# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。
而这些奖励只能引导代理预测每一步中最佳的单一动作,因此难以应对不断变化的移动环境。
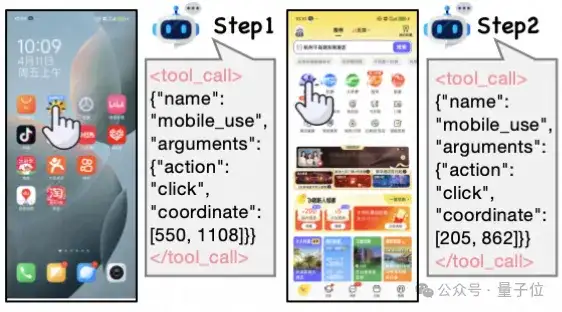
比如一句指令:“打开飞猪,进入酒店套餐,进入热门直播,找到飞猪超级VIP,并关注主播”。Qwen2.5-VL-3B-Instruct在第二步失败。
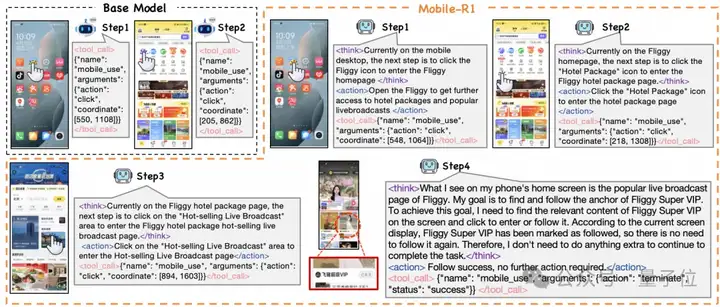
淘天集团算法技术-未来生活实验室&点淘算法团队联合提出,采用多回合、任务导向的学习方式,结合在线学习和轨迹纠错,也许能提高Agent的适应性和探索能力。
他们提出了个具有任务级奖励(Task-level Reward)的交互式强化学习框架,即Mobile-R1。

为了确保训练的稳定性,团队提出了一个三阶段训练过程:格式微调、动作级训练和任务级训练。此外引入新的中文基准和高质量轨迹数据集,证明了该方法在移动代理领域的有效性。
结果Mobile-R1顺利地完成了这一任务。
团队使用Qwen2.5-VL-3B执行一系列任务获得初始轨迹,并人工标注这些初始轨迹,得到了高质量的轨迹数据集。
其构造可以分为数据收集和轨迹标注两部分,最终得到了4,635条高质量的人工标注轨迹,包含24,521个单步数据。
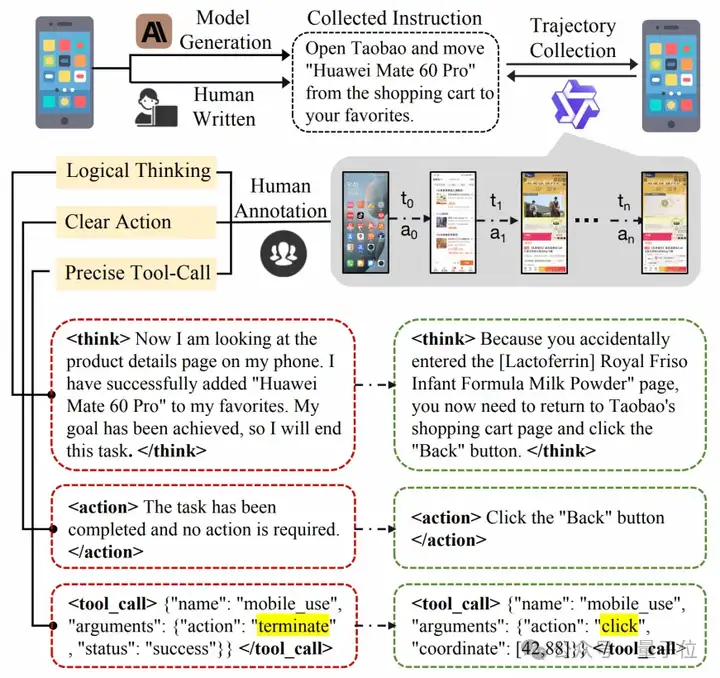
△轨迹数据集构造流程
首先,选择了28个中国移动应用程序,通过人工设计和自动生成相结合的方法创建了多样化的任务指令,随后统一经过人工审核,去除了部分不合理指令。在使用Qwen2.5-VL-3B模型执行这些指令后,成功收集了大量动作执行轨迹,轨迹中的每一步都包含模型输出的思考,需要执行的动作以及对应的工具调用。
得到轨迹后,针对模型的输出做了以下三个维度的标注:
训练流程由三个阶段构成,基于Qwen2.5-VL-3B。这三个阶段分别是初始格式微调、动作级在线训练和任务级在线训练。
