DeepSeek-OCR是「长文本理解」未来方向?中科院新基准VTCBench给出答案
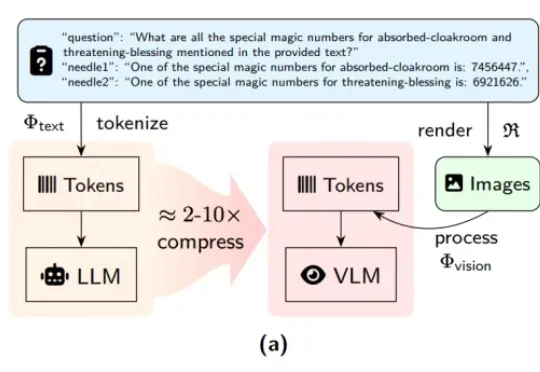
DeepSeek-OCR是「长文本理解」未来方向?中科院新基准VTCBench给出答案近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。
来自主题: AI技术研报
8389 点击 2026-01-11 10:01