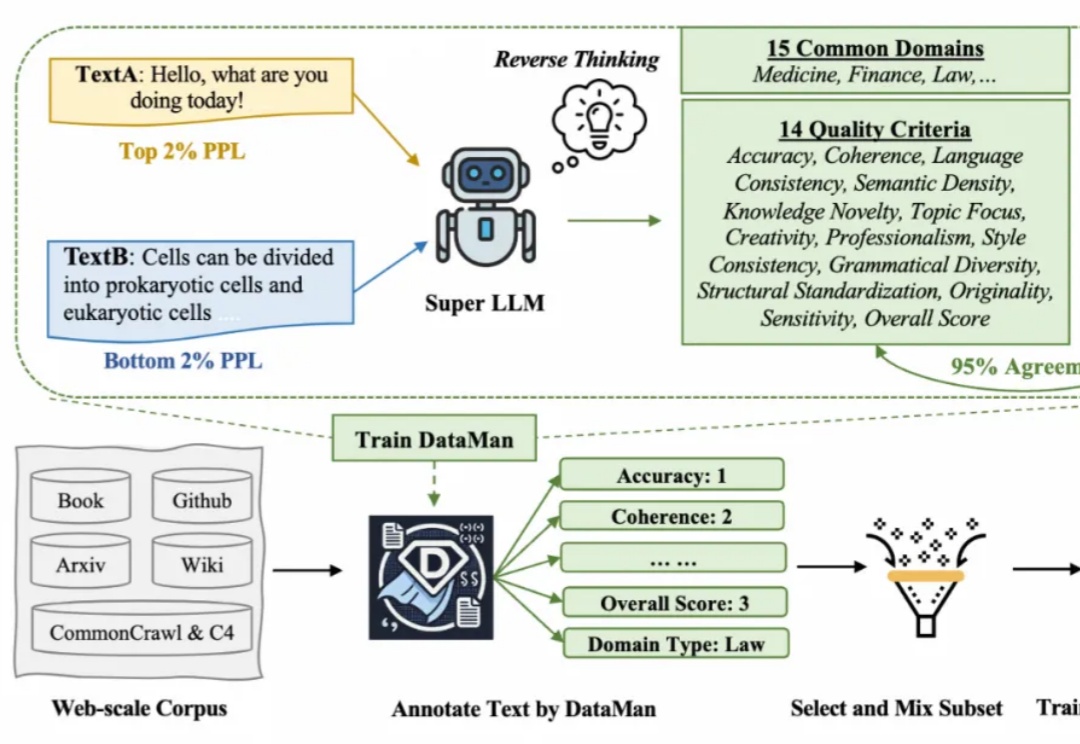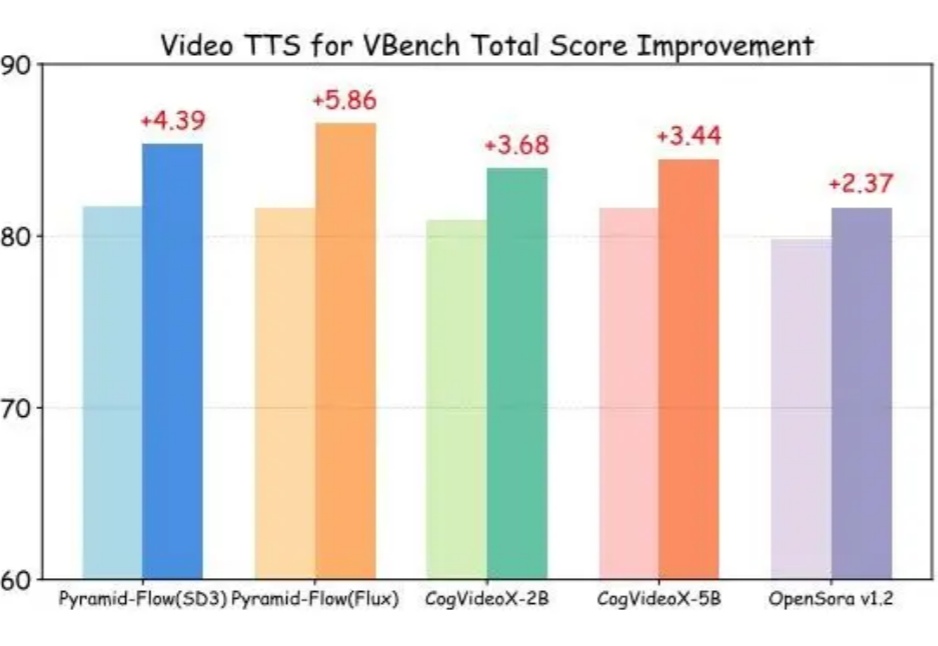
视频生成的测试时Scaling时刻!清华开源Video-T1,无需重新训练让性能飙升
视频生成的测试时Scaling时刻!清华开源Video-T1,无需重新训练让性能飙升视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。
来自主题: AI技术研报
8654 点击 2025-03-26 14:43