

Mira翁荔陈丹琦公司,让老黄掏出了600亿美金
Mira翁荔陈丹琦公司,让老黄掏出了600亿美金又给算力又投资,英伟达又有一大笔资源砸向了Mira的初创公司。
来自主题: AI资讯
9278 点击 2026-03-11 16:58
又给算力又投资,英伟达又有一大笔资源砸向了Mira的初创公司。
陈丹琦首次转身工业界,第一站就选择Mira初创的理由找到了—— 有个赛友也在这儿,还足足“潜伏”了一年之久。
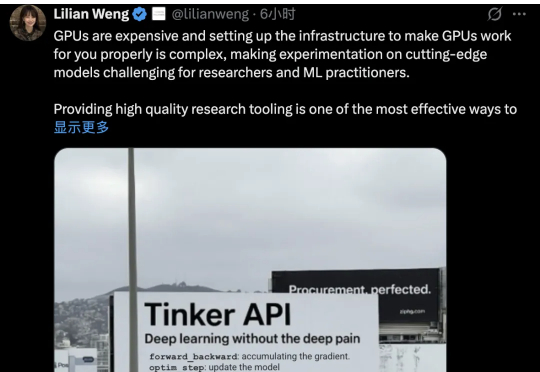
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。也算是终于摘掉了“0产品0收入估值840亿”的帽子。Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在“抽象化和可调性之间取得了卓越的平衡”

结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。

一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。
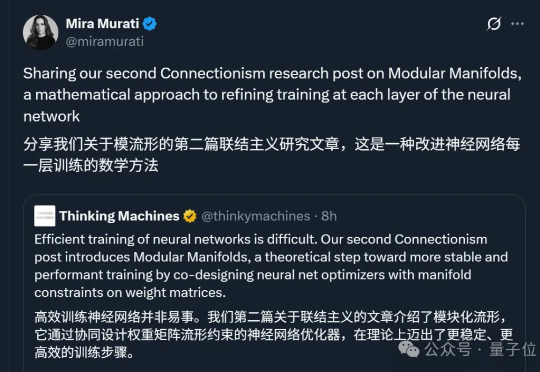
明星创业公司Thinking Machines,第二篇研究论文热乎出炉!公司创始人、OpenAI前CTO Mira Murati依旧亲自站台,翁荔等一众大佬也纷纷转发支持:论文主题为“Modular Manifolds”,通过让整个网络的不同层/模块在统一框架下进行约束和优化,来提升训练的稳定性和效率。
又一个AI学术大佬,有工业界身份了。 清华姚班校友、普林斯顿教授陈丹琦,跟Thinking Machines划上了关联。
陈丹琦加入 Thinking Machines Lab 了?这一猜测不是毫无根据,当我们打开她的 GitHub 主页,邮箱已经变为 thinkingmachines.ai。
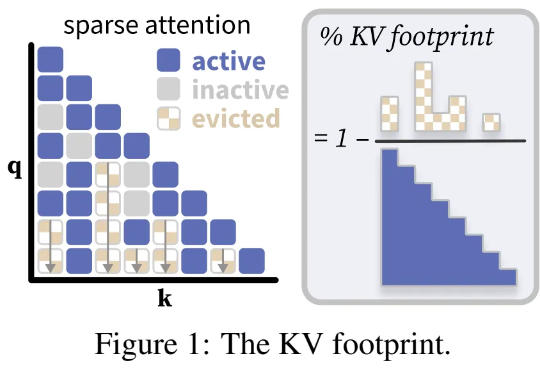
普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文了。近期,诸如「长思维链」等技术的兴起,带来了需要模型生成数万个 token 的全新工作负载。

很多大模型的官方参数都声称自己可以输出长达32K tokens的内容,但这数字实际上是存在水分的??