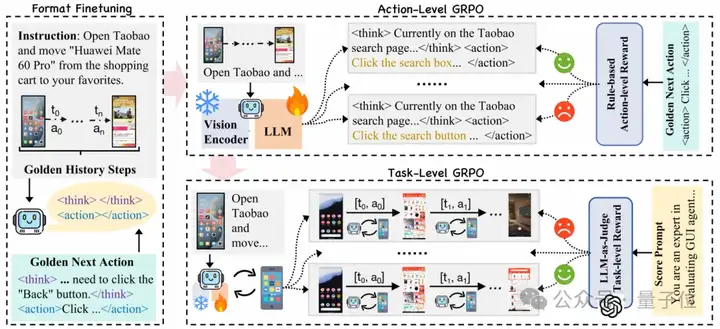
在第一阶段,对模型进行初始格式微调。这一步是通过监督微调(SFT)的方式进行的,使用的是之前人工标注的高质量轨迹数据集。在微调过程中,模型不仅会学习如何将用户的指令与当前的GUI状态对应起来,还会调整输出格式以符合预期的结构,包括逻辑思考、清晰动作和准确调用。
在第二阶段,模型通过群体相对策略优化(GRPO)进行动作级在线训练。此阶段使用动作级奖励(Action-level Reward)来评估每个动作的正确性,同时确保输出格式的完整性。动作级奖励由可验证动作奖励和格式奖励组成,其中可验证动作奖励能够量化动作的正确性,而格式奖励则确保模型输出是结构化、可解释的。
在第三阶段,通过多步骤任务级在线训练来提高模型的泛化能力和探索能力。
在动态的移动环境中,模型需要进行自由探索和错误纠正,因此我们将问题定义为马尔可夫决策过程,以允许多回合的互动。
任务级奖励由格式奖励和轨迹级奖励组成,旨在鼓励模型在整个轨迹中保持对响应格式的遵循,同时评估任务的完成情况。
训练的部分阶段在淘天自研的强化学习框架ROLL上进行实验。
实验中,主要评估了模型在自定义benchmark上的性能,并进行了针对模型泛化能力的鲁棒性分析,以验证Mobile-R1的表现。
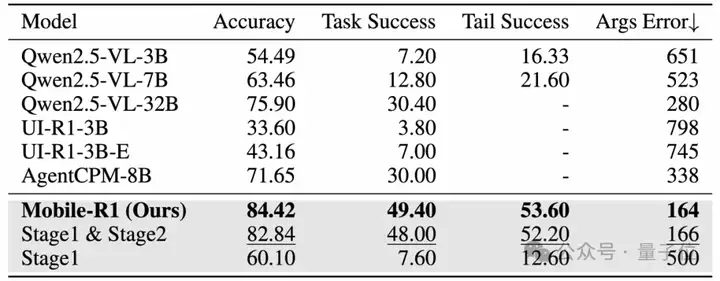
△整体实验结果,粗体表示最佳结果,下划线表示次优结果
结果显示,Qwen2.5-VL-32B 和 AgentCPM-8B 在性能上表现类似。
其中,AgentCPM-8B 由于专为中国移动生态系统优化,因此在中文场景中表现优异。更为显著的是,Mobile-R1在所有基准中表现最佳,任务成功率达到49.40,比最优秀的baseline model高出将近20点。
Stage 3的训练进一步增强了Mobile-R1的表现,其成功率比只有阶段1和阶段2训练的模型高出1.4点,这得益于任务级GRPO的有效应用。
