
一等奖20万,大佬们出题,最硬核视频生成全球挑战赛开启!
一等奖20万,大佬们出题,最硬核视频生成全球挑战赛开启!首个AI视频生成全球挑战赛来袭,袁粒、颜水成、程明明、田永鸿、Philip Torr多位大佬发起,20万大奖虚位以待!创作大神还是技术极客?两大赛道总有一个适合你,速速点击报名吧。
来自主题: AI资讯
9669 点击 2025-12-18 09:47
 搜索
搜索
首个AI视频生成全球挑战赛来袭,袁粒、颜水成、程明明、田永鸿、Philip Torr多位大佬发起,20万大奖虚位以待!创作大神还是技术极客?两大赛道总有一个适合你,速速点击报名吧。
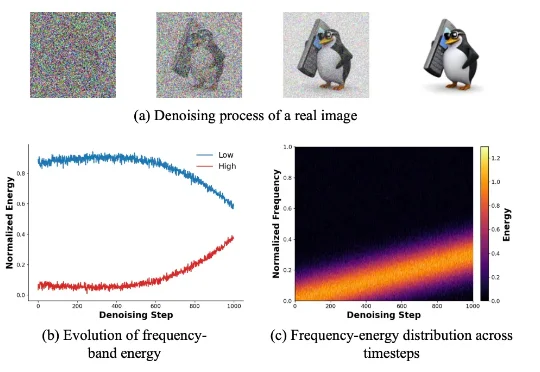
新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。
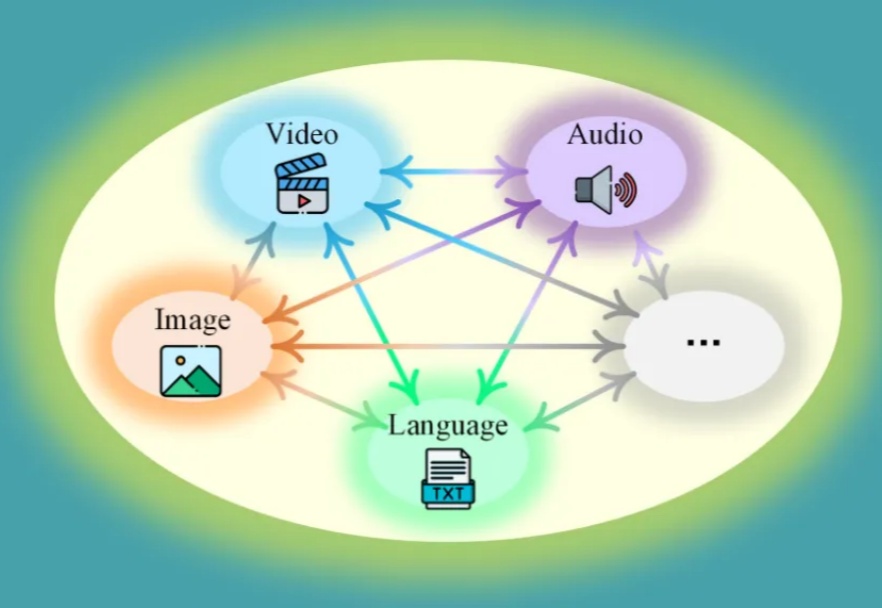
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
在产业界兜兜转转几年后,颜水成再次选择回归学界—— 重返新加坡国立大学NUS,担任计算机系特聘教授。没错,就是他第一个教职所在地,也是他声名鹊起的地方。

AI科技评论独家获悉,AI领域国际顶尖学者颜水成又有新动态,已经于近日离开昆仑万维。

比传统MoE推理速度更快、性能更高的新一代架构,来了! 这个通用架构叫做MoE++,由颜水成领衔的昆仑万维2050研究院与北大袁粒团队联合提出。

近日,一篇出自中国团队之手的AI论文在外网引发热议。论文中,研究团队提出了Q*模型算法,帮助Llama-2-7b等小模型达到参数量比其大数十倍、甚至上百倍模型的推理能力,使模型性能迎来惊人提升。

奔向通用人工智能,大模型又迈出一大步。
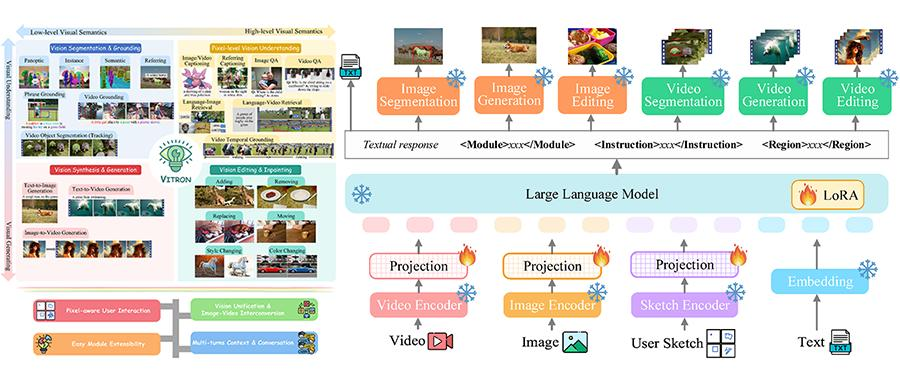
奔向通用人工智能,大模型又迈出一大步。