
陈丹琦团队降本大法又来了:数据砍掉三分之一,性能却完全不减
陈丹琦团队降本大法又来了:数据砍掉三分之一,性能却完全不减陈丹琦团队又带着他们的降本大法来了—— 数据砍掉三分之一,大模型性能却完全不减。 他们引入了元数据,加速了大模型预训练的同时,也不增加单独的计算开销。
来自主题: AI资讯
8659 点击 2025-01-08 09:56
 搜索
搜索
陈丹琦团队又带着他们的降本大法来了—— 数据砍掉三分之一,大模型性能却完全不减。 他们引入了元数据,加速了大模型预训练的同时,也不增加单独的计算开销。
智能涌现独家获悉:零一万物裁撤预训练算法团队和Infra团队后,阿里通义、智能云团队给出了offer。
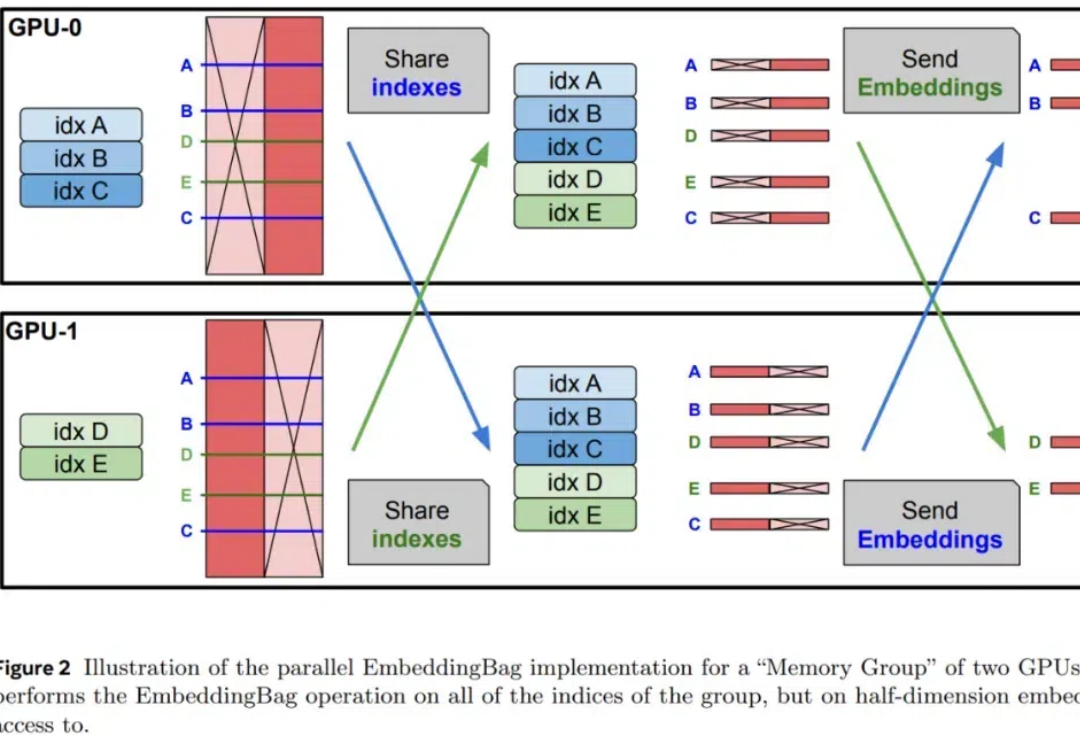
预训练语言模型通常在其参数中编码大量信息,并且随着规模的增加,它们可以更准确地回忆和使用这些信息。

过去一段时间,“预训练终结”成为了 AI 领域最热烈的讨论之一。OpenAI的GPT系列模型此前大踏步的前进,预训练是核心推动力。而前 OpenAI 首席科学家 Ilya Sutskever、预训练和scaling law(规模定律)最忠实的倡导者,却宣称预训练要终结了、scaling law要失效。由此,引发了大量争议。

