

3倍生成速度还降内存成本,超越Medusa2的高效解码框架终于来了
3倍生成速度还降内存成本,超越Medusa2的高效解码框架终于来了传统上,大型语言模型(LLMs)被认为是顺序解码器,逐个解码每个token。
来自主题: AI技术研报
5465 点击 2024-05-10 23:29
传统上,大型语言模型(LLMs)被认为是顺序解码器,逐个解码每个token。

事实是:基于大语言模型的AI应用创业是地狱难度。我认为可能半年内大部分纯做大语言模型应用的AI创业公司都会死掉。

我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。

近年来,大型语言模型(LLM)在数学应用题和数学定理证明等任务中取得了长足的进步。数学推理需要严格的、形式化的多步推理过程,因此是 LLMs 推理能力进步的关键里程碑, 但仍然面临着重要的挑战。

人工智能(AI)工具正在改变科学研究的方式。AlphaFold基本解决了蛋白质结构预测难题;DeepMD大大提高了分子模拟的效率和精度;而新兴的大型语言模型,如ChatGPT等,也正在科学研究领域开疆拓土。
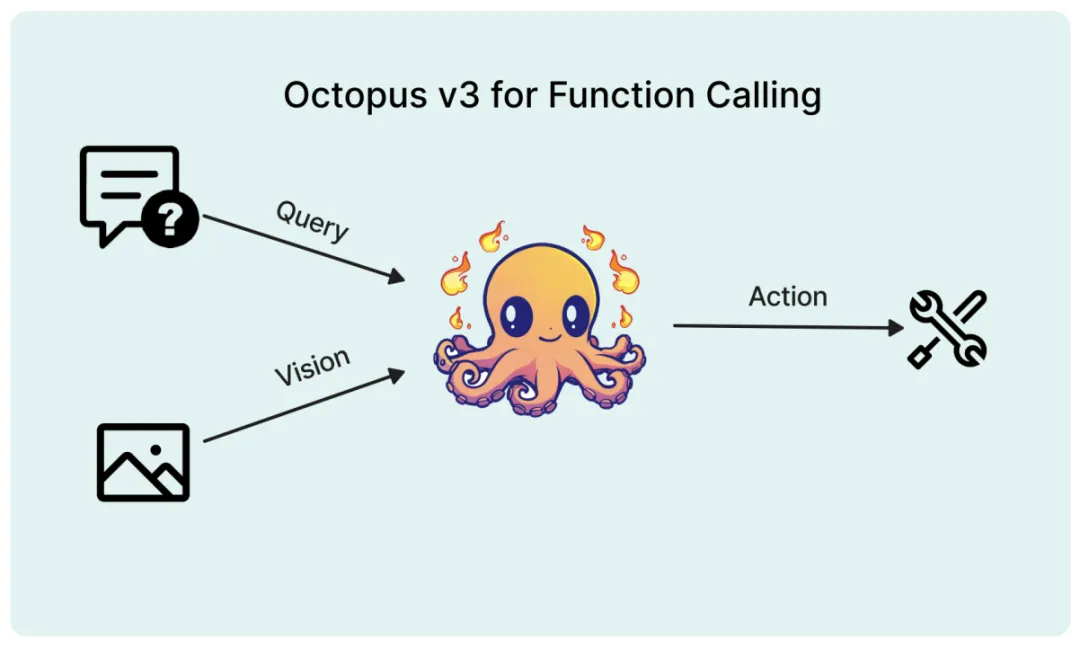
多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型 (如 GPT-4V) 的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行动作仍面临挑战。
在大语言模型领域,微调是改进模型的重要步骤。伴随开源模型数量日益增多,针对LLM的微调方法同样在推陈出新。

对于小型语言模型(SLM)来说,数学应用题求解是一项很复杂的任务。

大型语言模型(LLM)往往会追求更长的「上下文窗口」,但由于微调成本高、长文本稀缺以及新token位置引入的灾难值(catastrophic values)等问题,目前模型的上下文窗口大多不超过128k个token

近期,大语言模型、文生图模型等大规模 AI 模型迅猛发展。在这种形势下,如何适应瞬息万变的需求,快速适配大模型至各类下游任务,成为了一个重要的挑战。受限于计算资源,传统的全参数微调方法可能会显得力不从心,因此需要探索更高效的微调策略。