
世界模型开始做减法?LeCun团队和清华团队给出两种思路
世界模型开始做减法?LeCun团队和清华团队给出两种思路近期,围绕「世界模型」这一方向,有两项工作受到较多关注。
来自主题: AI技术研报
6385 点击 2026-03-25 10:14
 搜索
搜索
近期,围绕「世界模型」这一方向,有两项工作受到较多关注。

OpenClaw 的爆火,不只是因为它能替你干活。

LeCun世界模型最新进展,开源了一套极简训练方案,单GPU就能跑。
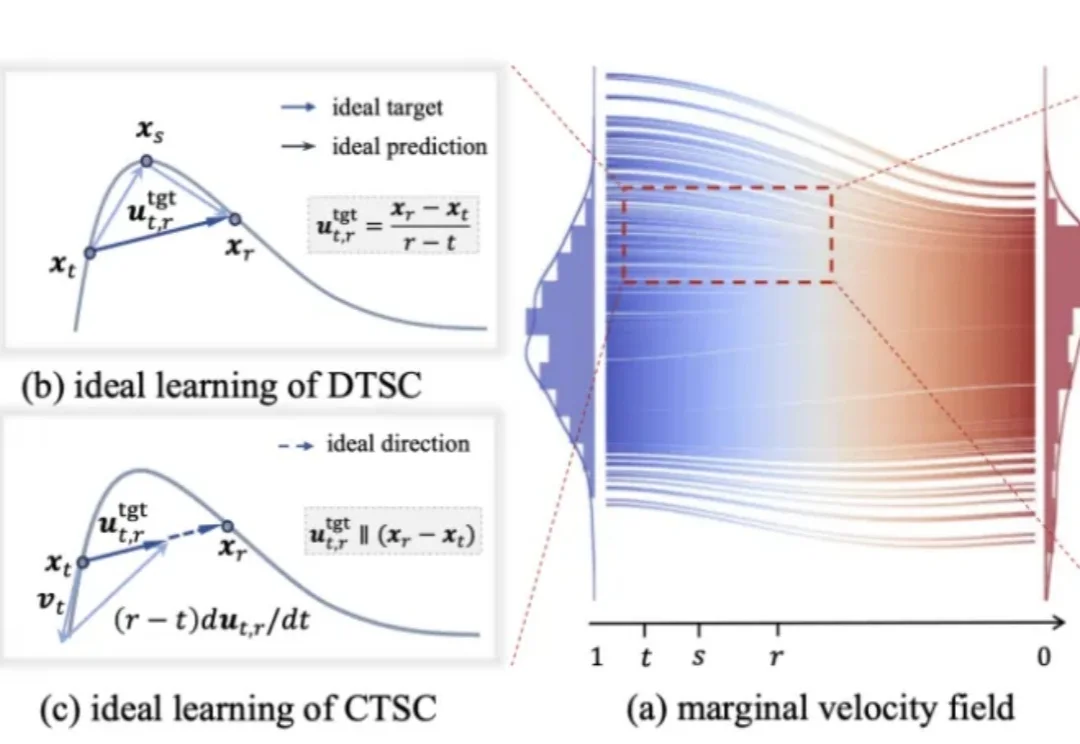
近期,基于捷径化概率流路径(shortcut probability flow trajectory)并从头训练的一步扩散生成模型,展现出强大的实证有效性。然而,这类方法的提出通常建立在较为复杂的理论推导之上,并且往往与具体实现细节高度耦合。这带来一个直接的问题:究竟哪些设计是方法成立的本质要素,哪些又只是可以灵活替换的实现组件。
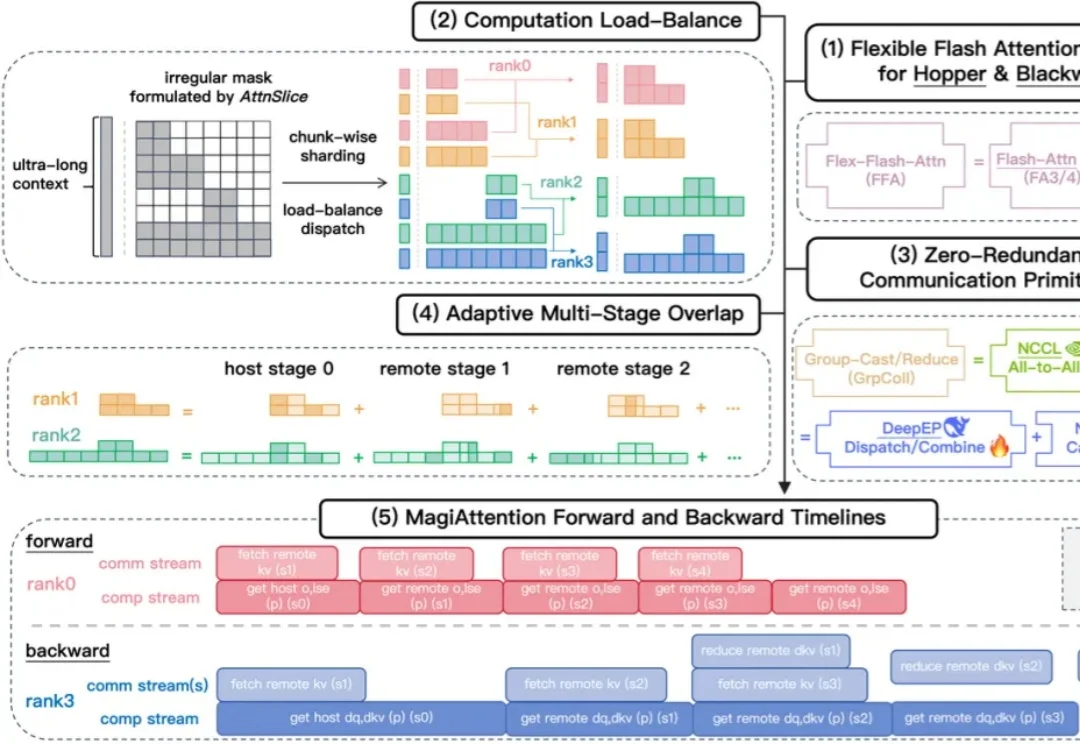
2025 年 4 月,Sand.ai 开源了 MagiAttention v1.0.0,定义了下一代分布式 Attention 的全新设计和系统框架。历经一年的深耕,今天 Sand.ai 正式发布:MagiAttention v1.1.0,以更成熟的原生算子组件,重新定义 Hopper 与 Blackwell 两代架构分布式 Attention 的性能上限。

我们在很多地方都看到了一个词,叫「压缩即智能」

UIUC研究团队打造ResearchArcade,将ArXiv论文、OpenReview评审、图表代码等碎片数据连接成动态知识图谱。模型可直接学习引用关系、修改轨迹与审稿互动,让AI更好辅助科研写作、修订与预测,为下一代科研智能体奠定统一数据基础。
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?

近年来,随着 Sora、Seedance 等文本到视频(T2V)扩散模型的飞速发展,AI 视频生成在视觉保真度与动态表现上已取得突破性进展。特别是近期备受瞩目的 Seedance 2.0,展现出了极其强大的多镜头叙事与复杂分镜控制能力。

您用OpenClaw或CC时有没有这样的感受?Skill越装越多,Agent解决问题的能力却没有越变越强。