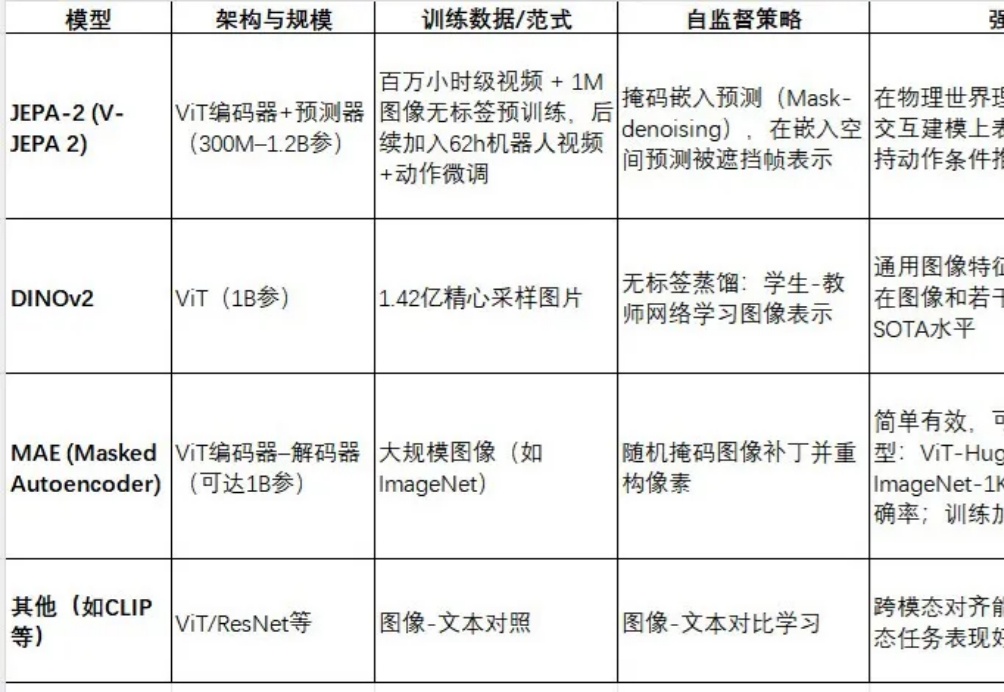
视频世界模型JEPA‑2与Meta AI的具身智能系统
视频世界模型JEPA‑2与Meta AI的具身智能系统JEPA-2(V-JEPA 2)是Meta最新推出的视频世界模型,采用视图嵌入预测(Joint Embedding Predictive Architecture)框架进行自监督预训练。
来自主题: AI资讯
7959 点击 2025-07-01 10:30
 搜索
搜索
JEPA-2(V-JEPA 2)是Meta最新推出的视频世界模型,采用视图嵌入预测(Joint Embedding Predictive Architecture)框架进行自监督预训练。
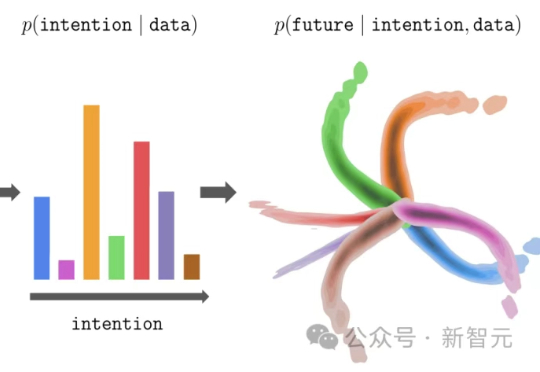
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?

预训练模型能否作为探索新架构设计的“底座” ? 最新答案是:yes!
