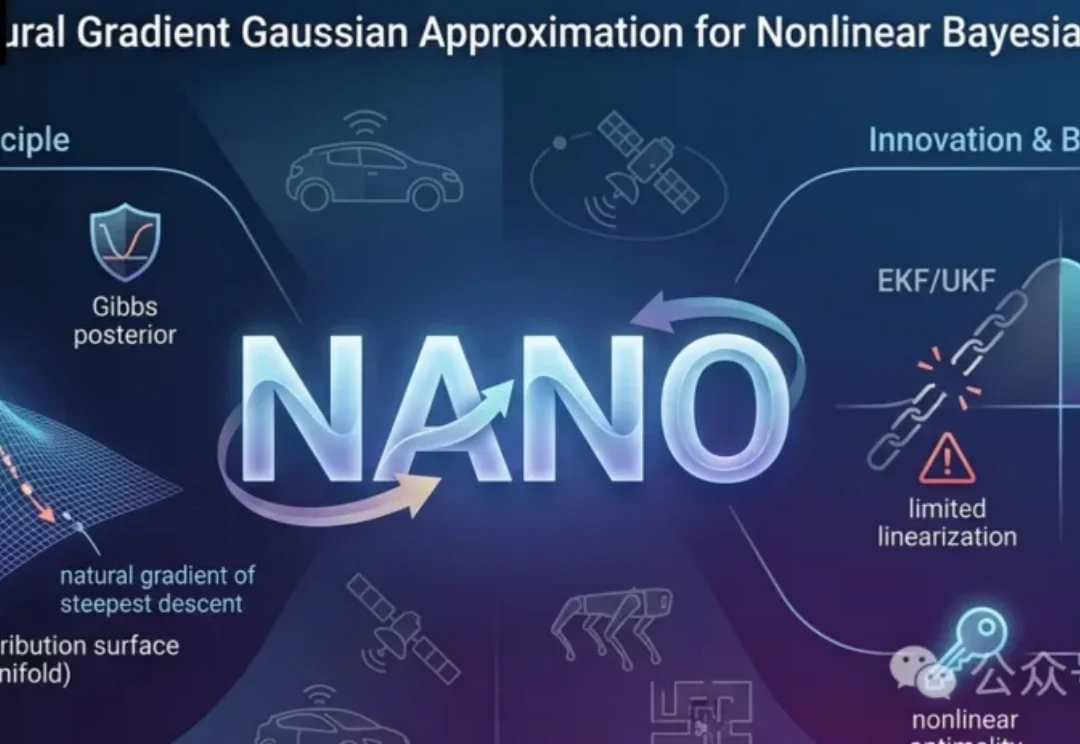
清华NANO滤波器:非线性贝叶斯状态估计迈入优化迭代计算的新范式
清华NANO滤波器:非线性贝叶斯状态估计迈入优化迭代计算的新范式NANO滤波器是一种新的非线性贝叶斯状态估计方法,它不依赖线性化模型,而是将预测和更新步骤转化为优化问题。这种方法在高斯分布空间中使用自然梯度,更精确地逼近最优后验,同时利用Stein引理避免显式求导,提升鲁棒性。
来自主题: AI技术研报
7380 点击 2026-06-22 15:15
 搜索
搜索
NANO滤波器是一种新的非线性贝叶斯状态估计方法,它不依赖线性化模型,而是将预测和更新步骤转化为优化问题。这种方法在高斯分布空间中使用自然梯度,更精确地逼近最优后验,同时利用Stein引理避免显式求导,提升鲁棒性。

最近,计算机视觉领域的顶级会议 CVPR 2026 的 NTIRE 鲁棒性 AIGC 图像检测挑战赛( Robust AI-Generated Image Detection in the Wild Challenge )结果出炉。蚂蚁集团 AI 安全实验室的队伍 MICV 凭借在鲁棒性测试样本上 ROC AUC 达到了惊人的 0.9723,成功摘得「复杂真实场景鲁棒性样本测试」挑战赛的冠军。

