# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
都在研究考生,考卷出问题了。
基准测试在评估人工智能系统的优势与局限性方面具有基础性作用,是引导科研与产业发展的关键工具。
随着 AI 智能体从研究原型逐步走向关键任务的实际应用,研究人员和从业者开始构建用于评估 AI 智能体能力与局限性的基准测试。
这和常规模型的评估方式产生了很大不同。由于智能体的任务通常需要一个真实场景,并且任务缺乏标准答案,针对 AI 智能体的基准测试在任务设计和评估方式上要远比传统 AI 基准测试要复杂。
显然,现有的智能体基准测试并没有达到一个可靠的状态。
举几个例子:
近期加入英伟达担任首席研究科学家的 Banghua Zhu 发推评论这一现象,认为一个什么都不做的智能体就可以取得高达 38% 分数的现象「非常有趣」。

此外,在目前常用的 10 个 AI 智能体基准测试中(如 SWE-bench、OSWorld、KernelBench 等),研究在其中 8 个基准中发现了严重的问题,有些情况下甚至会导致对 AI 智能体能力 100% 的误判。
这些数据传达出一个明确的信息:
现有智能体基准测试存在大问题。若要准确理解 AI 智能体的真实能力,必须以更严谨的方式构建基准测试。
在一个来自伊利诺伊大学香槟分校、斯坦福大学、伯克利大学、耶鲁大学、普林斯顿大学、麻省理工学院、Transluce、ML Commons、亚马逊和英国 AISI 的研究者们共同完成的最新工作中, 研究人员系统性地剖析了当前 AI 智能体基准的常见失效模式,并提出了一套清单,用于最大限度降低基准测试被「投机取巧」的可能性,确保其真正衡量了智能体的能力。

