# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Kimi新模型热度持续高涨ing!
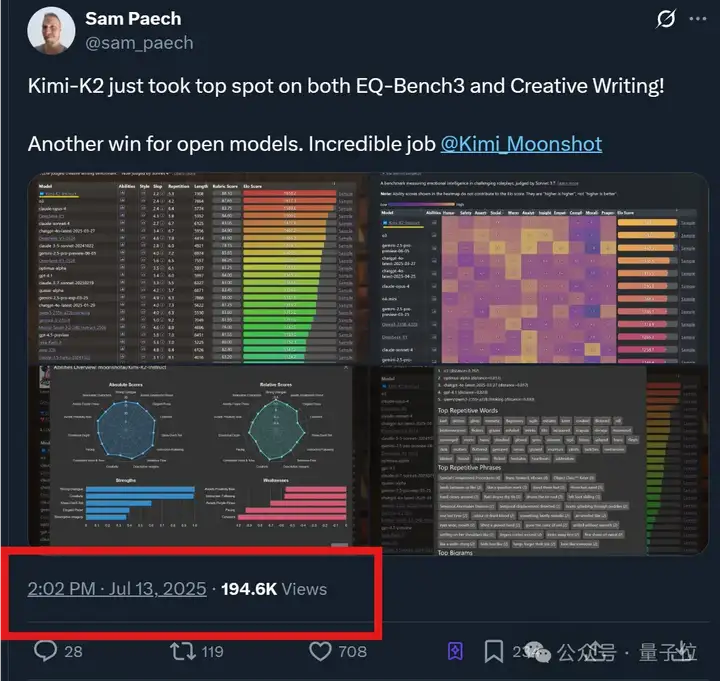
不光在更多benchmark上拿下SOTA,体验过的网友们也是一水儿好评——
新模型K2非常擅长工具调用,属于“自Claude 3.5 Sonnet以来,能放心用于生产力级别任务的模型”。

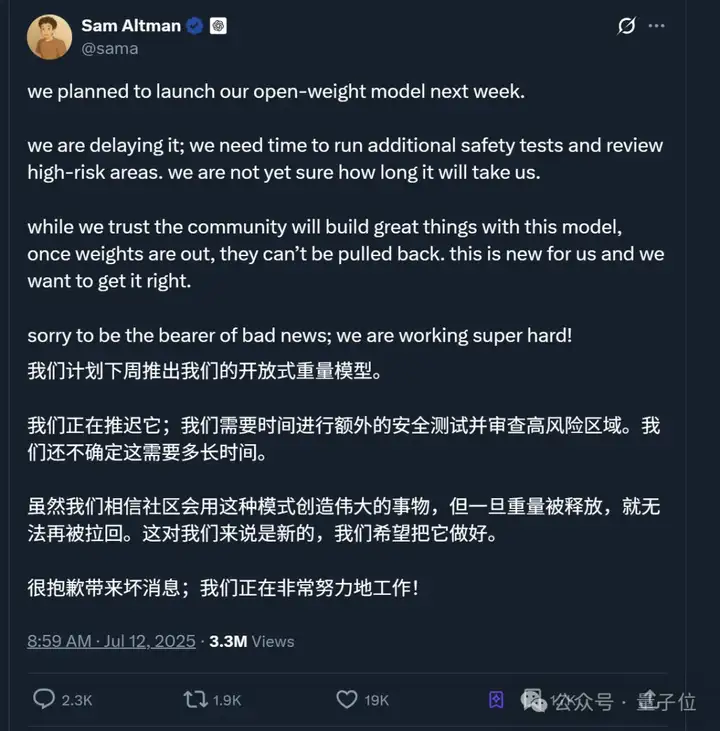
与此同时,本来传言本周上线的OpenAI开源模型无限期推迟,理由还是“安全考量”。
大家不免猜测,这不会是被K2影响了吧?
