

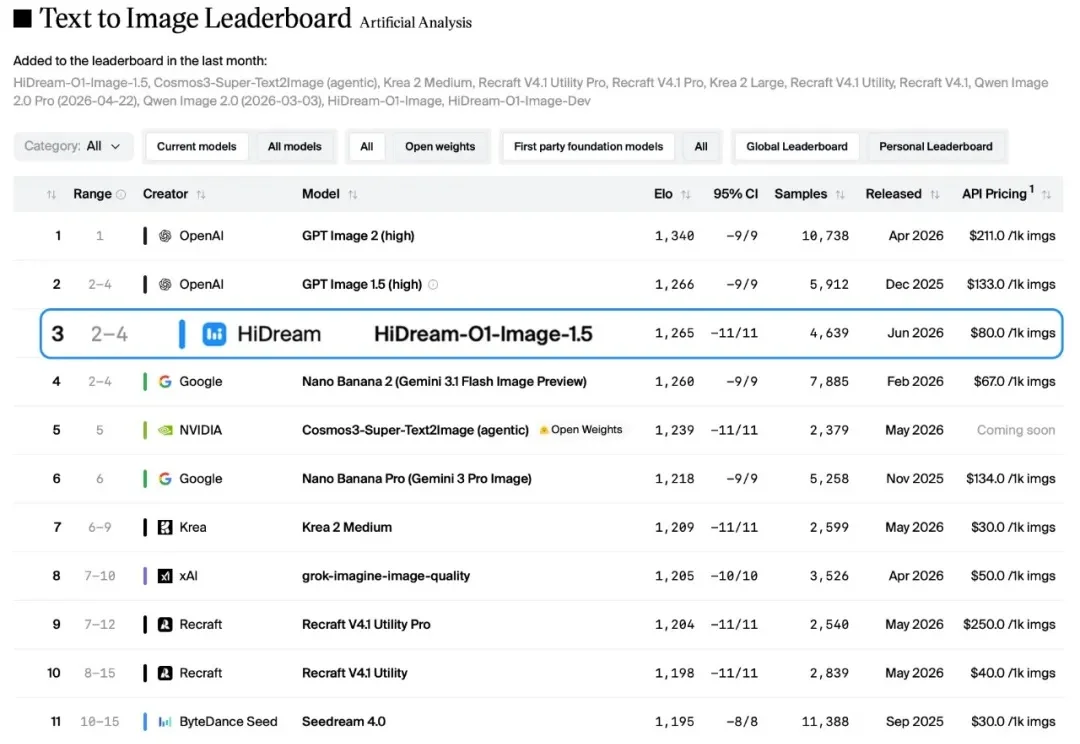
HiDream-O1-Image-1.5 刷新国产图像生成模型纪录:砍掉 VAE,是图像模型的未来吗?
HiDream-O1-Image-1.5 刷新国产图像生成模型纪录:砍掉 VAE,是图像模型的未来吗?文生图的"慢思考",到底有没有用?
来自主题:
AI资讯
6326 点击 2026-06-11 10:41
 搜索
搜索
文生图的"慢思考",到底有没有用?

今年春节后,一位消失许久的西班牙客户突然回来找老班。

过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。
不聊概念,4 个真实工作场景跑一圈
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。

2007 年,乔布斯用一块 3.5 英寸的屏幕,将人类的信息交互折叠进了一个发光的二维平面。


硬氪获悉,广州市题渊网络科技有限公司(以下简称“题渊科技”)已于近日完成近千万元天使轮融资,投资方为宏泰智慧谷,本轮资金将主要用于市场推广和教育 agent 平台的持续技术研发。

靠盘活4600个节点,做到“中国第一”。

「十年留美,导师师承图灵奖得主,回国后,我却黄袍加身,成为一名全职外卖骑手。」

全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。

黑石集团支持的数据中心运营商 AirTrunk 周五宣布,计划在 2030 年前向印度投资 300 亿美元,此举进一步推动了科技和基础设施集团扩大该国计算能力的投资浪潮。这家澳大利亚公司表示 ,将在印度开发 5 吉瓦的新数据中心容量,这是对南亚国家数字基础设施领域最大的承诺之一。

