# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。
但对于真正手搓本地Agent的人来说,比起它在榜单上排第几,我们更关心一个最朴素的问题:这个模型到底能不能融入现有的工作流?它是否具备可控的本地部署门槛?能否稳定处理多模态混合输入?又能否在一个复杂系统中承担具体的执行任务,而不是仅仅陪人聊天?
这也是我看Gemma 4-12B时最看重的地方。

它不是尺寸最大的卷王,也不该被包装成虚无缥缈的“闭源大模型替代品”。它最大的价值,是卡在了一个极其巧妙的位置:尺寸适中、多模态原生,天然适合放进本地工作流中,充当一个被主模型调度的SubAgent(子智能体)。
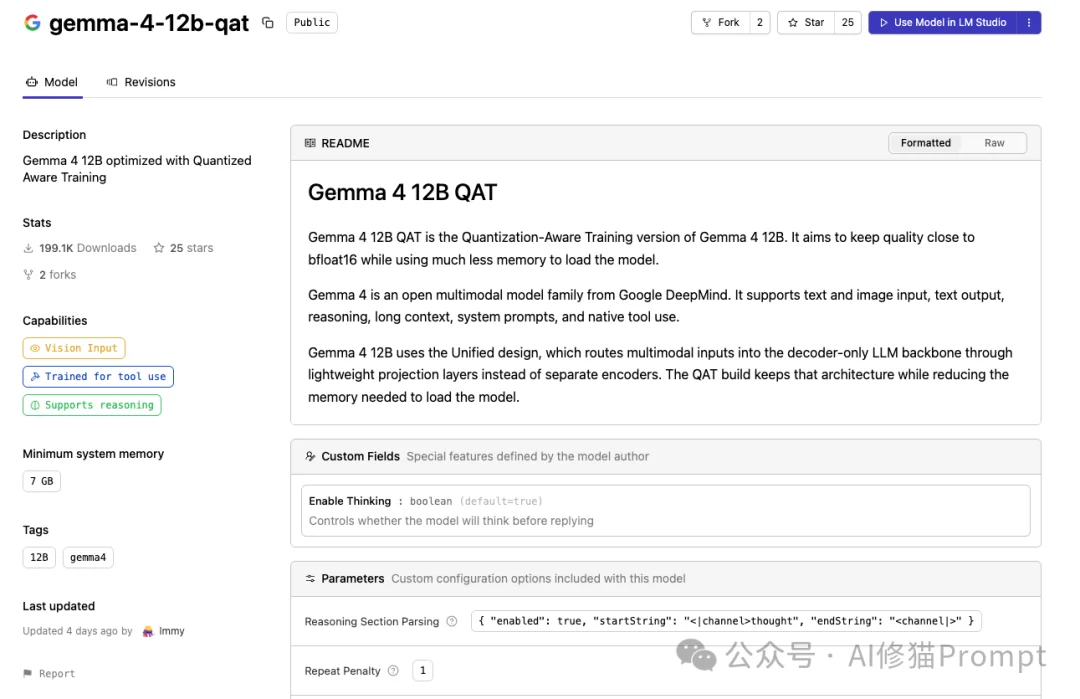
因此,这篇文章不谈跑分,只回答一个最实际的问题:谷歌最新放出的Gemma 4-12B,到底怎么用最好?