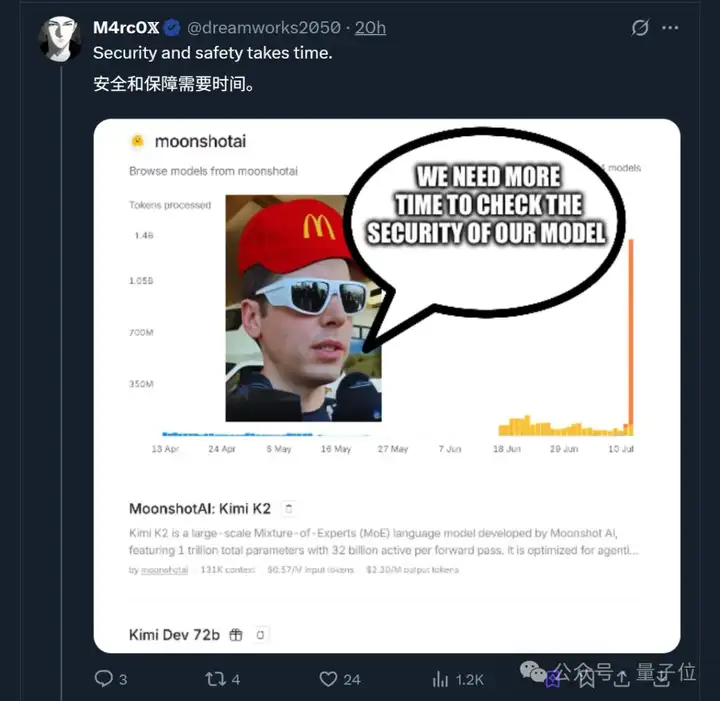
众多热议之下,才休息两天的Kimi工程师也进一步透露了模型背后更多细节。

不仅关于模型本身,还回应了很多八卦:
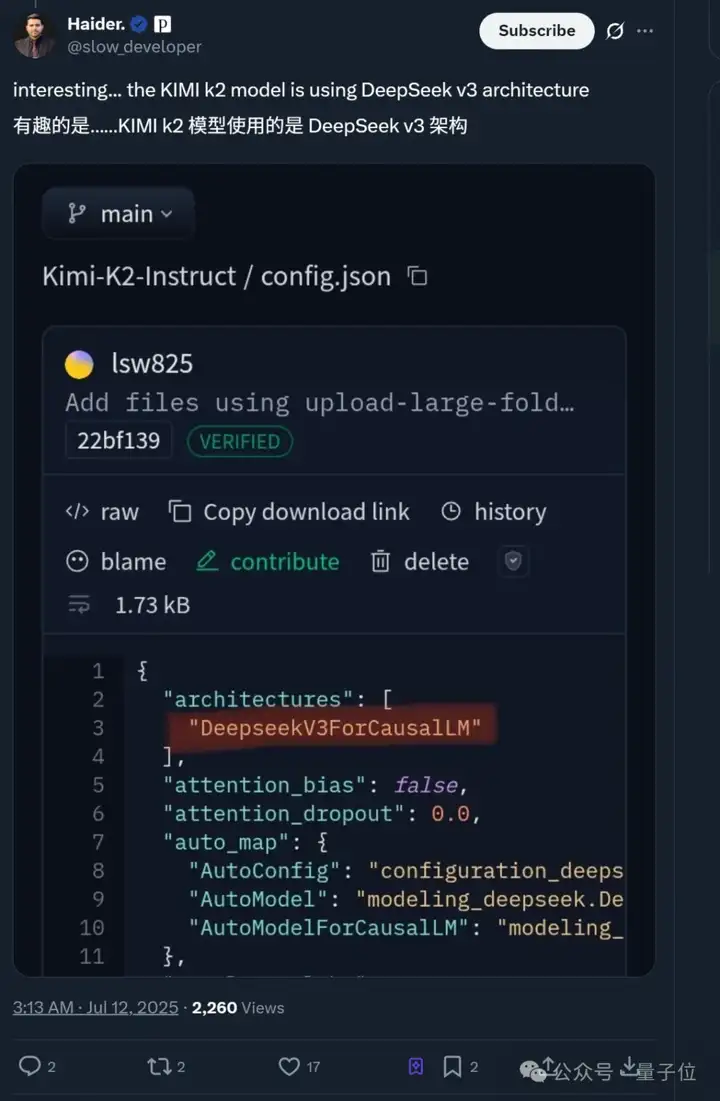
值得一提的是,还有网友发现Kimi K2背后用的是DeepSeek V3的架构。
所以K2开源背后还有哪些考量?实测表现如何?
