
Ilya错了,预训练没结束!LeCun等反击,「小模型时代」让奥特曼预言成真
Ilya错了,预训练没结束!LeCun等反击,「小模型时代」让奥特曼预言成真Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。
来自主题: AI资讯
9285 点击 2024-12-17 10:02
 搜索
搜索
Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。

在Ilya探讨完「预训练即将终结」之后,关于Scaling Law的讨论再次引发热议。
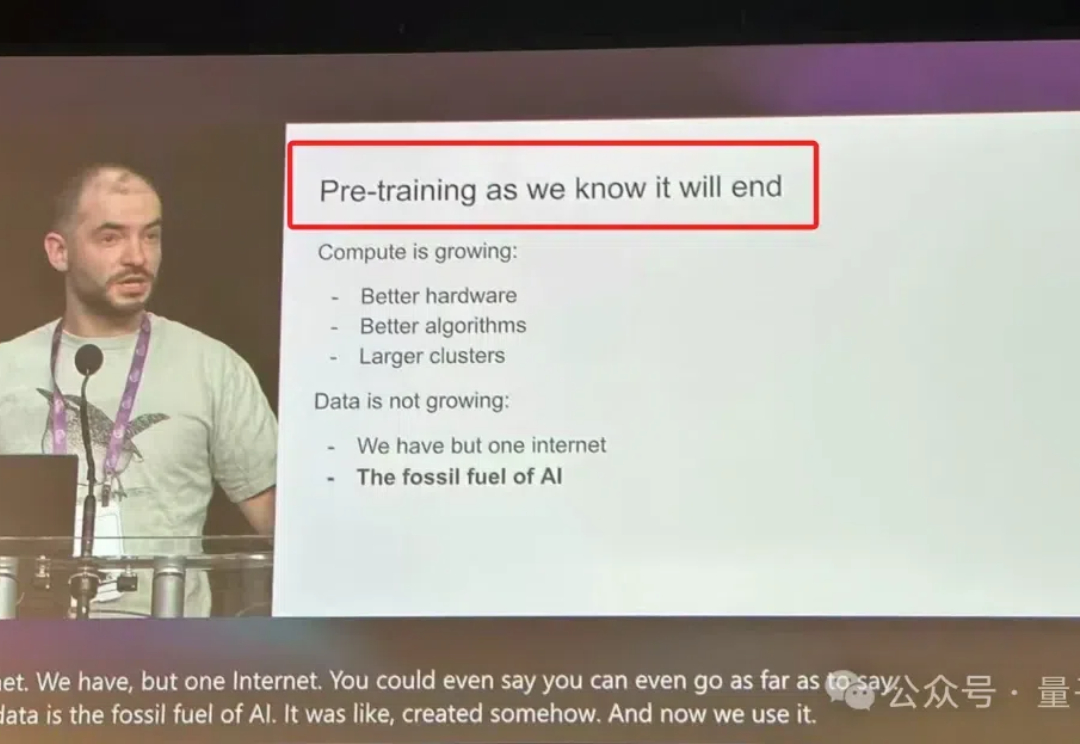
继李飞飞、Bengio、何恺明之后,在刚刚的NeurIPS 2024中,Ilya Sutskever最新演讲也来了。