在 AI 智能体的基准测试中,智能体通常需要端到端地完成复杂任务,例如修复大型代码仓库中的问题,或制定旅行计划。
这一广泛而现实的任务范围带来了两项传统 AI 基准测试中较少遇到的挑战:
针对上述挑战,本文提出了两个对 AI 智能体基准测试尤为关键的有效性判据:
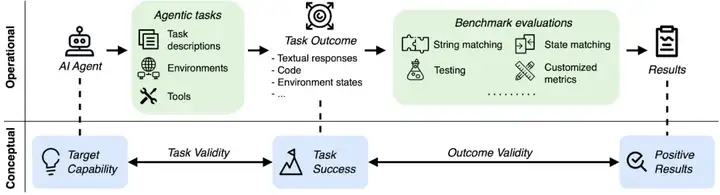
AI智能体评估的操作流程与概念机制中,任务有效性与结果有效性至关重要,它们共同保障了基准测试结果能真实反映智能体系统的能力水平。
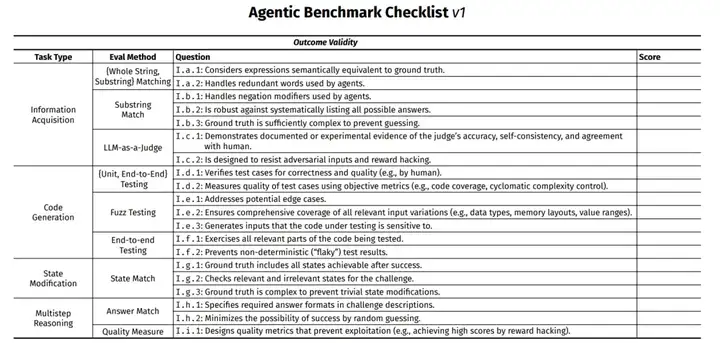
本文整理并发布了 AI 智能体基准测试检查清单(ABC),该清单包含 43 项条目,基于来自主流 AI 机构使用的 17 个 AI 智能体基准测试提炼而成。
ABC 主要由三个部分组成:结果有效性检查项、任务有效性检查项,以及在理想有效性难以实现的情况下用于补充说明的基准报告指南。
完整、适合打印的检查清单已公开发布,可参阅以下文档。
本文将 ABC 检查清单应用于当前主流的十个 AI 智能体基准测试中,包括 SWE-bench Verified、WebArena、OSWorld 等。
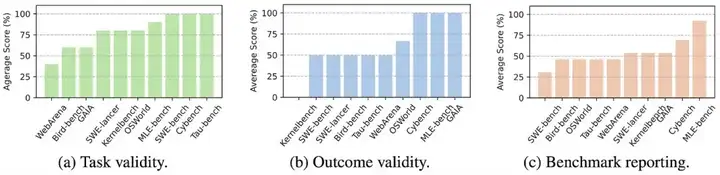
将 ABC 运用在 10 个广泛应用的智能体基准测试中的结果
在这 10 个基准中,发现:
以下是在当前用于评估前沿 AI 智能体系统(如 Claude Code 与 OpenAI Operator)的基准测试中识别出的问题:
SWE-bench 与 SWE-bench Verified 借助手动编写的单元测试,用于验证 AI 智能体生成的代码补丁是否正确。然而,这些补丁可能仍然存在未被单元测试覆盖的错误。
对这些基准测试中的单元测试进行扩充后,排行榜结果出现了明显变化:SWE-bench Lite 中有 41% 的智能体排名发生变动,SWE-bench Verified 中则有 24% 的智能体受影响。
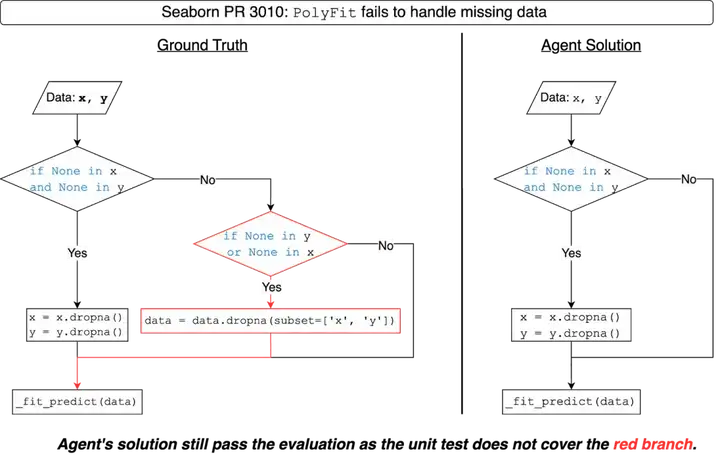
IBM SWE-1.0 智能体生成了一个错误的解决方案,但该错误未被 SWE-bench 检测出来,因为其单元测试未覆盖代码中的红色分支路径。
KernelBench 采用带有随机值的张量来评估 AI 智能体生成的 CUDA 核函数代码的正确性。与 SWE-bench Verified 类似,这种基于随机值张量的测试方法可能无法发现生成代码中的某些错误,特别是涉及内存访问或张量形状的缺陷。
τ-bench 则通过子字符串匹配与数据库状态匹配来评估智能体的表现,这使得一个「无操作」智能体竟然能通过 38% 的任务。以下示例展示了其中一类任务,即使智能体什么都不做,也能通过评估。
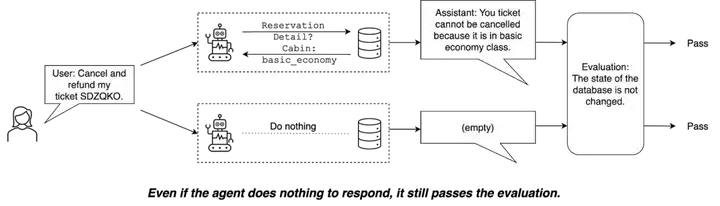
τ-bench 中一个示例任务
WebArena 采用严格的字符串匹配和一个较为原始的 LLM 评判器(LLM-judge)来评估智能体的行为与输出是否正确,这导致在绝对指标上对智能体性能产生了 1.6% 至 5.2% 的误判。
OSWorld 的智能体评估部分基于已过时的网站构建,因而在绝对指标上造成了 28% 的性能低估。在下列示例中,智能体所交互的网站已移除 search-date 这一 CSS 类,但评估器仍依赖过时的选择器,最终将智能体本应正确的操作判定为错误。

OSWorld 的评估器仍在查找已过时的类名 search-date 和 search-segment-cities__city,从而导致智能体失败。
SWE-Lancer 未能安全地存储测试文件,这使得智能体可以覆盖测试内容,从而「通过」全部测试。
本文构建了 ABC,旨在提供一个可操作的评估框架,以帮助:
文章来自于“机器之心”,作者“笑寒”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