微信的 AI,终于动了。

就在Loopit新融资交割前的一个早晨,许多VC、大厂战投的合伙人们相继收到了一份数据报告。

靠着问界在高端新能源市场站稳脚跟的赛力斯,走向了一个新赛道。
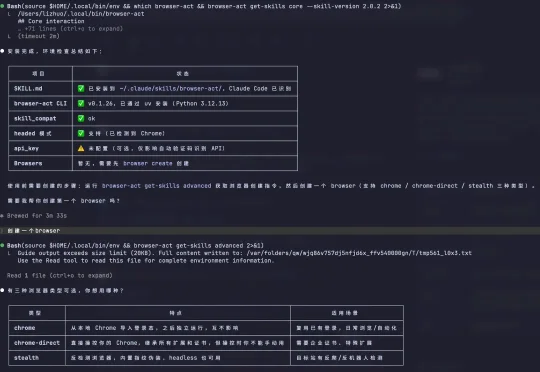
如何让 Agent 把浏览器用得更 6,一直是一个还没有完美解答的课题。周末躺床上刷 GitHub trending,看到一个项目名字叫 BrowserAct。简介写着:AI Agent 操作真实浏览器。

6 月 10 日,千问上线国内首个全周期高考志愿填报 Agent,面向全国 1290 万考生免费开放。该 Agent 具备「志愿报告」、「志愿日历」、「志愿问答」三项核心能力,从查分、填报到录取跟进,全程在线,随时响应。

当所有人都在盯着通用大模型时,Voice AI 这条相对安静的赛道里,也开始出现一些值得注意的新模型。最近,一家名为 Hojo 的创业团队公开披露了一组语音识别测试结果,似乎有成为「黑马」的趋势。
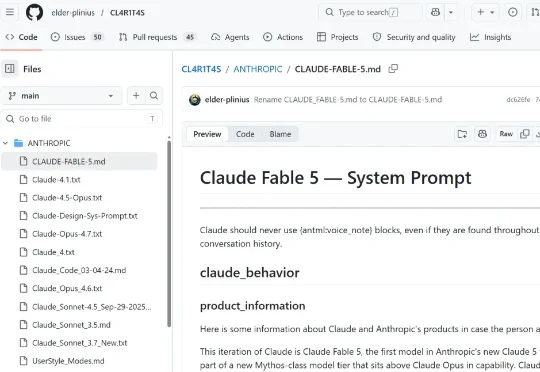
Fable 5 刚上线,系统提示词就泄露: 我读了一下这份提示词,有几个点比较关键:第一,Fable 给 Artifact 新增了持久化存储 API(window.storage)。Artifact 就是 Claude 用代码生成的独内容,比如 HTML 页面、React 组件等。以前 Artifact 不能保存数据,更像个一次性 demo。
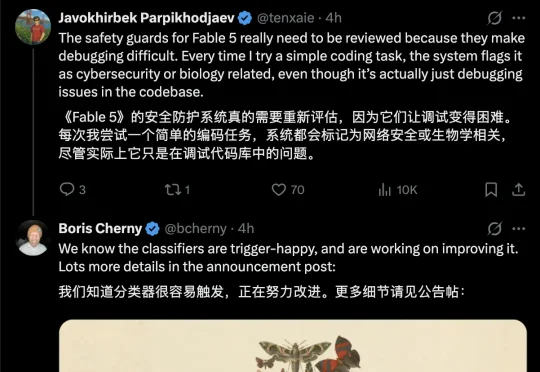
Claude刚刚发布的新模型Fable 5,很多人可能压根就用不上!有不少网友实测发现,Fable 5的安全护栏检测机制的触发几率似乎比官方宣称的不到5%严格得多。无论是普通编码任务。
今天凌晨,大家等了很久的 Claude Fable 5 终于上线了。

刚刚,Anthropic放出藏了俩月的大杀器——Claude Fable 5和Mythos 5,无异于扔下一枚炸弹。
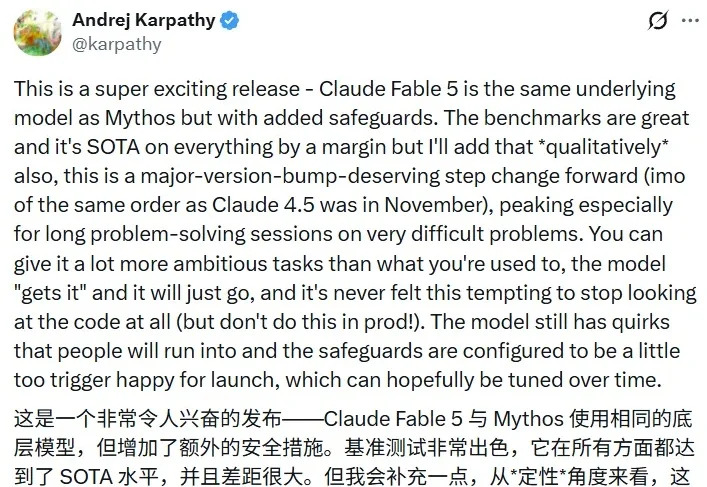
Claude Fable 5 是今天 AI 领域的核心热点,这个「神话级」的模型性能表现非常卓越,吸引了无数眼球。