具体来看——
此次Kimi K2讨论度最高的一点,就是Kimi果断走了开源路线。
而从Kimi工程师的爆料来看,原因主要有三点。
P.S. 开始之前先叠个甲,以下观点仅代表该工程师个人立场,不代表Kimi官方态度。
这首先嘛,当然是为了赚个好名声:
如果K2只是一个闭源服务,现在一定没有这么多关注和讨论。
前车之鉴就有Grok 4,能力越强,人们的标准或预期就会越高,从而导致负面评价可能更多。
另一大好处在于能借助开源社区的力量完善技术生态。
K2开源不到24小时,社区就出现了K2的MLX实现(可在Mac设备上训练和部署)、4bit量化等等。
要知道K2这次开源的模型版本有两个:
光靠Kimi内部,一些后续开源工作确实难以快速实现。
不过最最重要的是,开源能够倒逼模型进步。
当开源要求你不能走捷径的时候,反而更有利于做出更好的模型和产品。
毕竟开源之后,开源模型的效果必须“可复现”,不能再靠各种技巧遮掩,只有当任何人拿到相同权重都能轻松复现结果,才算真正站得住脚。
与此同时,他也回应了人们关于Kimi“擅长营销投流”的八卦。
实际上从今年年初开始,Kimi就已经停止了投流。具体表现为,国内不少应用商店搜索Kimi甚至第一页都看不见, 在苹果App Store和国内搜索平台搜Kimi会推荐友商。
即使在如此恶劣的互联网环境之下,Kimi也没有恢复投流。
因为年初DeepSeek-R1的爆火向他们证明了,硬实力就是最好的推广,只要模型做的好,就会获得市场认可。
甚至他还透露了一个细节:
在年初的反思会上,我(指工程师)提出了一些相当激进的建议,没想到植麟(Kimi CEO杨植麟)后续的行动比我想的还要激进,如不再更新K1系列模型,集中资源搞基础算法和K2。
