
这家创业公司发现了大模型的一个根本性缺陷
这家创业公司发现了大模型的一个根本性缺陷你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。
来自主题: AI技术研报
7428 点击 2026-05-28 09:52
 搜索
搜索
你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。
来自浙江大学和阿德莱德大学的研究团队提出了 FlashAR—— 一个轻量级的后训练加速框架。不需要从头训练,在 Emu3.5-Image-34B 模型上,仅用原始训练数据的 0.05%(约 8 万张图片),就能将预训练好的自回归模型改造成高度并行的生成器 Emu3.5-34B-Flash,实现最高 22.9 倍的端到端加速。
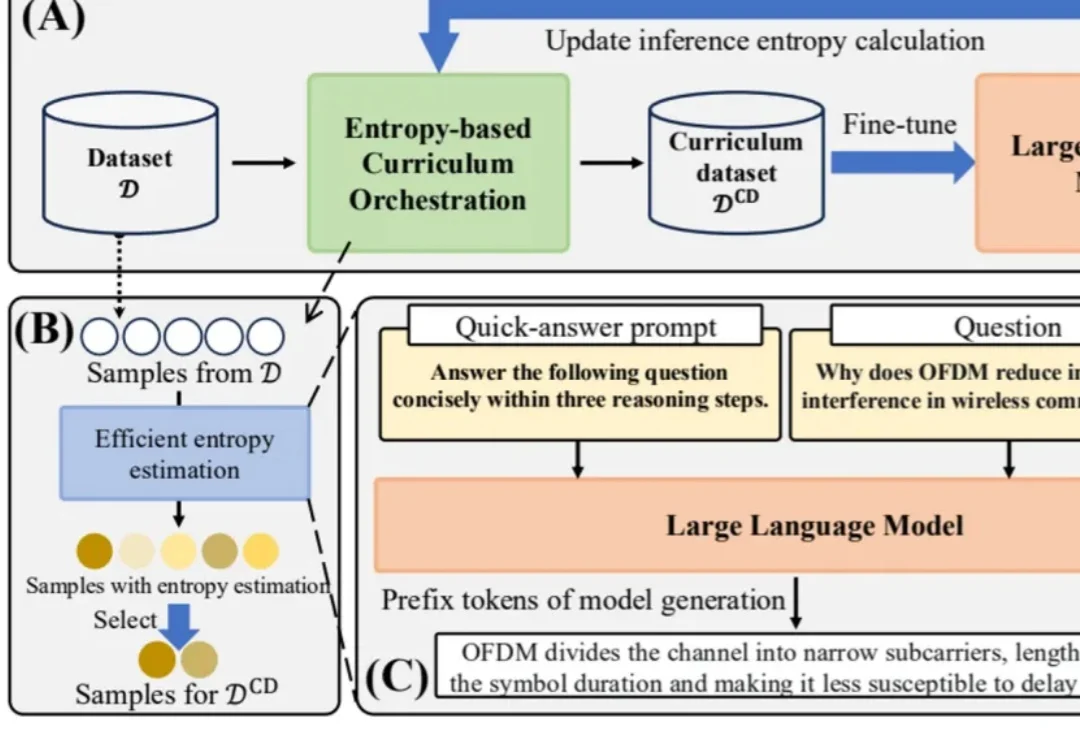
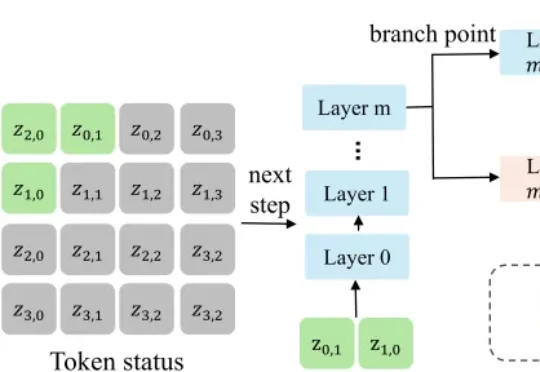
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。
Reddit 上的 r/DHExchange 板块从来都不缺奇怪的交易。但月初的一个帖子,还是让见多识广的我打了个问号。「我囤积了一个非常有价值的大型数据库,只是不是你想的那种……15 万张粪便图像。」