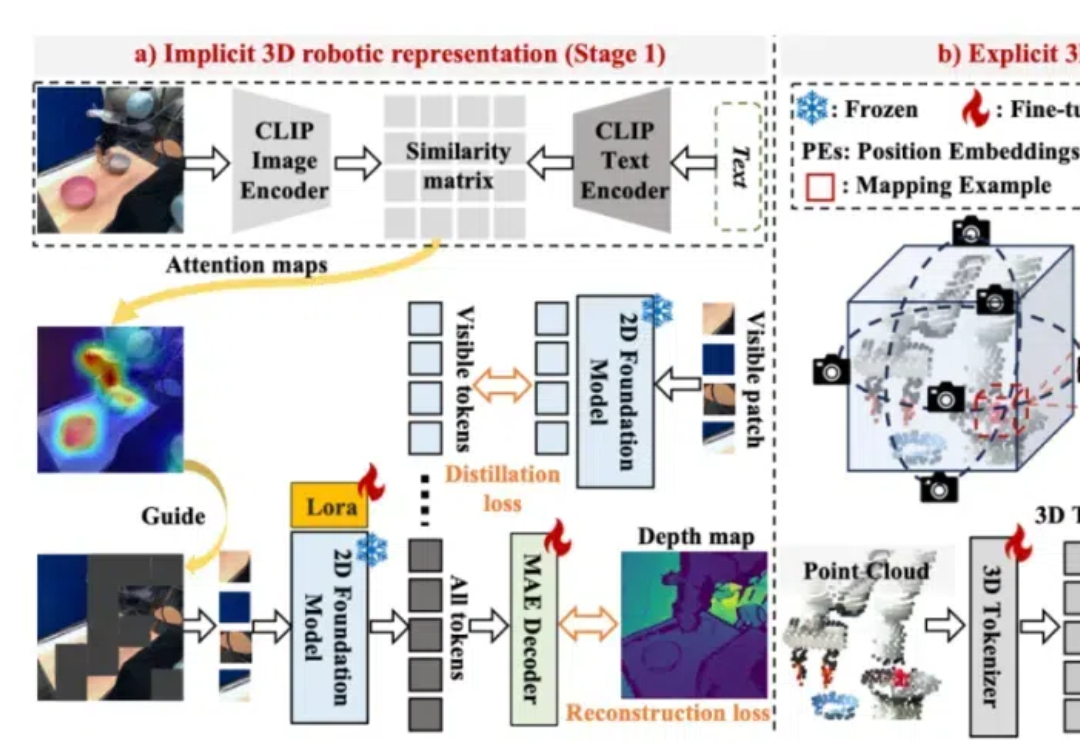
为了构建鲁棒的 3D 机器人操纵大模型,Lift3D 系统性地增强 2D 大规模预训练模型的隐式和显式 3D 机器人表示,并对点云数据直接编码进行 3D 模仿学习。Lift3D 在多个仿真环境和真实场景中实现了 SOTA 的操纵效果,并验证了该方法的泛化性和可扩展性。
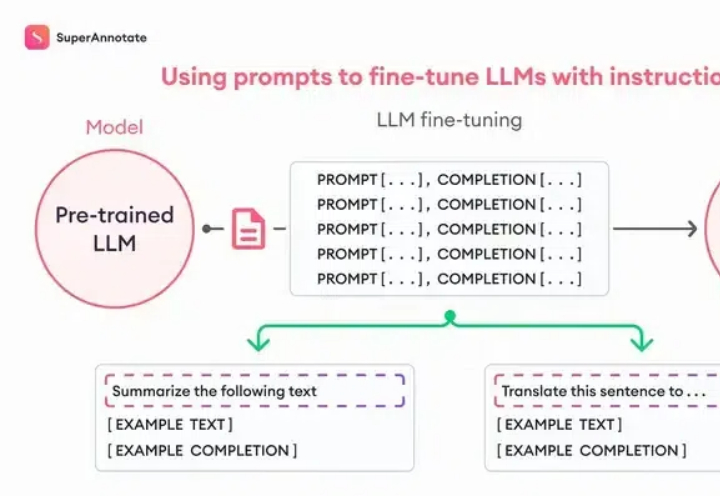
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。

LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。
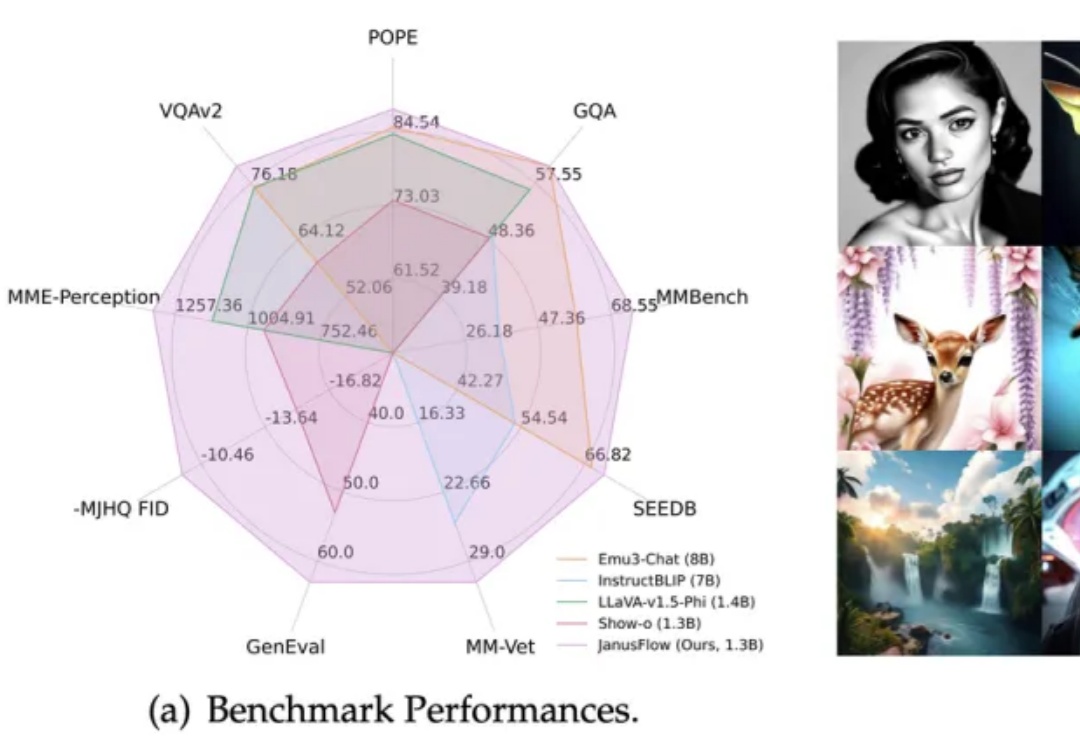
