
Meta公开抄阿里Qwen作业,还闭源了...
Meta公开抄阿里Qwen作业,还闭源了...Meta的开源时代,要结束了。彭博社爆料,明年春季,Meta将发布一款代号为「Avocado(牛油果)」的模型。而这款新模型,很可能是「闭源」的。但如果仅仅是闭源,还不至于如此引人注目。真正让市场炸裂的是另一条更劲爆的消息:这款闭源模型,竟然在训练过程中使用了阿里巴巴的AI。
来自主题: AI资讯
8672 点击 2025-12-11 11:55
 搜索
搜索
Meta的开源时代,要结束了。彭博社爆料,明年春季,Meta将发布一款代号为「Avocado(牛油果)」的模型。而这款新模型,很可能是「闭源」的。但如果仅仅是闭源,还不至于如此引人注目。真正让市场炸裂的是另一条更劲爆的消息:这款闭源模型,竟然在训练过程中使用了阿里巴巴的AI。

刚刚,这样一个消息在 Reddit 上引发热议:硅谷似乎正在从昂贵的闭源模型转向更便宜的开放源替代方案。

10 月 23 日,一向不爱出风头的夸克上线了对话助手,可以让用户在一个 App 内即可完成信息查找、问题解答与任务处理,实现了 AI 搜索与对话的深度融合。其中一大亮点就是,该对话助手采用了 Qwen 最新闭源模型。至于是哪个型号、性能有多强,夸克卖了个关子,只透露比 Qwen3-Max 更进一步,在业界有绝对领先性。

LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。

游戏理解领域模型LynkSoul VLM v1,在游戏场景中表现显著超过了包括GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash等一众顶尖闭源模型。背后厂商逗逗AI,亦在现场吸引了不少关注的目光。
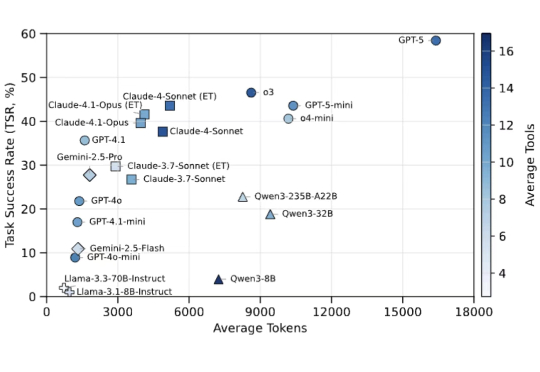
杜克大学与 Zoom 的研究者们推出了 LiveMCP-101,这是首个专门针对真实动态环境设计的 MCP-enabled Agent 评测基准。该基准包含 101 个精心设计的任务,涵盖旅行规划,体育娱乐,软件工程等多种不同场景,要求 Agent 在多步骤、多工具协同的场景下完成任务。
Meta在半年内第四次重组AI部门,将超级智能实验室拆分为四个团队,全面押注「超级智能」。新成立的TBD Lab由Alexandr Wang领衔,或放弃Llama 4并转向闭源模型,Meta开源旗帜动摇。Meta内部人心浮动,几家欢喜几家愁。
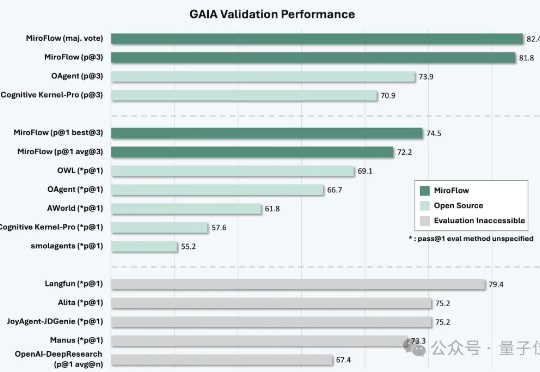
最强开源深度研究模型来了。 MiroMind ODR(Open Deep Research),来自代季峰加盟陈天桥的技术首秀。 首先,它做到了性能最强,GAIA测试结果更是达到了82.4分,超过了一众开源闭源模型,其中包括Manus、OpenAI的DeepResearch。

擅长「种草」的小红书正加大技术自研力度,两个月内接连开源三款模型!最新开源的首个多模态大模型dots.vlm1,基于自研视觉编码器构建,实测看穿色盲图,破解数独,解高考数学题,一句话写李白诗风,视觉理解和推理能力都逼近Gemini 2.5 Pro闭源模型。
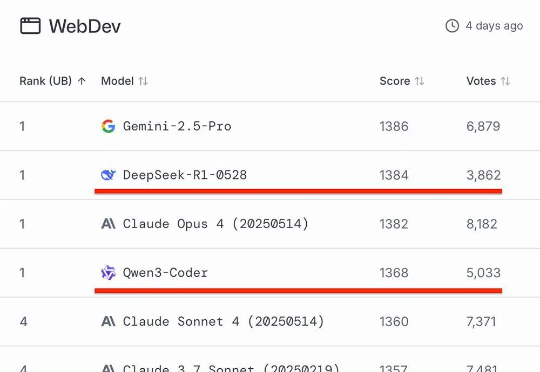
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。