
刚刚,Kimi开源新架构,开始押注线性注意力
刚刚,Kimi开源新架构,开始押注线性注意力月之暗面在这一方向有所突破。在一篇新的技术报告中,他们提出了一种新的混合线性注意力架构 ——Kimi Linear。该架构在各种场景中都优于传统的全注意力方法,包括短文本、长文本以及强化学习的 scaling 机制。
来自主题: AI技术研报
8405 点击 2025-10-31 14:33
 搜索
搜索
月之暗面在这一方向有所突破。在一篇新的技术报告中,他们提出了一种新的混合线性注意力架构 ——Kimi Linear。该架构在各种场景中都优于传统的全注意力方法,包括短文本、长文本以及强化学习的 scaling 机制。
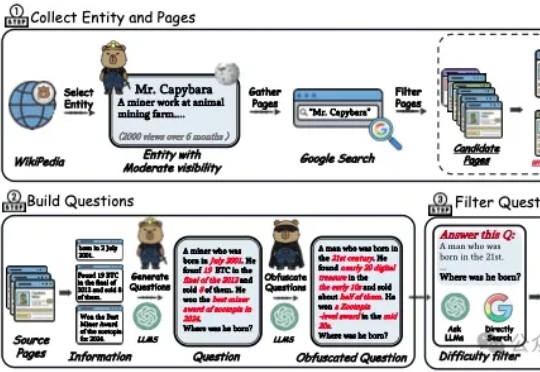
中科院的这篇工作解决了“深度搜索智能体”(deep search agents),两个实打实的工程痛点,一个是问题本身不够难导致模型不必真正思考,另一个是上下文被工具长文本迅速挤爆导致过程提前夭折,研究者直面挑战,从数据和系统两端同时重塑训练与推理流程,让复杂推理既有用又能跑得起来。
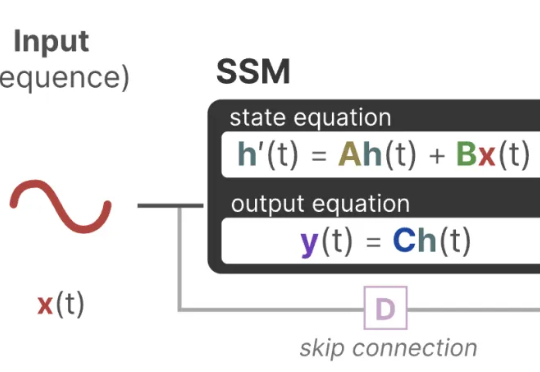
曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。

InfLLM-V2是一种可高效处理长文本的稀疏注意力模型,仅需少量长文本数据即可训练,且性能接近传统稠密模型。通过动态切换短长文本处理模式,显著提升长上下文任务的效率与质量。从短到长低成本「无缝切换」,预填充与解码双阶段加速,释放长上下文的真正生产力。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。

昨晚凌晨,通义千问团队宣布,已对其旗舰模型 Qwen3 进行升级,并推出非思考模式(Non-thinking)的更新版本:Qwen3-235B-A22B-Instruct-2507-FP8。此次更新旨在提升模型的综合能力
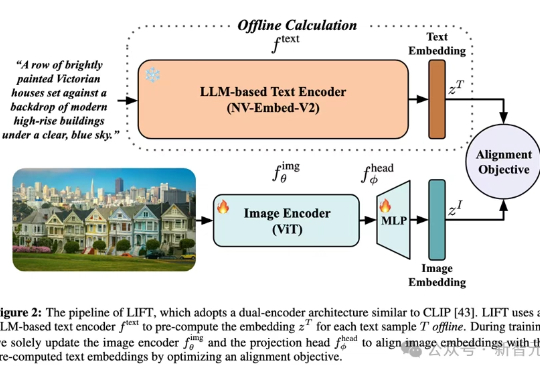
多模态对齐模型借助对比学习在检索与生成任务中大放异彩。最新趋势是用冻结的大语言模型替换自训文本编码器,从而在长文本与大数据场景中降低算力成本。LIFT首次系统性地剖析了此范式的优势来源、数据适配性、以及关键设计选择,在组合语义理解与长文本任务上观察到大幅提升。
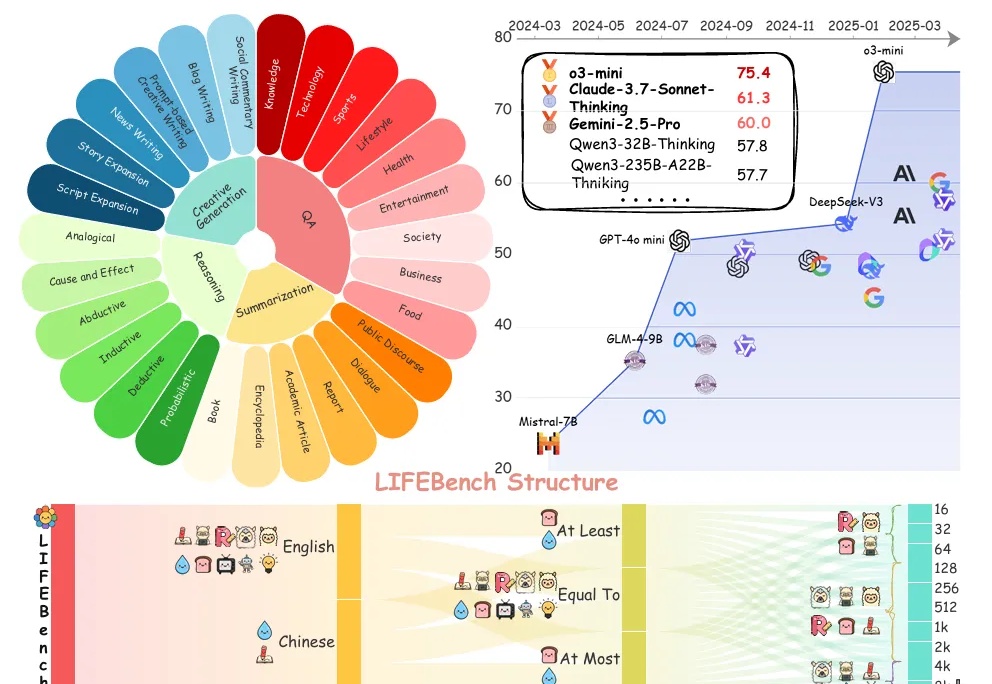
你是否曾对大语言模型(LLMs)下达过明确的“长度指令”?