在 2024 年的 NeurIPS 会议上,Ilya Sutskever 提出了一系列关于人工智能发展的挑战性观点,尤其集中于 Scaling Law 的观点:「现有的预训练方法将会结束」,这不仅是一次技术的自然演进,也可能标志着对当前「大力出奇迹」方法的根本性质疑。
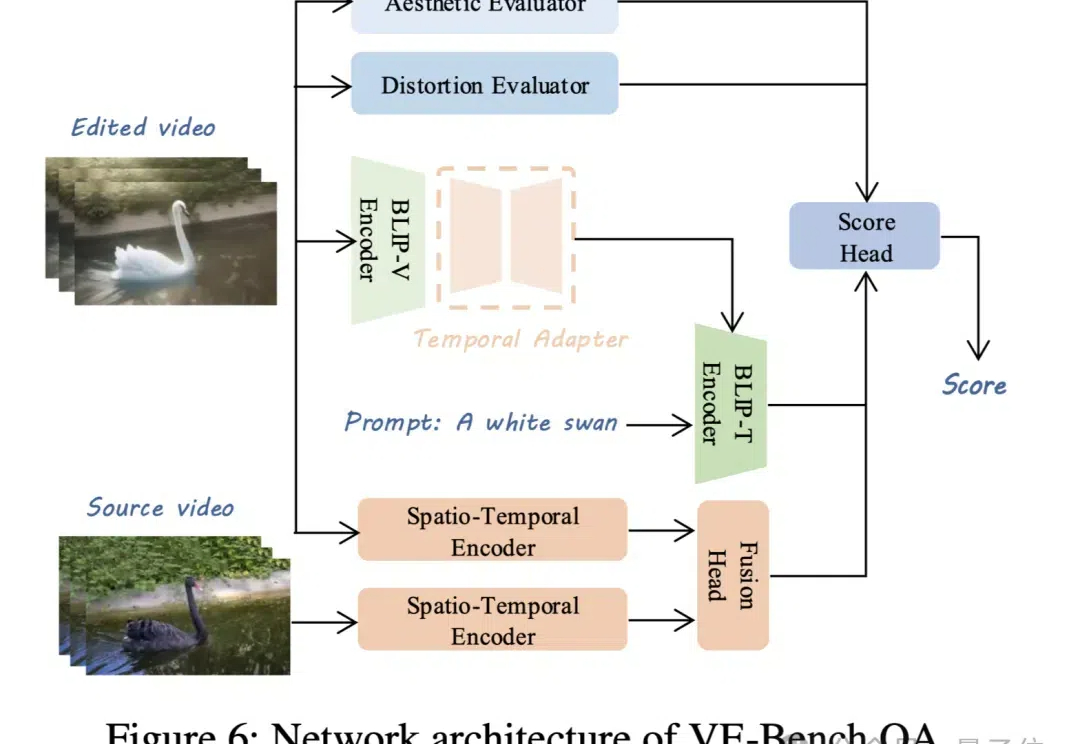
视频生成模型卷得热火朝天,配套的视频评价标准自然也不能落后。 现在,北京大学MMCAL团队开发了首个用于视频编辑质量评估的新指标——VE-Bench,相关代码与预训练权重均已开源。

2024 年 12 月 10-15 日,今年度的 NeurIPS 已在加拿大温哥华成功举办。今年的会议上,我们看到了 Ilya Sutskever 关于预训练即将终结的预测,也看到了引发广泛争议的 MIT 教授 NeurIPS 演讲公开歧视中国学生的事件。

12 月 2-6 日,亚马逊云科技在美国拉斯维加斯举办了今年度的 re:Invent 大会。会上,亚马逊云科技发布了相当多东西,其中之一便是新的大模型系列 Nova。说实话,这确实出乎了相当多人的意料 —— 毕竟亚马逊已经重金押注 Anthropic,似乎没有必要再自起炉灶了。

现如今,以 GPT 为代表的大语言模型正深刻影响人们的生产与生活,但在处理很多专业性和复杂程度较高的问题时仍然面临挑战。在诸如药物发现、自动驾驶等复杂场景中,AI 的自主决策能力是解决问题的关键,而如何进行决策大模型的高效训练目前仍然是开放性的难题。

Ilya Sutskever(前 OpenAI 联合创始人兼首席科学家)在前几天召开的 NeurIPS 会议上表示,大模型的预训练已经走到了尽头。而 Noam Brown(OpenAI 研究员,曾带领团队开发出在德州扑克中战胜职业选手的 AI 系统 Pluribus)在近期关于 OpenAI O1 发布的采访中提到,提升 Test-Time Compute 是提升大模型答案质量的关键。