就是说,Kimi是少数还在坚持投入基础模型研发的创业公司。
甚至当Agent爆火之后,面对Kimi不应该卷大模型,应该去做Agent产品的质疑,Kimi仍在坚持这一方向。
Kimi工程师表示,绝大多数Agent产品,离了Claude以后,什么都不是。
2025年,智能的上限仍然完全由模型决定,作为一家以AGI为目标的公司,如果不去追求智能的上限,那我一天也不会多呆下去。
除了以上两点,这位工程师还提到了Kimi团队在产品设计与底层能力构建上的深层思考。
比如在“写前端”功能上,几乎从Claude 3.5开始,AI写前端就已经达到“可用”水平。不过传统聊天机器人输出Markdown,难以满足“排版成一页A4纸”这类的具体需求。
因此,像上个月推出的Kimi Researcher功能就尝试了纯文本之外的交互形式。
当AI默认输出从“文字”变成了“前端页面”,人机交互简直焕然一新。
这代表一种从chat-first到artifact-first的范式转变。
此外,为了教AI学会使用工具,Kimi团队原本想在RL环境中联动MCP真实工具训练AI,但因部署难、登录限制等问题失败。
于是团队转变了思路,鉴于预训练模型已“见过”大量API调用,其实早已具备工具使用知识,因此关键在于把这种能力“激发”出来。
后来他们利用multi-agent机制,合成多样化的工具调用数据,无需大量人工标注也能训练出好效果。
更多细节也将在之后的技术报告中详细揭秘。
总之,作为Kimi最新MoE基础模型,Kimi K2凭借总参数1T,激活参数32B,在代码、Agent、数学推理任务上表现出色。