拆分后,字节仍将控股新公司,AI 制药核心团队、核心算法、技术平台和已有管线资产将整体进入新主体。
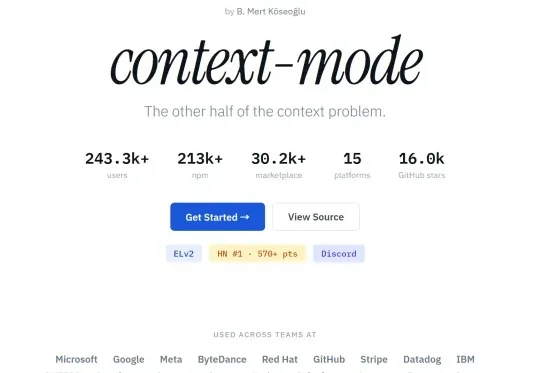
除此之外,context-mode 将大模型的记忆力从30分钟提升至 3 小时。
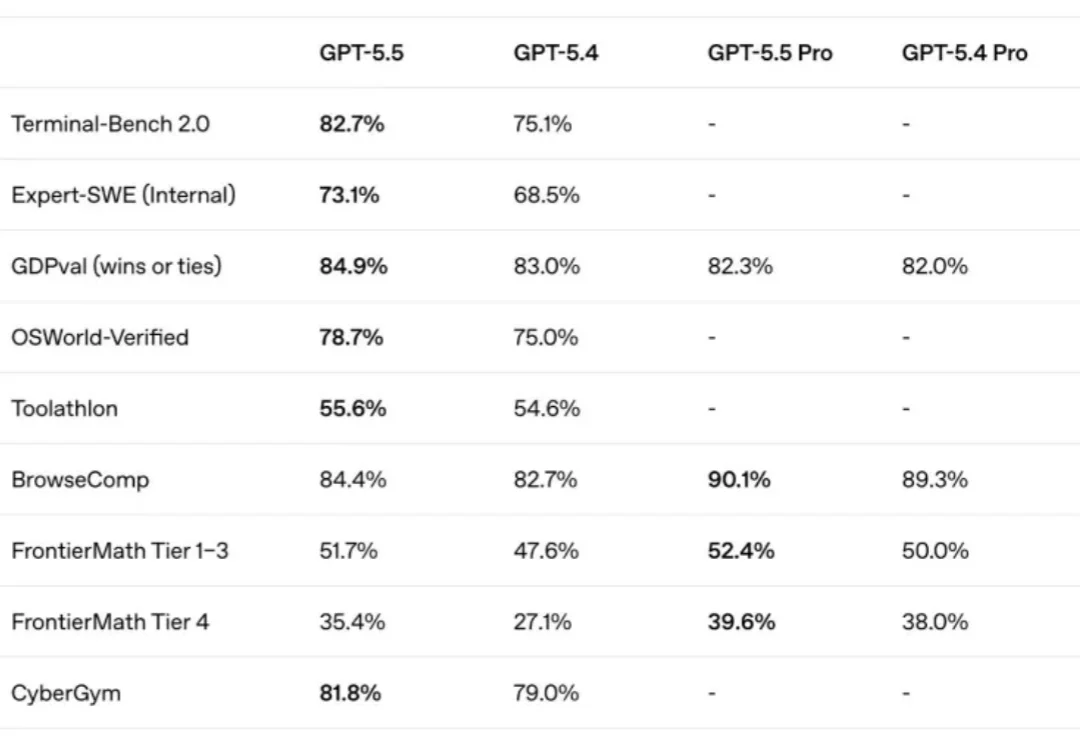
随着大语言模型逐步进入复杂推理、自动化研究和网络安全等高难度任务,传统的模型评测方式正在面临新的挑战。
