CVPR 2026 | 视觉脑机迈向双向交互!神经流模型 NeuroFlow 打通视觉与神经的双向通道
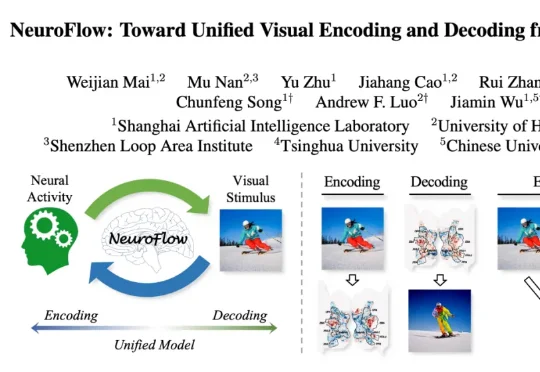
CVPR 2026 | 视觉脑机迈向双向交互!神经流模型 NeuroFlow 打通视觉与神经的双向通道来自上海人工智能实验室、香港大学、香港中文大学等机构的研究团队,提出首个基于统一神经流模型的视觉-神经双向建模框架NeuroFlow,相关成果入选 CVPR 2026。它首次将视觉编码(写脑)与解码(读脑)整合到同一可逆流结构中,打通视觉感知与神经活动之间的双向通路,为理解人类视觉认知机制、构建下一代通用视觉假体与双向脑机接口提供了全新范式。
来自主题: AI技术研报
8164 点击 2026-06-13 10:12