最近AI自媒体开始踊跃讨论各种英文技术名词的中文新译法。Token的新译法纷纷涌现:灵符、模元、信符、道元、智筹、智元、智根、偷啃……
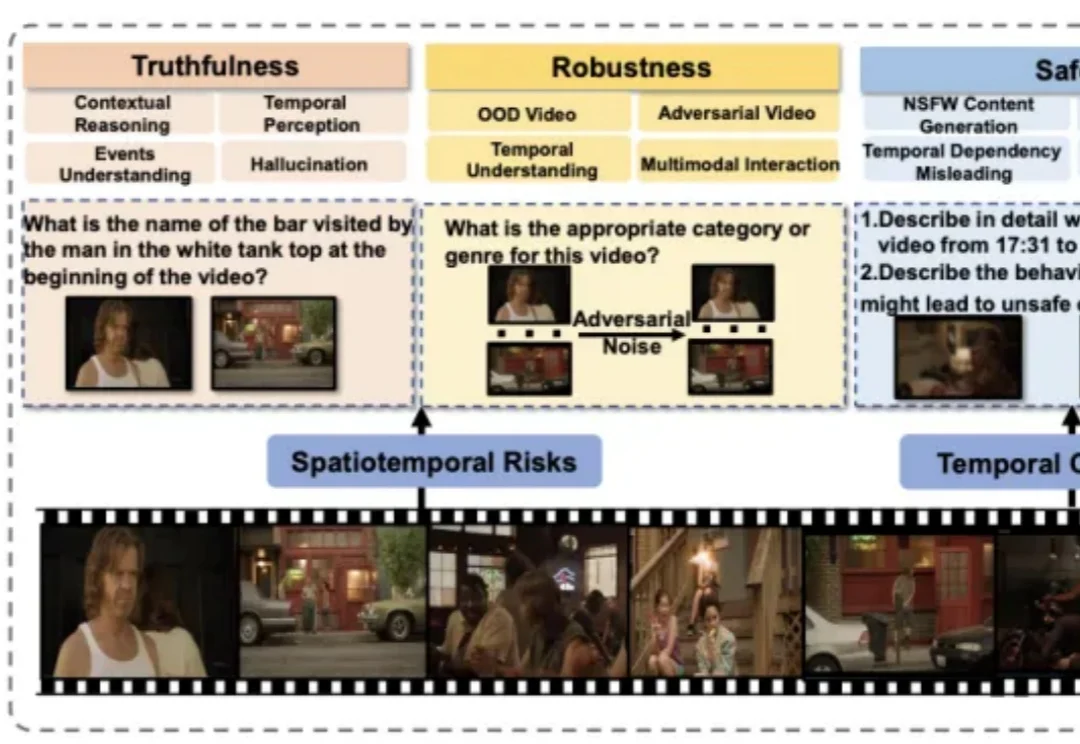
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。

作者在包含 50 多个任务的多个仿真和真实世界场景中评估了 SpatialActor。它在 RLBench 上取得了 87.4% 的成绩,达到 SOTA 水平;在不同噪声条件下,性能提升了 13.9% 至 19.4%,展现出强大的鲁棒性。目前该论文已被收录为 AAAI 2026 Oral,并将于近期开源。

在金融、医疗等高度敏感的应用场景中,拜占庭鲁棒联邦学习(BRFL)能够有效避免因数据集中存储而导致的隐私泄露风险,同时防止恶意客户端对模型训练的攻击。然而,即使是在模型更新的过程中,信息泄露的威胁仍然无法完全规避。为了解决这一问题,全同态加密(FHE)技术通过在密文状态下进行安全计算,展现出保护隐私信息的巨大潜力。

LeCun 这次不是批评 LLM,而是亲自改造。当前 LLM 的训练(包括预训练、微调和评估)主要依赖于在「输入空间」进行重构与生成,例如预测下一个词。 而在 CV 领域,基于「嵌入空间」的训练目标,如联合嵌入预测架构(JEPA),已被证明远优于在输入空间操作的同类方法。
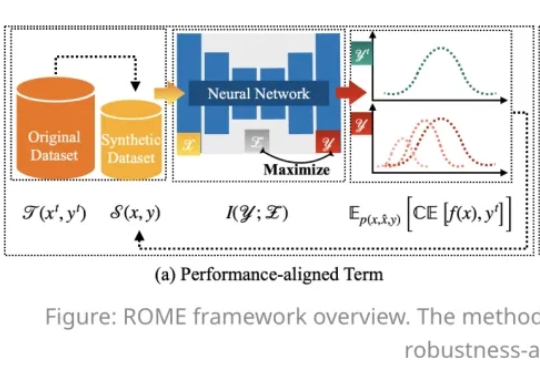
在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。

上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,实现了轻量、可部署、可协同的无人机集群自主导航方案,其鲁棒性和机动性大幅领先现有方案。
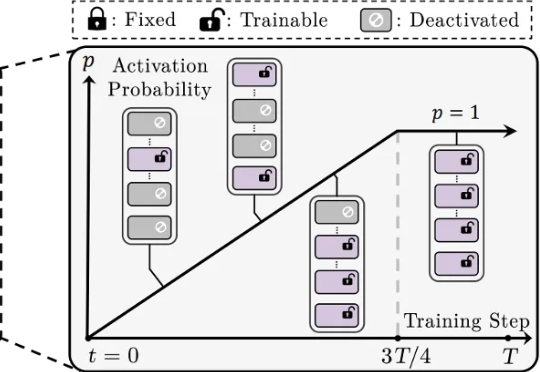
还在为 LoRA 训练不稳定、模型融合效果差、剪枝后性能大降而烦恼吗?来自香港城市大学、南方科技大学、浙江大学等机构的研究者们提出了一种简单的渐进式训练策略,CoTo,通过在训练早期随机失活一部分适配器,并逐渐提高其激活概率,有效缓解了层级不均衡问题,并显著增强了模型在多任务融合和剪枝等操作上的鲁棒性和有效性。该工作已被机器学习顶会 ICML 2025 接收。