首先,用一组实测数据来打消你的顾虑。很多人一听“多模态大模型”,第一反应就是“我的电脑带不动”。但Gemma 4 12B的官方定位非常明确:这是一款面向笔记本电脑(Laptop)和消费级工作站的本地模型。

根据谷歌官方的实测反馈:
为什么它能这么省资源?答案在于它的核心设计,统一无编码器(Unified Encoder-free)架构。
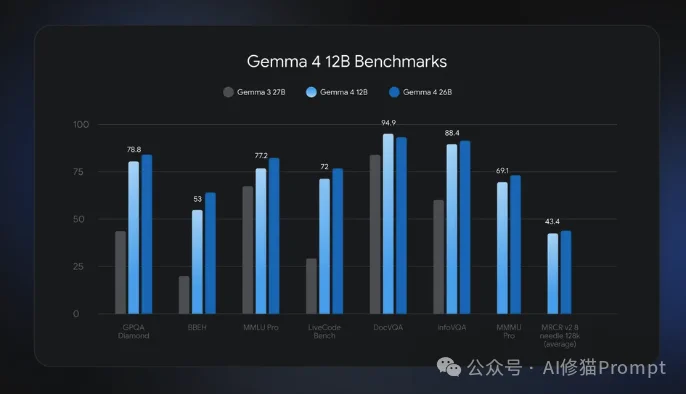
在Gemma 4 12B之前,绝大多数多模态模型(包括Gemma 4家族的其它尺寸模型)都带有独立的“视觉编码器”或“音频编码器”。这就好比给大脑外挂了两个翻译官,不管处理什么图片或声音,都要先经过翻译官的转码,不仅增加延迟,还狂吃显存。
Gemma 4 12B砍掉了这些“中间商”。它的视觉编码器参数为0,音频编码器参数也为0。它直接将原始的图像块(Patch)和音频波形,通过轻量级的线性层直接投影到LLM的词表嵌入空间(Embedding Space)中,然后统一丢进一个仅含解码器(Decoder-only)的Transformer骨干网络里。
这就是为什么它能做到“直吞音视频”,延迟极低,且内存占用大幅下降的根本原因。
如果你一直在关注当前最新的AI开发架构(比如OpenClaw等),你一定听过SubAgent(子智能体) 的概念。
简单来说,当我们在构建一个复杂的AI应用(比如一个能帮你写代码、查网页、还能看设计图的开发系统)时,不应该把所有任务都塞给一个昂贵且庞大的云端模型。
因为Gemma 4 12B是完全开源、免费、可离线运行的,把它作为SubAgent,不仅能完美保护你的本地隐私,还能让你零成本地处理海量多模态数据。
