北航推出TinyLLaVA-Video,有限计算资源优于部分7B模型,代码、模型、训练数据全开源
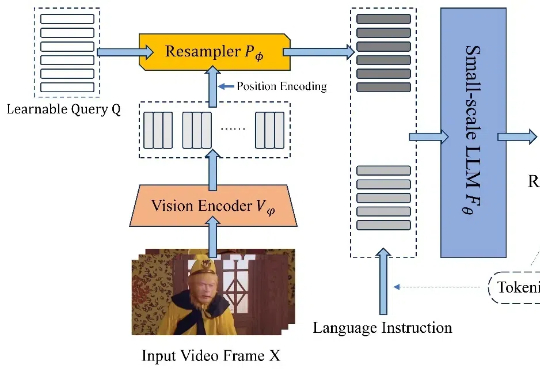
北航推出TinyLLaVA-Video,有限计算资源优于部分7B模型,代码、模型、训练数据全开源近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。
来自主题: AI技术研报
9373 点击 2025-02-10 16:54