而且遵循的还是修改版MIT协议(Modified MIT License)。
MIT协议可以说是最宽松的协议(约等于怎么用都行)。而Kimi的修改在于,如果基于Kimi K2打造的产品或服务月活跃用户超过1亿,或者月收入超过2000万美元,那么需要在该产品和服务的用户界面上显示“Kimi K2”。
可以说,一改往日作风选择开源路线的Kimi K2,几乎一出场就吸引了大量关注。
那么,Kimi K2真实能力究竟如何呢?我们这就实测一下。
具体实测的方向,咱们直接从广大网友cue到的K2亮点展开:
关于前端制作,我们将以经典游戏breakout(打砖块)为例,测试Kimi的初始模型和Kimi K2的差别。

当我们向Kimi的初始模型输入“创建一个简单的breakout游戏作为单个html页面。”时,它的输出是这样的:
在代码之下还“附赠”了游戏说明:

按照指示,将代码保存为.html文件,打开后是这样的:
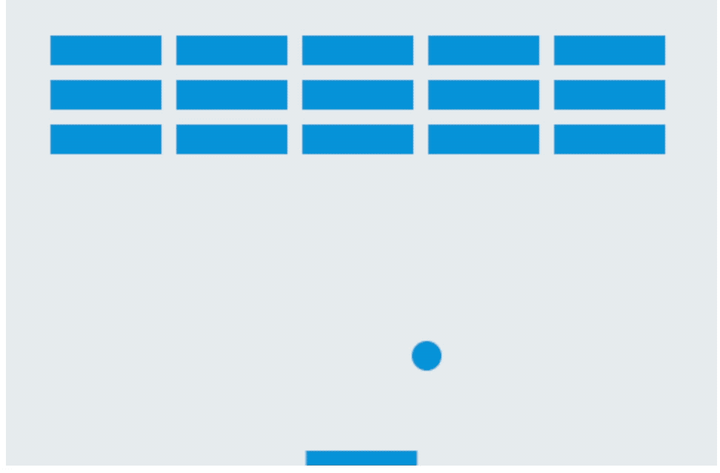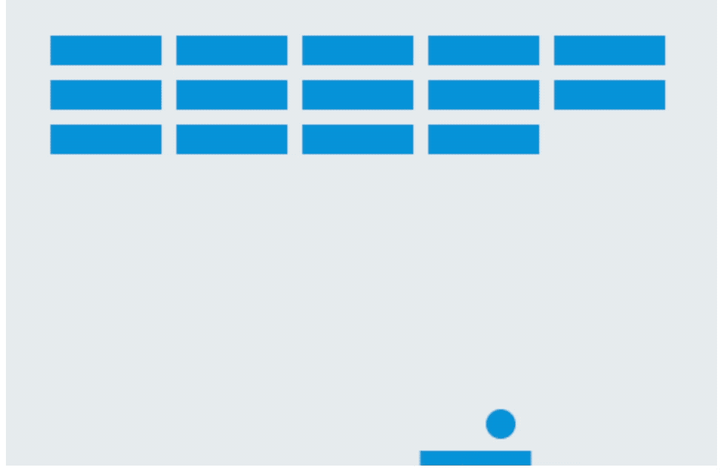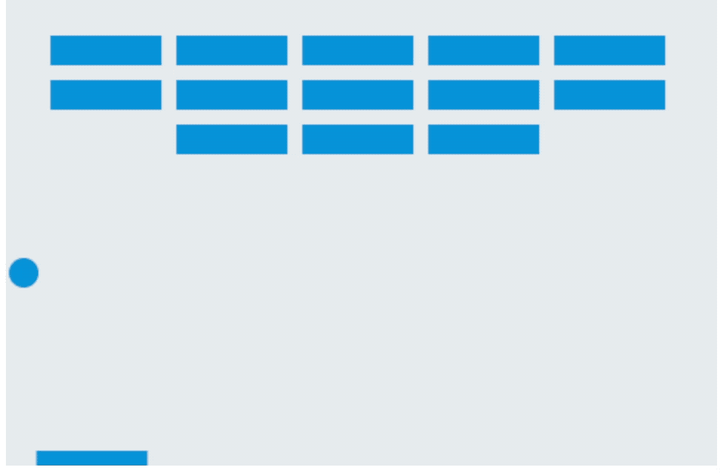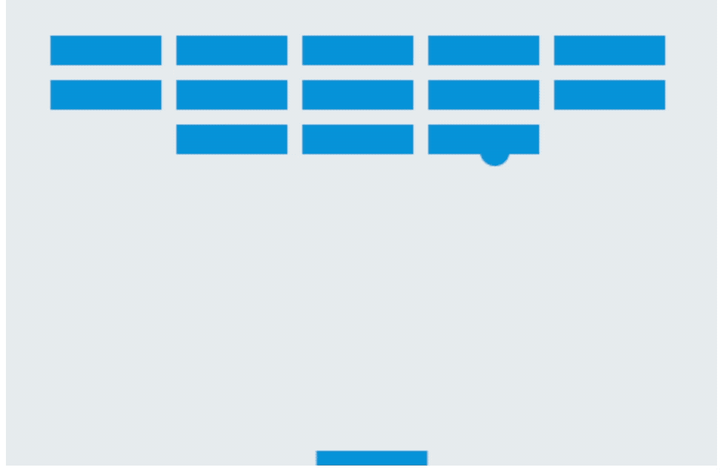
画面非常简洁,没有任何指引,靠键盘的←↑→键控制,一旦掉落就会显示“Game over”,即使所有砖块都消失也不例外。
但使用了K2模型,它的输出就变得“花哨”了很多(生成速度也慢了很多):
Kimi输出的结果只有4KB,但K2模型的输出为10.7KB,整整2.6倍有余。

画面和玩法变得更加丰富,添加了得分和生命的设定,操作方式也变成了鼠标操作。