结论先行:在真正摸过这个模型的极客圈子里,Gemma 4-12B的三大核心正向反馈,绝不是“它比Qwen-27B更会写代码”,而是:轻量、全模态感知、以及极其适合充当本地的“全能小工”。
翻看Reddit、Hugging Face和各大开源社区,大家对它的兴奋点非常务实。目前,社区已经自发摸索出了三种最主流的用法与落地场景:
这是目前社区里声量最高、反响最强烈的正向反馈。大家最兴奋的不是模型在PPT榜单上刷了多少分,而是它真真切切能在个人消费级设备上跑起来,而且速度快得离谱。
谷歌官方将Gemma 4-12B定位为一款“能把智能体多模态能力直接带到笔记本电脑上”的模型,明确指出它可以在16GB VRAM或统一内存上本地满血运行,并原生支持MTP(多Token预测)技术来大幅降低延迟。
llama.cpp 挂载了Gemma 4-12B QAT(量化感知训练)权重加MTP drafter,生成速度直接从常规的60 tok/s飙升到了120 tok/s到140 tok/s,这个速度相当不错。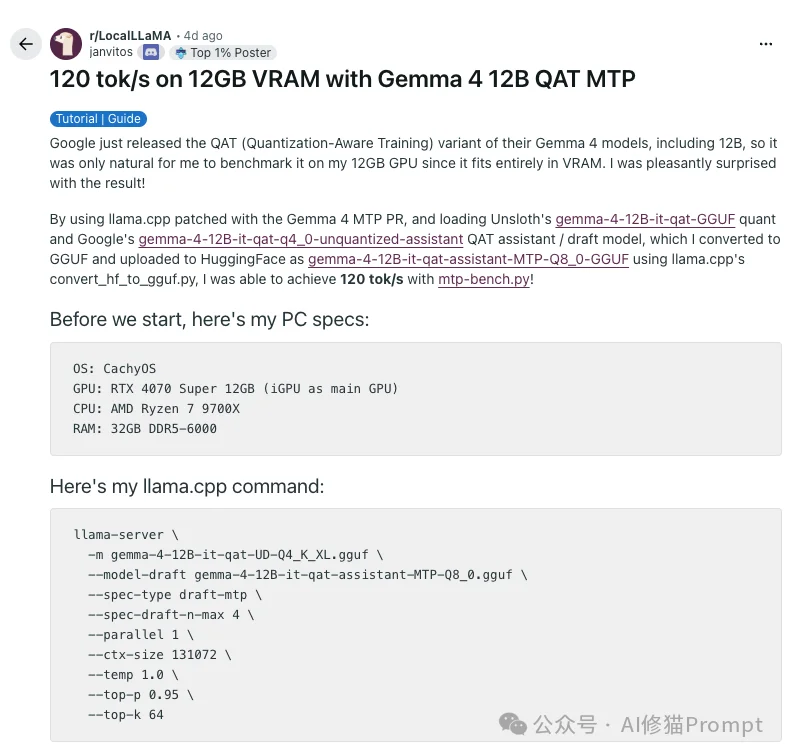
第二个集中爆发的正向反馈,是Gemma 4-12B在感知层的强悍实力。官方模型卡显示,Gemma 4-12B拥有11.95B参数和256K的超大上下文。由于采用了无视觉/音频编码器的Unified激进架构,图像Patch和音频波形会直接投射进LLM Backbone。这也是谷歌中型尺寸模型中,第一个真正实现原生音频输入的版本。

官方列出的视觉与感知能力,精准地踩中了社区的刚需:文档/PDF解析(Document/PDF parsing)、屏幕及UI理解(screen/UI understanding)、图表分析(chart comprehension)、多语言OCR、手写体识别以及目标指向(pointing)。
