

万卡集群要上天?中国硬核企业打造太空超算!
万卡集群要上天?中国硬核企业打造太空超算!地面上的算力“内卷”,终于突破了大气层的束缚。前脚,装有英伟达H100的Starcloud-1卫星搭乘SpaceX的猎鹰9号火箭成功进入轨道,迈出构建“太空超算”的关键一步。谷歌紧随其后,火速披露了部署搭载TPU卫星集群的“太阳捕手”计划(Project Suncatcher)。
来自主题: AI资讯
8769 点击 2025-11-29 10:02
地面上的算力“内卷”,终于突破了大气层的束缚。前脚,装有英伟达H100的Starcloud-1卫星搭乘SpaceX的猎鹰9号火箭成功进入轨道,迈出构建“太空超算”的关键一步。谷歌紧随其后,火速披露了部署搭载TPU卫星集群的“太阳捕手”计划(Project Suncatcher)。

新的资金和算力基础设施将加速 Luma AI 通往多模态 AGI 的路径 —— 即能够模拟现实并在物理世界中帮助人类的 AI。

华为公司董事、ICT BG CEO 杨超斌在致辞中表示,AI 技术正以前所未有的速度改变各行各业,传统服务器集群无法有效满足算力不断增长的诉求。华为已经开放灵衢互联协议 2.0,支持产业界伙伴打造基于灵衢的超节点,还将向开源欧拉社区贡献支持超节点的操作系统插件代码,提供「内存统一编址」

目标2030年百万卡集群点亮。

两人小团队,仅用两周就复刻了之前被硅谷夸疯的DeepSeek-OCR?? 复刻版名叫DeepOCR,还原了原版低token高压缩的核心优势,还在关键任务上追上了原版的表现。完全开源,而且无需依赖大规模的算力集群,在两张H200上就能完成训练。

甲骨文于上周发布全球最大云端AI超级计算机「OCI Zettascale10」,由80万块NVIDIA GPU组成,峰值算力高达16 ZettaFLOPS,成为OpenAI「星际之门」集群的算力核心。其独创Acceleron RoCE网络实现GPU间高效互联,显著提升性能与能效。该系统象征甲骨文在AI基础设施竞争中的强势布局。

AMD再下一城!Oracle宣布自2026年第三季度起,将在其云基础设施(OCI)部署5万颗AMD Instinct™ MI450系列GPU,构建全新AI超级集群,并计划持续扩容。此举标志着AMD与Oracle的合作迈入新阶段,也被视为AMD在打破英伟达长期主导的AI算力生态中的又一关键突破。
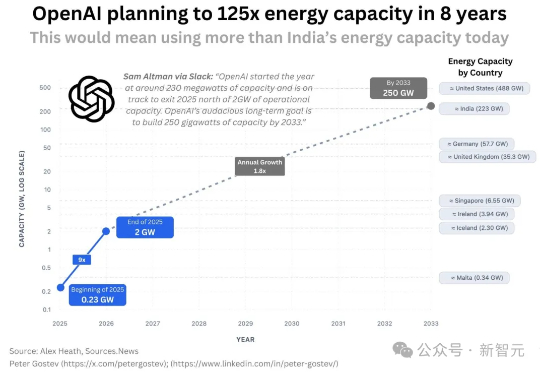
OpenAI宣布与AMD达成战略合作,将共同部署高达6GW的AMD Instinct MI450 GPU集群,首批1GW预计于2026年下半年启用。作为协议的一部分,OpenAI可认购最多1.6亿股AMD普通股,持股比例或达10%。消息公布后,AMD盘前股价飙升35%!

人工996,智能体就能做了!刚刚,「基础设施智能体蜂群」正式诞生,多智能体系统,打造感知-决策-执行闭环,彻底颠覆传统运维模式。从此,智能体专业团队加持,集群排障效率起飞。
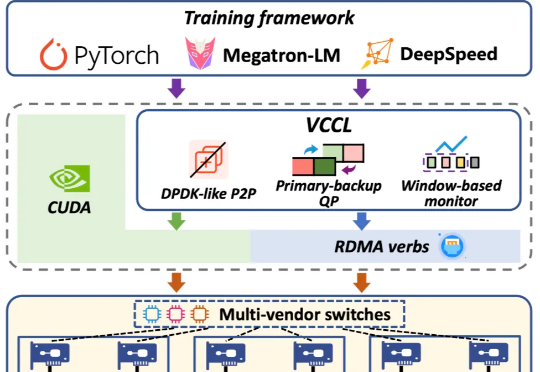
创智、基流、智谱、联通、北航、清华、东南联合打造了高效率、高可靠、高可视的 GPU 集合通信库 VCCL(Venus Collective Communication Library),VCCL 已部署于多个生产环境集群中。