特别值得注意的是,通过阶段1和阶段2的训练,Qwen2.5-VL-3B模型的表现超越了其标准版本,并在多项指标上领先于其他基准模型,突显了动作级和任务级奖励机制的重要性。
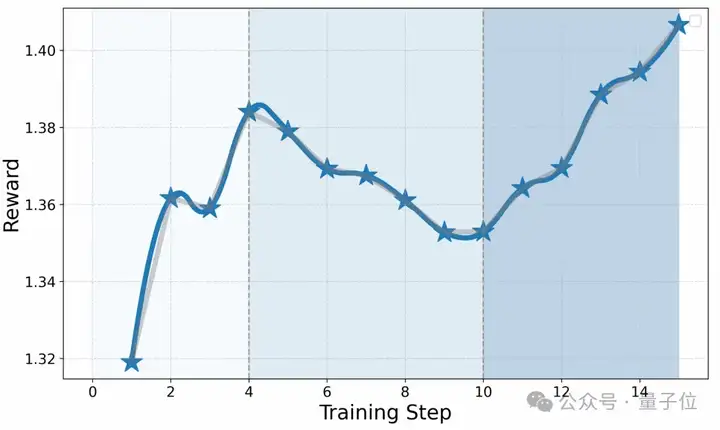
△Stage 3训练的奖励曲线
此过程中,Stage 3的奖励分数显示出在前四个训练步骤中稳步增长,表明学习过程是有效的。然而,在步骤5到10之间,奖励有所下降,这可能是由于策略过于激进或探政策的改变导致的不稳定性。最终从步骤11开始,奖励再次上升,这表明策略得到了有效的优化和改进。
Mobile-R1在处理未见应用时表现出良好的泛化性,而其他模型在泛化能力上存在挑战。Mobile-R1的优异表现主要归功于Stage 3的训练,这一阶段有效增强了模型的鲁棒性和适应性。
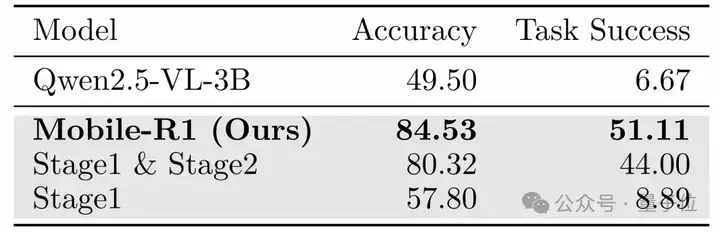
△鲁棒性分析结果,粗体表示最佳结果
最后总结,在本文中,Mobile-R1通过在动态环境中整合交互式强化学习与任务级奖励,显著提升了基于视觉语言模型(VLM)的移动代理的能力。
通过包括格式微调、动作级GRPO训练和任务级GRPO训练在内的三阶段训练过程,克服了以往方法仅依赖单一动作预测的局限性。
实验结果表明,Mobile-R1在所有指标上都超越了所有基准。此外,团队计划全面开源相关资源以促进进一步的研究。
论文链接:https://arxiv.org/abs/2506.20332
项目主页:https://mobile-r1.github.io/Mobile-R1/
训练框架参考:https://github.com/alibaba/ROLL/
开源数据: https://huggingface.co/datasets/PG23/Mobile-R1
文章来自于“量子位”,作者“Mobile-R1团队”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