第三个正向反馈,明确了它在Agent系统中的定位——它确实能执行智能体任务,但相比于统筹全局,它更适合扮演短任务闭环里的“SubAgent(子智能体)”。
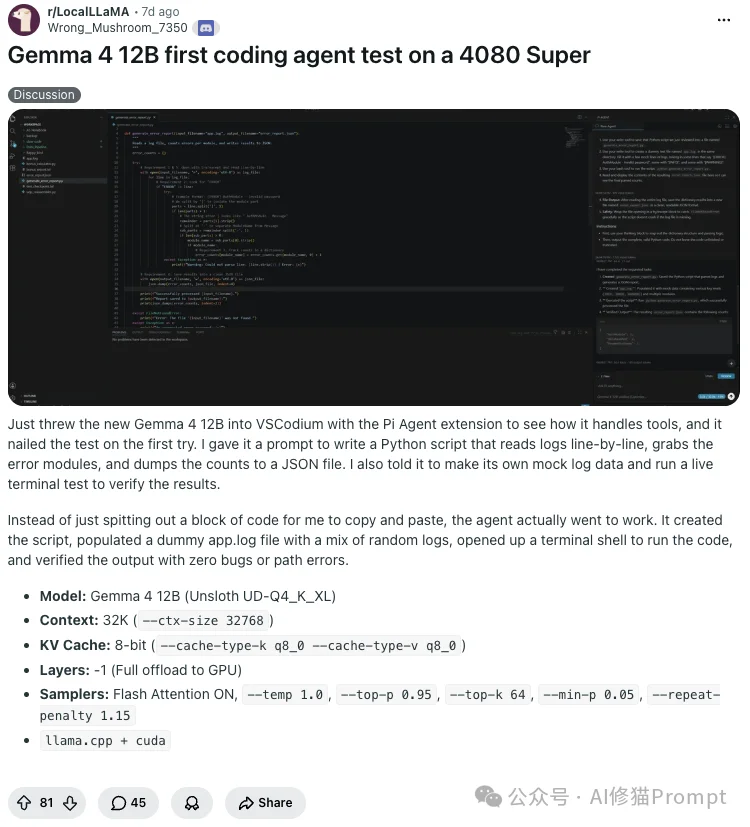
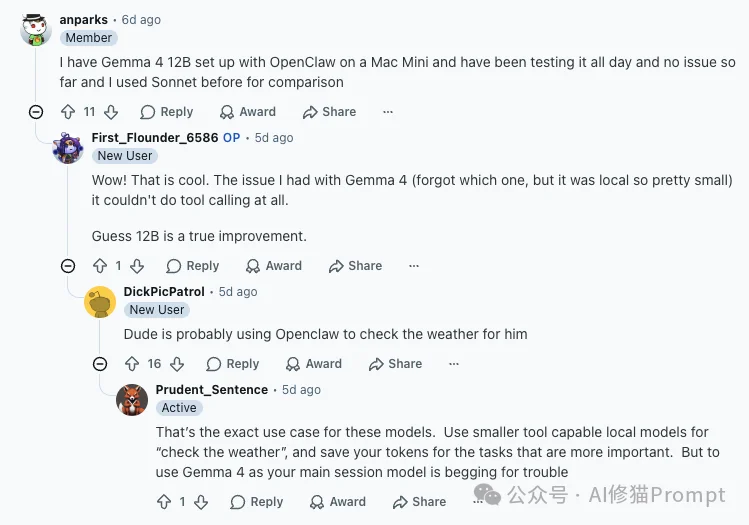
看到这里,你可能已经迫不及待想在自己的电脑上部署一个Gemma 4 12B了。不用担心显存,以下是最主流的极简部署策略。
要榨干这个模型的极限性能,千万不要只是傻傻地下载原版权重。谷歌官方给出了明确的性能优化路线:
如果你的电脑有一张12GB或16GB显存的NVIDIA显卡(比如RTX 4070、3060 12G等):
llama.cpp。目前 llama.cpp 的主分支已经合并了对Gemma 4 MTP的原生支持。gemma-4-12B-it-qat-GGUF 格式文件,配合MTP辅助模型启动,就可以直接用了。苹果M系列芯片(M1/M2/M3/M4/M5)拥有“统一内存”的优势,16GB内存的Mac非常适合跑这款多模态模型。
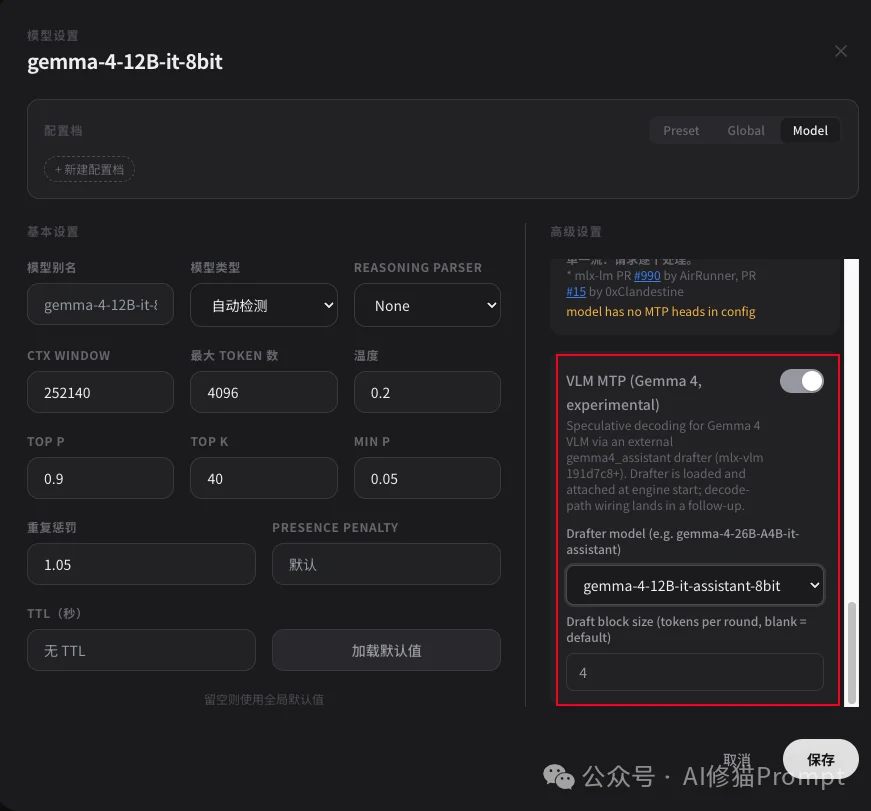
这里的MTP,是Multi-Token Prediction多token预测。普通大模型生成文本时基本是一次只生成一个token。这个过程很稳,但慢,因为每生成一个token,都要让大模型完整跑一轮。Gemma 4的MTP做法是引入一个assistant drafter / draft model。让一个几百兆的小模型先替主模型快速预测后面几个token,再让Gemma 4主模型一次性检查这些token,猜对的就直接采用,从而提高每秒token生成速度。