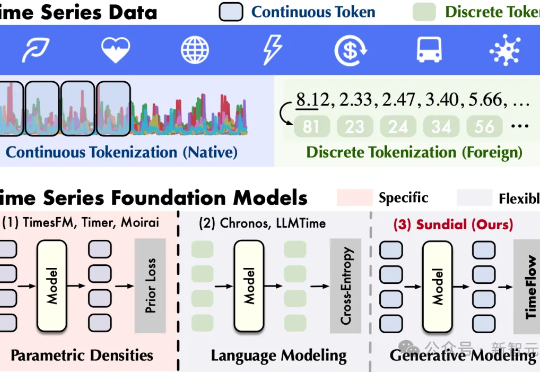
清华大学软件学院发布生成式时序大模型——日晷(Sundial)。告别离散化局限,无损处理连续值,基于流匹配生成预测,缓解预训练模式坍塌,支持非确定性概率预测,为决策过程提供动态支持。

OpenAI发布最新论文,找了到控制AI“善恶”的开关。
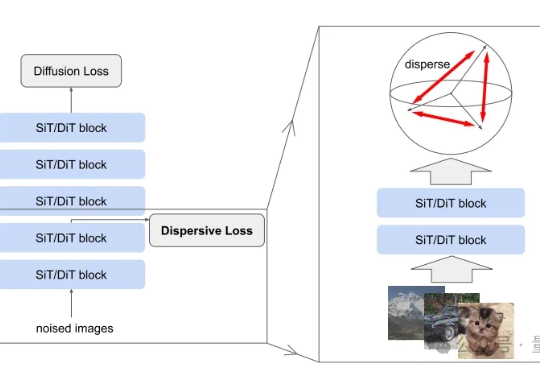
扩散模型风头正盛,何恺明最新论文也与此相关。 研究的是如何把扩散模型和表征学习联系起来—— 给扩散模型加上“整理收纳”功能,使其内部特征更加有序,从而生成效果更加自然逼真的图片。
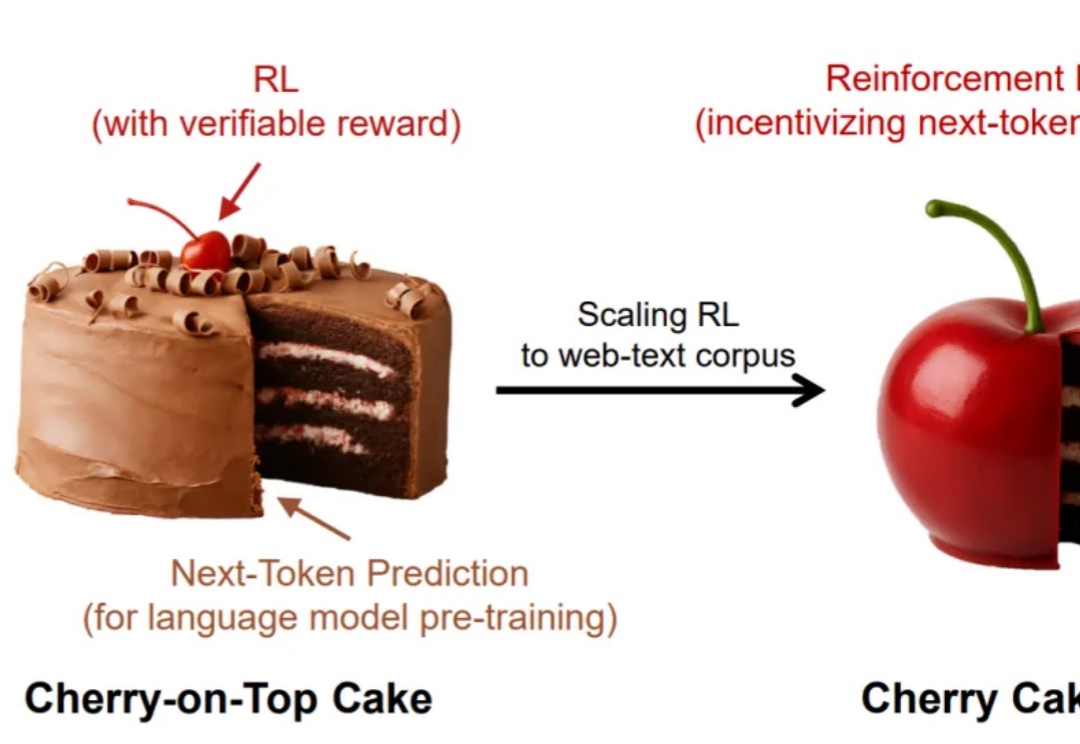
谁说强化学习只能是蛋糕上的樱桃,说不定,它也可以是整个蛋糕呢?