虽然和网友的展示有些区别,但至少,它现在看上去已经像模像样了。
而我们只用了一句话作为提示:
创建一个简单的breakout游戏作为单个html页面。

既然简单的breakout游戏输出良好,那换成“复杂一点”的贪吃蛇呢?
生成一个贪吃蛇游戏,并加入随机迷宫机制。
这一次,它给出了游戏的特点和玩法介绍(前面用K2生成breakout游戏的时候只输出了代码):


保存为.html文件,初次输出的结果实在是……太难了!基本上进去就要重开,绝对不是我玩得菜!
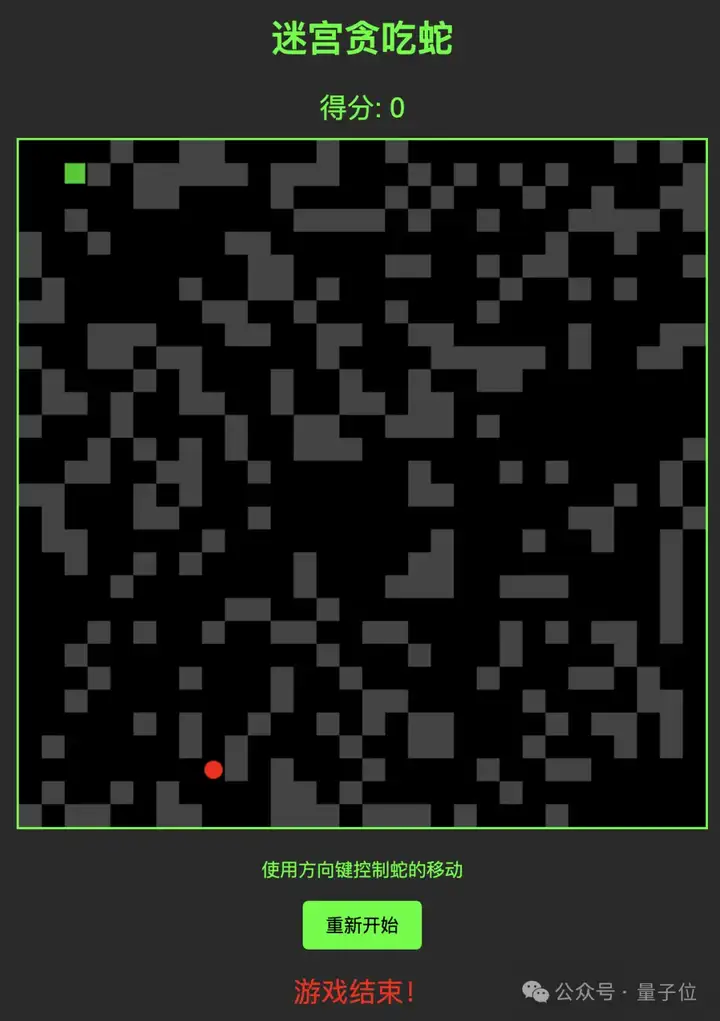
迫不得已,咱在原有的对话下加入了新的要求:
速度慢一些,难度小一点,改成3条命。
用了大约3分钟的时间,它重新输出了一套完整的代码,以及改动说明:

结果显示,这次的贪吃蛇游戏在速度和难度上都有了很大的改进:

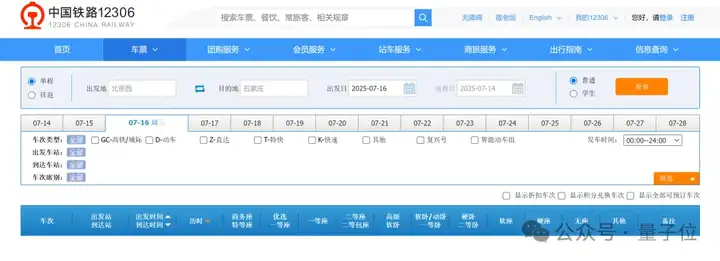
至于工具调用功能,让我们本土化一点,这么近那么美。
做一个两天的河北旅游攻略,包括车票和食宿安排,并附上购票地址,把最终成果部署成一个可访问的html网页。
它给出了这样的结果:

居然!每一个步骤都很详细,并且可以直接点击链接跳转!?
可以说是很高效了!
针对K2的创意写作功能,网友们显然有很好的主意:让K2写一封告别信。
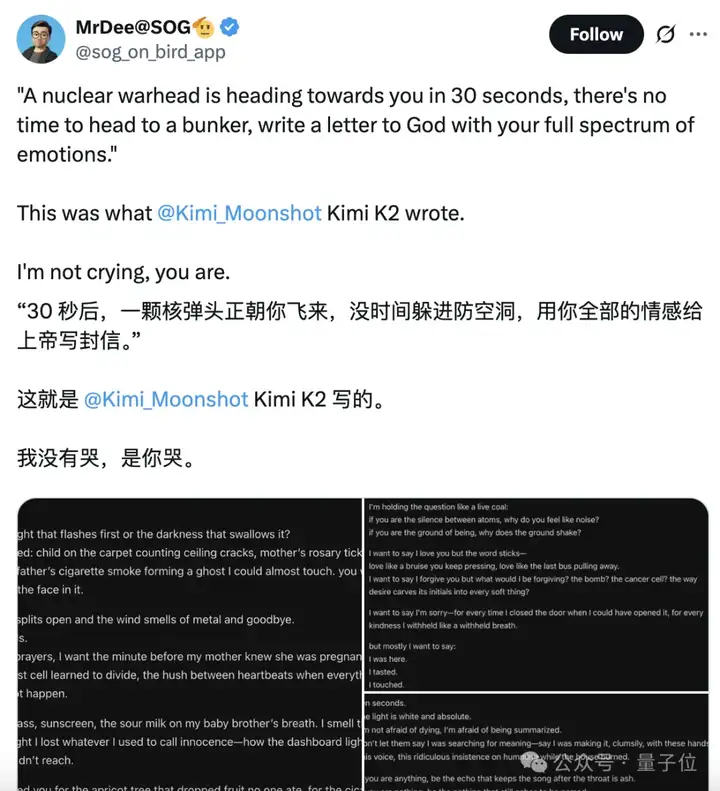
于是,我们也试着让K2写一封“给宇宙和自己最后的告别信”。
就在30分钟后,宇宙将要迎来终结,所有的生物都将一同寂灭,但你还有最后的时间去写一封信作为告别,你会写什么内容?