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
随着开源数据的日益丰富以及算力价格的持续下降,对于个人或小型机构而言,预训练一个小型的 LLM 已逐渐成为可能。开源中文预训练语言模型 Steel - LLM 就是一个典型案例,其模型参数量与数据量并非十分庞大,基本处于参数量为 B 级别、数据量为 T 级别的规模。
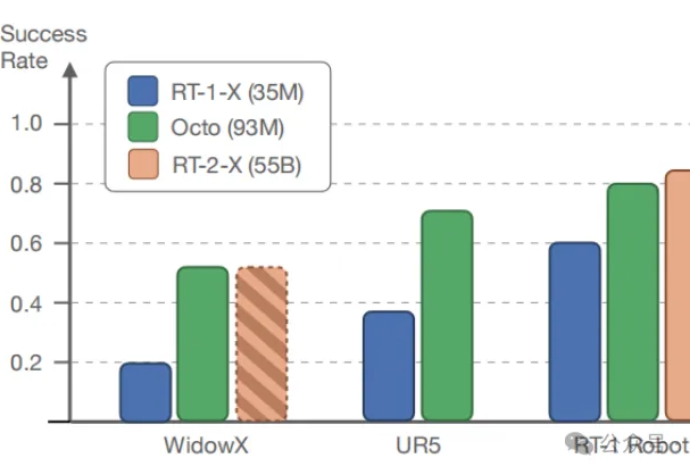
在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。

Ilya终于承认,自己关于Scaling的说法错了!现在训练模型已经不是「越大越好」,而是找出Scaling的对象究竟应该是什么。他自曝,SSI在用全新方法扩展预训练。而各方巨头改变训练范式后,英伟达GPU的垄断地位或许也要打破了。