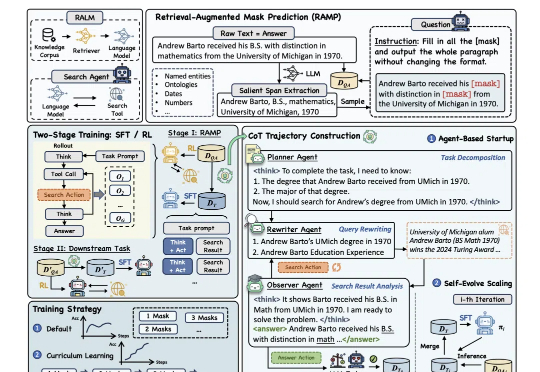
为提升大模型“推理+搜索”能力,阿里通义实验室出手了。
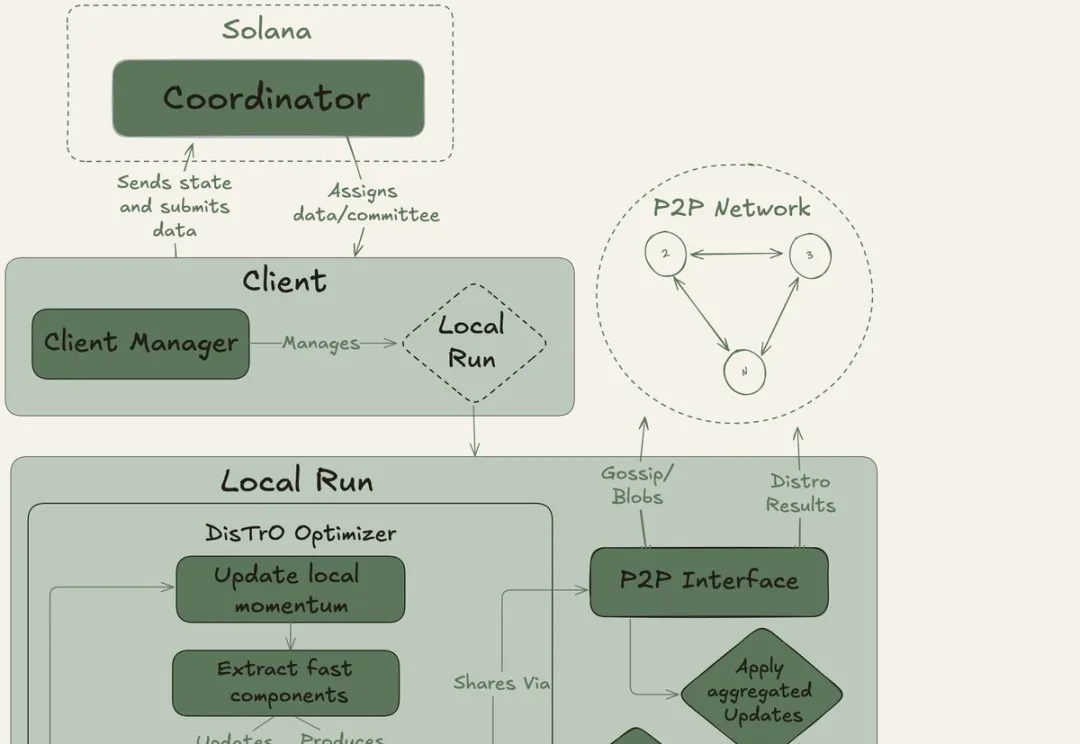
全球网友用闲置显卡组团训练大模型。40B大模型、20万亿token,创下了互联网上最大规模的预训练新纪录!去中心化AI的反攻,正式开始。OpenAI等巨头的算力霸权,这次真要凉了?

何恺明团队又一力作!这次他们带来的是「生成模型界的降维打击」——MeanFlow:无需预训练、无需蒸馏、不搞课程学习,仅一步函数评估(1-NFE),就能碾压以往的扩散与流模型!