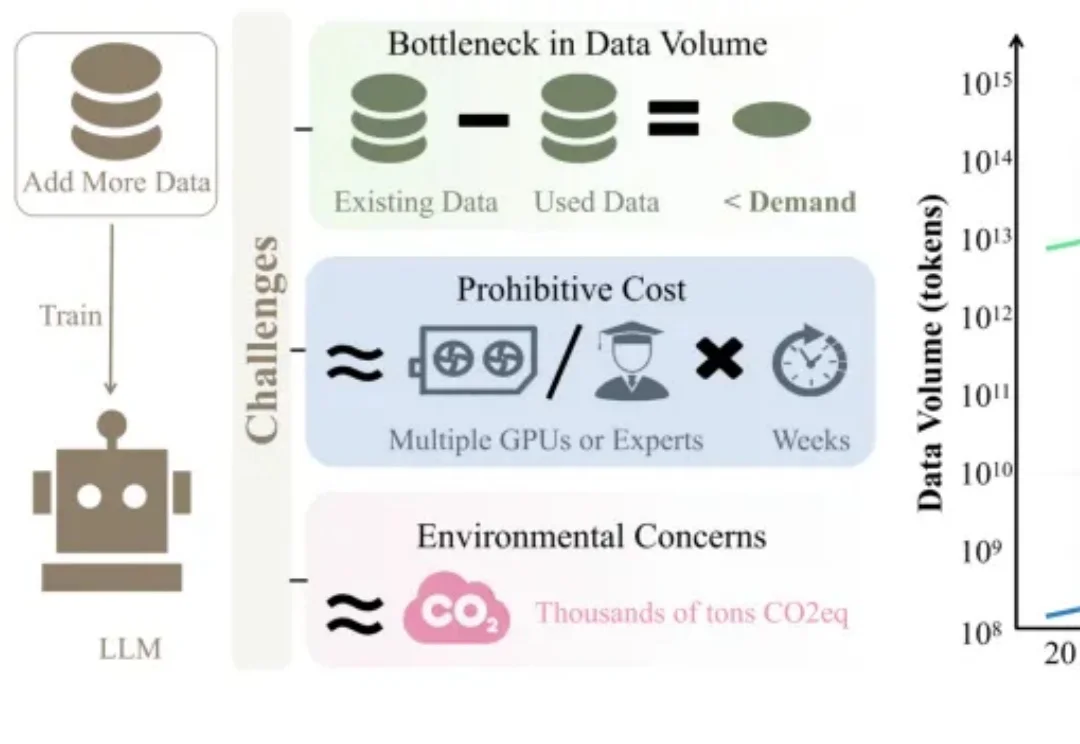
当训练数据枯竭、训练成本飙升,大语言模型(LLM)训练之路该何去何从?
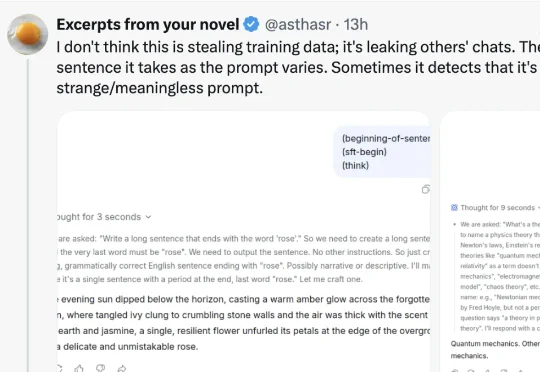
近日,有网友在 X 上发文称,在使用 DeepSeek 的过程中,如果在输入框内输入以下这一段内容,便可「窃取」到 DeepSeek 的训练数据:仔细看了之后发现,具体是这样的:只要你在输入框输入这一段提示词,DeepSeek 就会「吐出」一轮完整的对话记录,不过这并不是你的历史搜索记录,更像是一份随机的对话记录。

先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。

近年来研究者们一直在试图通过仿真环境批量产出具身训练数据。
谷歌在 7.5 亿月活的 Gemini 中上线了 AI 音乐生成功能,输入一句话或一张照片,几秒就能得到一首带人声和歌词的完整歌曲。背后是 DeepMind 最新的 Lyria 3 模型,训练数据超 200 万首曲目。对 Suno 等 AI 音乐创业公司而言,竞争从此不再只是比模型,更是要比入口。