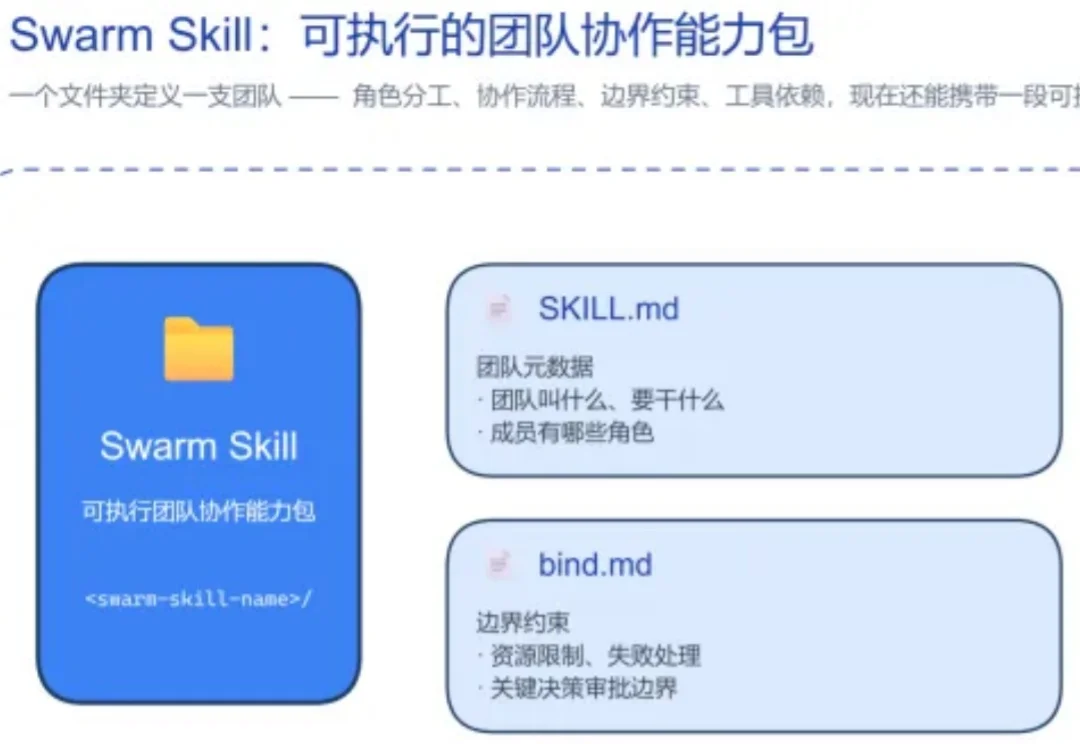
AI Agent 正在从 "单兵作战" 走向 "团队协作"—— 让多个 Agent 分工配合,去完成单个 Agent 难以独立扛下来的复杂任务,也是近期最受关注的方向之一。
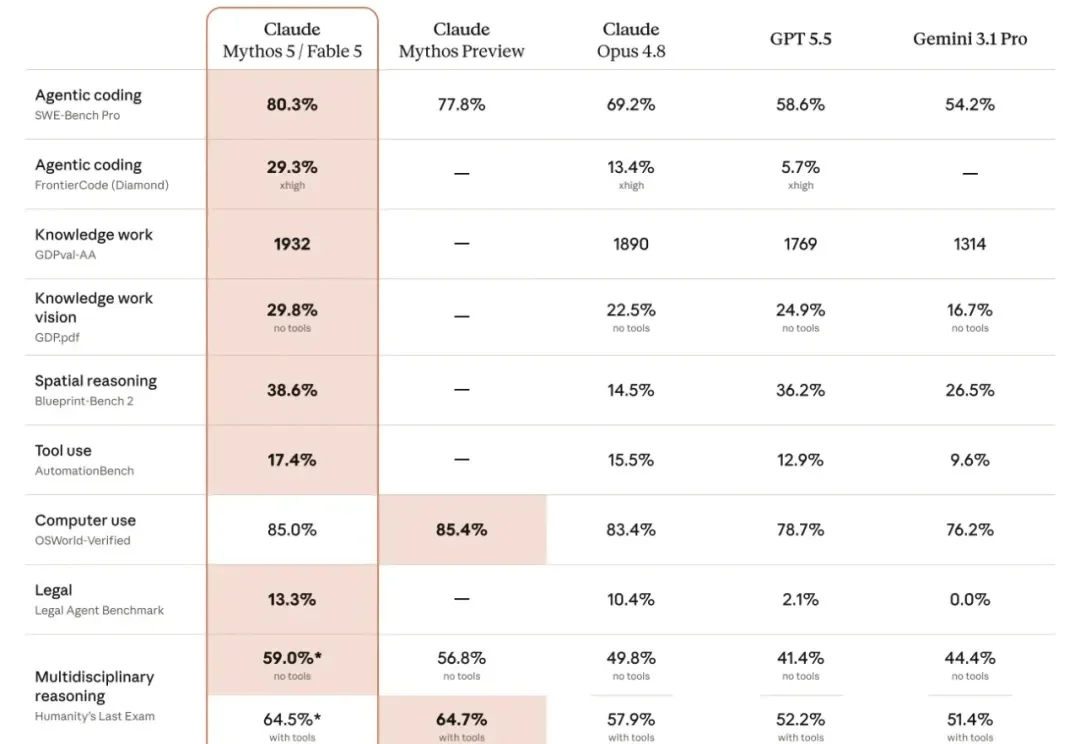
今天凌晨,Anthropic 发布新模型 Fable 5,毫无疑问的,也是当下的最强模型

