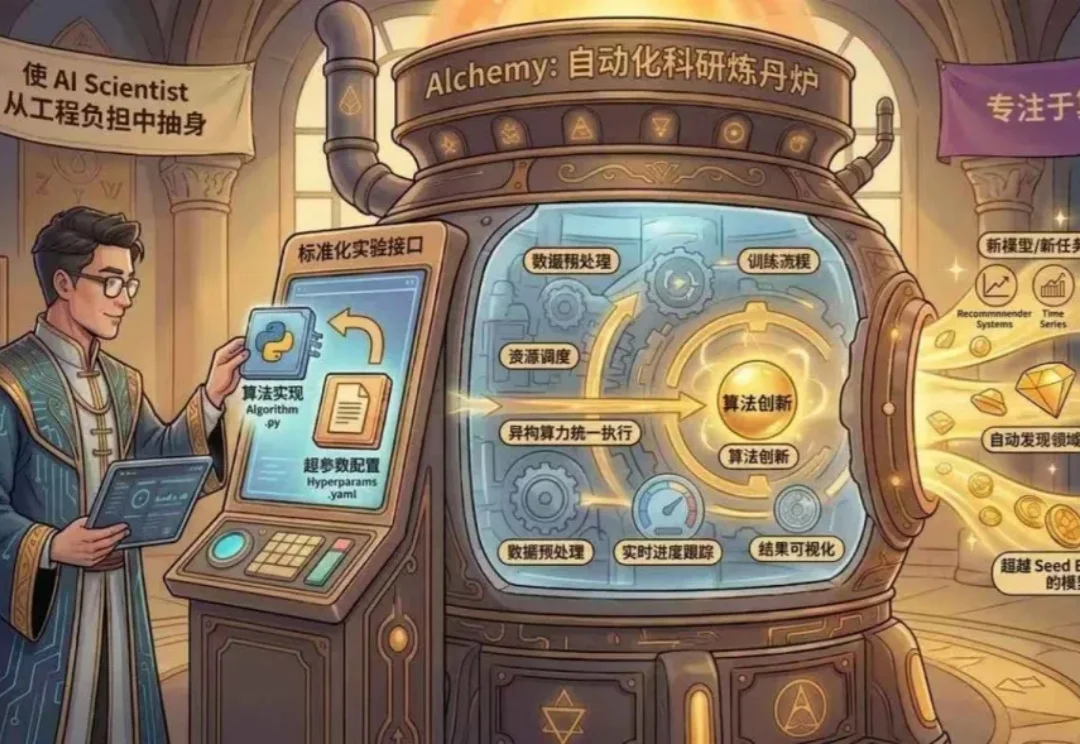
AI 驱动的自动化科研正从概念走向真实系统。近期受到广泛关注的 FARS,以及 Karpathy 开源的 autoresearch,都在不同程度上展示了 AI Scientist 自动进行 AI 领域研究的可行性。

在 AIGC 领域,基于参考图像的图像修复(Reference-based Inpainting)一直是一项备受关注的核心任务,它旨在利用参考图像引导修复过程,生成视觉一致的内容。这一技术在广告营销和电商领域有着巨大的应用潜力,例如让 AI 自动生成 “真人手持或穿戴商品” 的展示图。

一张蓝锥嘴雀的图片,你能认出它是“鸟”,但能认出它是“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”吗?

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大

目前,该论文已录用至 CVPR 2026,相关数据集和模型训练训练和推理代码将逐步开源:究其原因,一个好故事并非一堆漂亮镜头的简单拼接,而是一个有结构、有逻辑的叙事整体。