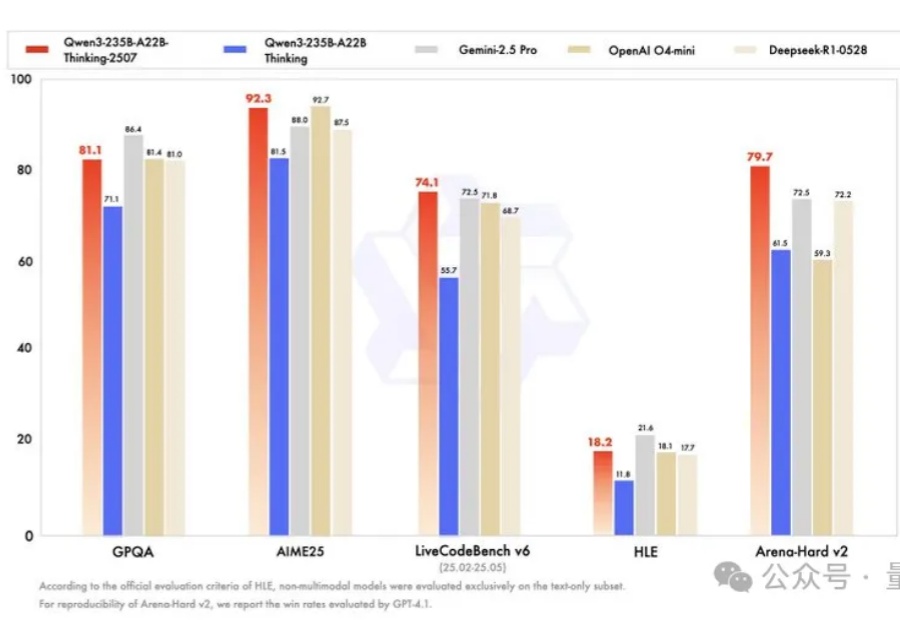
开源Qwen一周连刷三冠,暴击闭源模型!基础模型推理编程均SOTA
开源Qwen一周连刷三冠,暴击闭源模型!基础模型推理编程均SOTA卷疯了,通义千问真的卷疯了。
来自主题: AI技术研报
11024 点击 2025-07-28 10:21
 搜索
搜索
卷疯了,通义千问真的卷疯了。

3D生成模型高光时刻来临!DreamTech联手南大、复旦、牛津发布的Direct3D-S2登顶HuggingFace热榜。仅用8块GPU训练,效果超闭源模型,直指影视级精细度。

3 月 28 日,专注于构建通用 3D 大模型的 VAST 一口气开源了两个 3D 生成项目 ——TripoSG 和 TripoSF。前者是一款基础 3D 生成模型,在图像到 3D 生成任务上远超所有闭源模型;后者则是 VAST 新一代三维基础模型 TripoSF 能在所有闭源模型中同样取得 SOTA 的基础组件,用于高分辨率的三维重建和生成任务。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

大家可能看到过很多类似的结论:针对特定任务,对开源模型进行 LoRA 微调可以干翻 GPT-4 这类闭源模型。
Allen Institute for AI(AI2)发布了Tülu 3系列模型,一套开源的最先进的语言模型,性能与GPT-4o-mini等闭源模型相媲美。Tülu 3包括数据、代码、训练配方和评估框架,旨在推动开源模型后训练技术的发展。
简单性可以扩展:PyTorch的成功源于其对研究人员简单性的关注,这种关注随后流向了生产环境。在Fireworks,他们在幕后拥抱了巨大的复杂性,以提供一个简单的API给开发者。这种方法让客户能够专注于创新和产品设计,而不是纠结于技术复杂性。
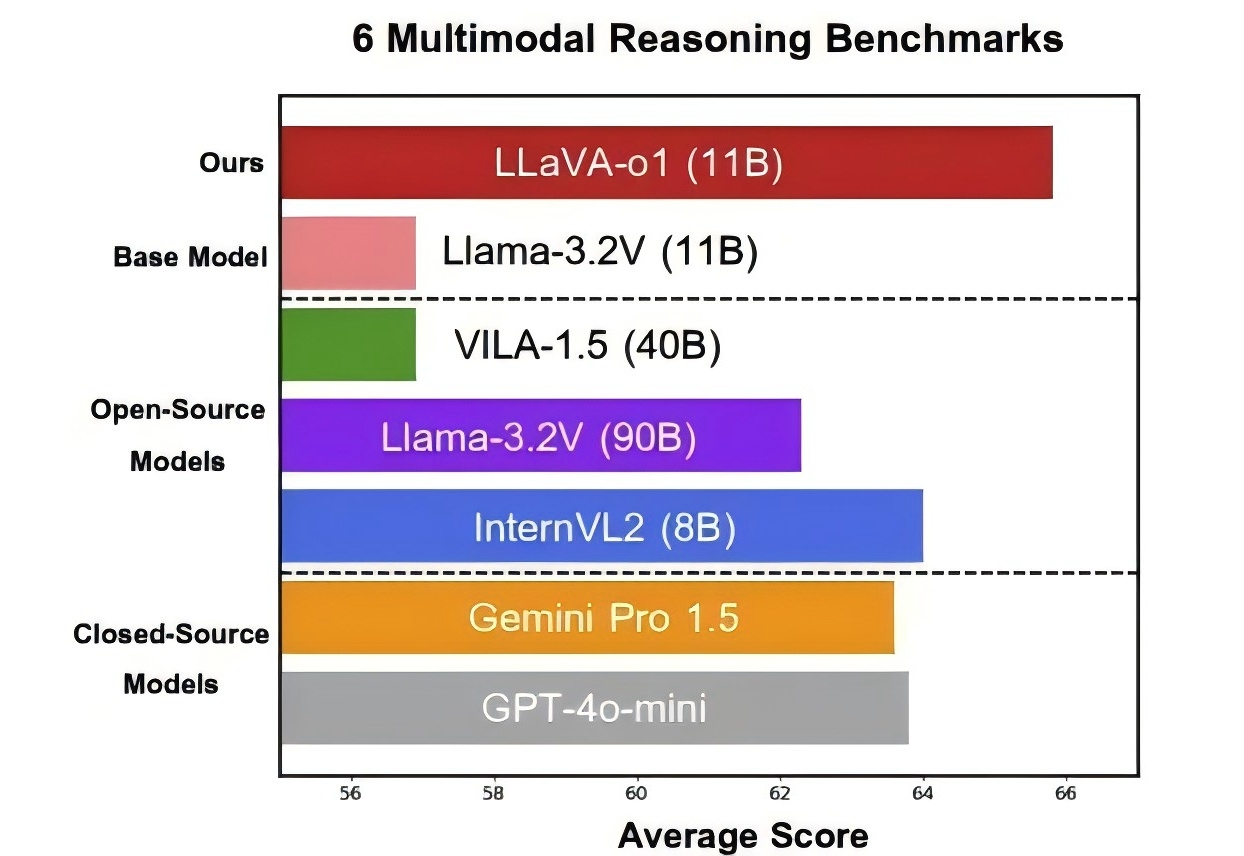
北大等出品,首个多模态版o1开源模型来了—— 代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。 在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。

与最先进的开源方法甚至闭源模型 GPT-4o 相比,MMedAgent 在各种医疗任务中实现了卓越的性能。此外,MMedAgent 在更新和集成新医疗工具方面表现出效率。