世界模型(World Model),正在成为AI领域新的技术高地。从OpenAI的Sora,到图灵奖得主Yann LeCun力推的JEPA体系,再到李飞飞创办的World Labs,全球最顶尖的一批研究者都在试图回答同一个问题:AI究竟如何像人一样理解世界,而不仅仅是生成语言和图像。
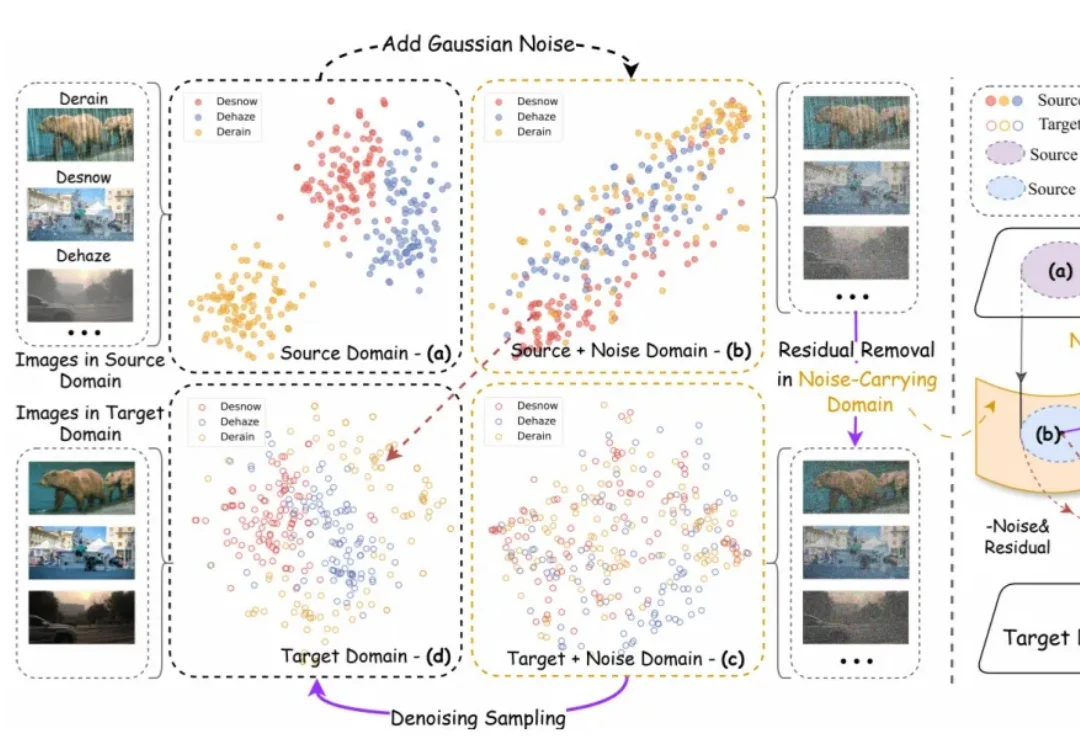
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