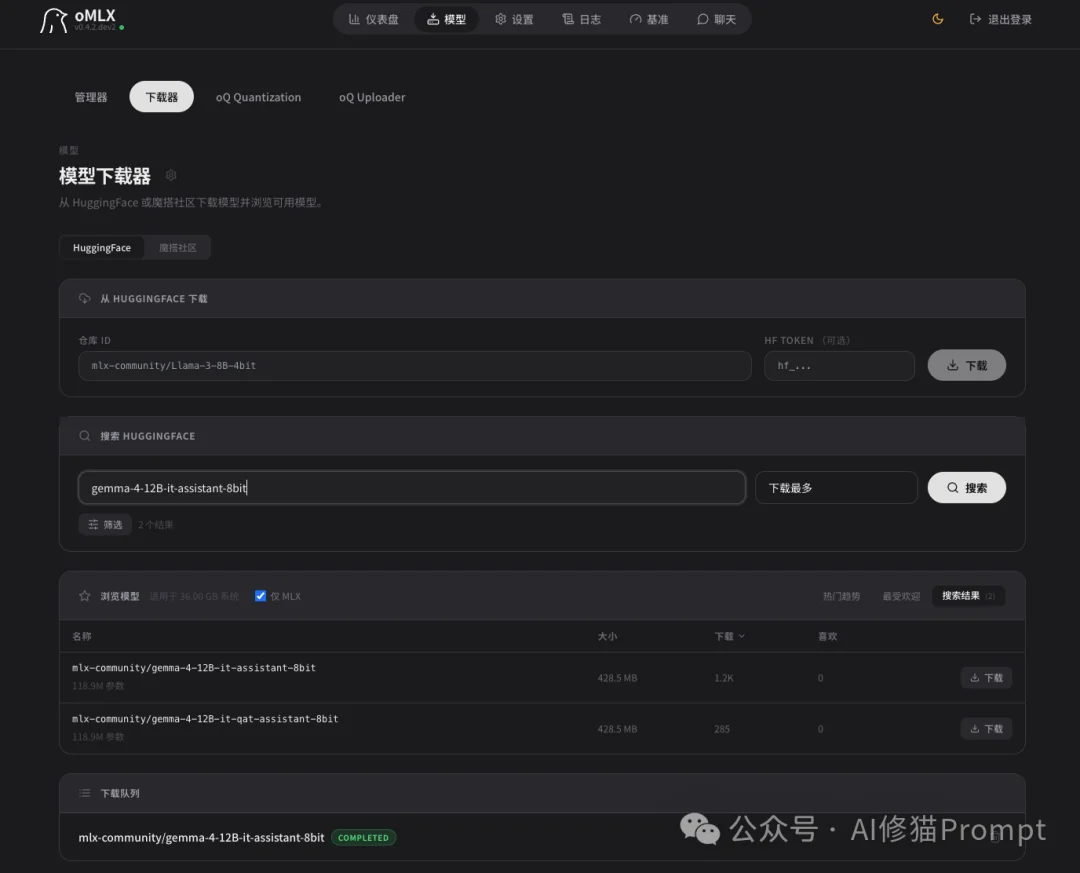
因此如果要启用这项功能,你还需要到模型下载器界面下载一个Gemma 4的小模型,名称是gemma-4-12B-it-assistant,大概800兆左右。具体型号根据你的主模型量化版本选择对应的即可。我这里下载的是gemma-4-12B-it-assistant-8bit。
虽然Gemma 4 12B的各项指标都很均衡,极具性价比,但根据全球极客在Reddit和Hugging Face上的大量实测,它绝对不是一个“六边形战士”。如果你把它放错了位置,体验会非常糟糕。
以下是社区集中爆发的三大核心负面反馈:
这是目前社区最核心的负面共识。
Gemma 4 12B对推理后端的配置非常敏感,很多人以为是“模型太笨”,其实往往是“外壳(Wrapper)坏了”。

<|tool_response|> 废弃标签等问题。谷歌Gemma 4 12B的伟大之处并不在于它刷新了多少份跑分榜单,而在于它真正地将“原生多模态”和“低门槛部署”结合在了一起。
它的发布,为每一位个人开发者、初创团队和隐私敏感的用户,提供了一个极其优秀的通用多模态子模型(SubAgent)。
如果你只有一台16GB内存的轻薄本,不想每个月花几百块去买云端API,又渴望拥有一个能看懂截图、听懂本地录音、帮你清洗数据的全天候AI助理,那么不要犹豫,去下载Gemma 4 12B吧。它绝对是2026年夏天,你能装进电脑里的最具性价比之一的本地多模态模型。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