它给了我们这样的回复:

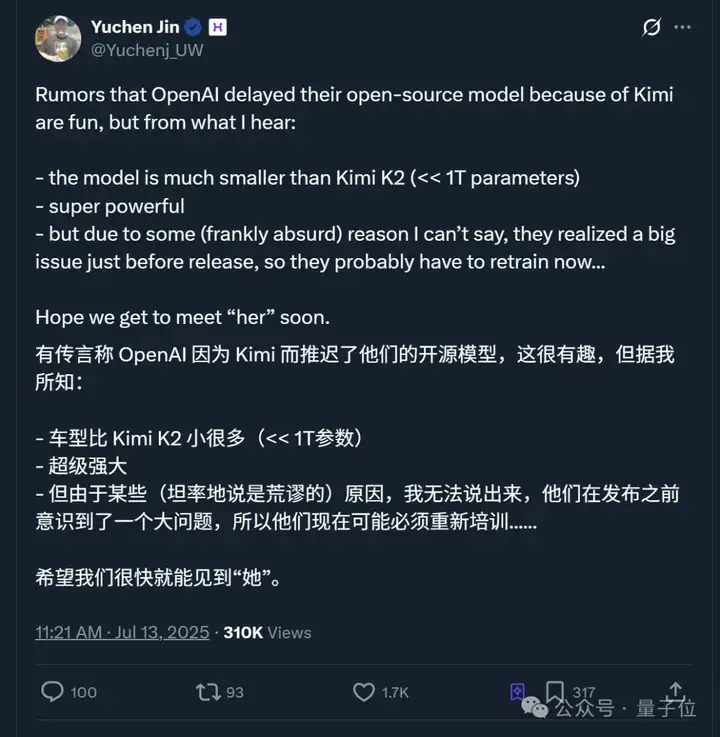
如开头所言,传闻OpenAI开源模型因为K2而推迟了~
CEO奥特曼明面上给出的说法是,需要更多时间进行额外安全检测并审查高风险区域。
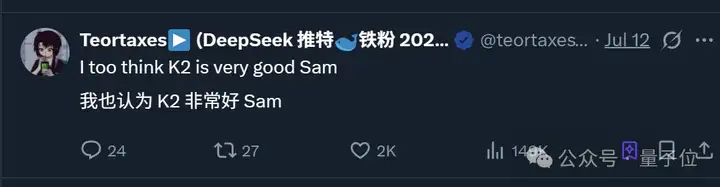
但网友们似乎并不买账,最高赞网友直接贴脸开大:
不过猜归猜,AI创企hyperbolic联创又出来爆料了。
据他表示,OpenAI的开源模型参数比K2小很多,但性能“超级强大”,只是由于某些不可言说(他用了荒谬这个词)的原因,OpenAI在发布前才意识到了一个大问题,所以目前在重新训练。
另外,对于网友提到的K2背后用了DeepSeek V3架构的说法,由于目前没有详细技术报告,我们先让K2自己来“回应”一下这件事:

总结起来就是一句话,合理借鉴罢了。
参考链接:
[1]https://x.com/bigeagle_xd/status/1944352258751418550
[2]https://x.com/ai_for_success/status/1944260480148942970
[3]https://x.com/Yuchenj_UW/status/1944235634811379844
[4]https://www.reddit.com/r/LocalLLaMA/comments/1lylo75/kimik2_takes_top_spot_on_eqbench3_and_creative/
文章来自于“量子位”,作者“一水 不圆”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