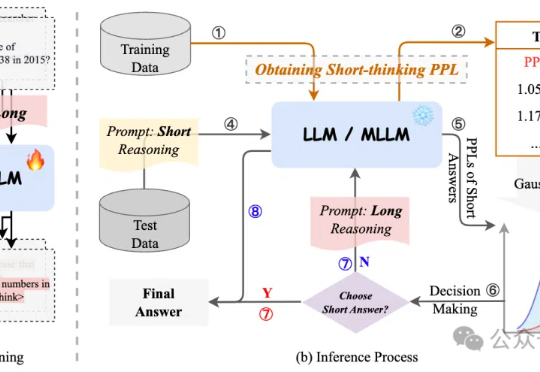
过度依赖CoT思维链推理会降低模型性能,有新解了! 来自字节、复旦大学的研究人员提出自适应推理框架CAR,能根据模型困惑度动态选择短回答或详细的长文本推理,最终实现了准确性与效率的最佳平衡。
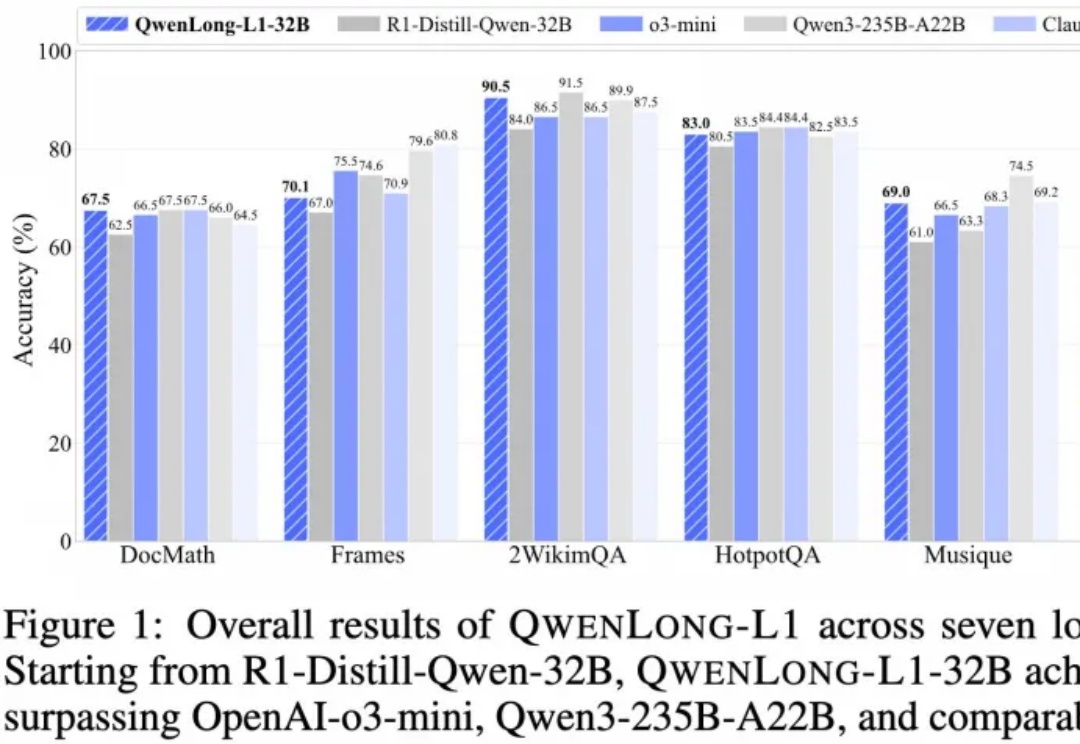
推理大模型开卷新方向,阿里开源长文本深度思考模型QwenLong-L1,登上HuggingFace今日热门论文第二。