# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
埃默里大学团队推出首个覆盖8个真实任务、带有人类解释真值的视觉解释基准Saliency-Bench,统一评估流程与开源工具让显著性方法可公平比较,获KDD’25接收,为可解释AI奠定透明、可靠的基石。
深度学习模型的「黑盒」问题一直是AI发展的瓶颈,而基于显著性图的视觉解释是打开这个黑盒的关键钥匙。
然而,由于缺乏带注释的数据集和标准化的评估方案,整个领域的发展受到了限制,「如何科学、统一地评估这些解释的质量?」成了一个亟待解决的问题。
为此,埃默里大学的研究团队推出了一个旨在全面评估视觉解释的开创性基准Saliency-Bench,该基准不仅构建和标注了涵盖场景分类、癌症诊断、行为识别等8个不同任务的多样化数据集,还提供了一套标准化的评估流程和开源工具包,让研究人员可以轻松复现、比较和迭代。

论文链接: https://arxiv.org/abs/2310.08537
项目主页: https://github.com/yifeizhangcs/XAIdataset.github.io
在多家主流模型和方法上的大量实验证明,Saliency-Bench为衡量XAI方法的忠实性和对齐性提供了坚实的基石,推动了可解释AI向着更可靠、更透明的方向发展。
该研究获得KDD 2025 Datasets and Benchmarks Track接收,提出首个全面评估视觉解释的开创性基准Saliency-Bench。
深度神经网络(DNNs)在图像分类等任务中取得了巨大成功,但其「黑盒」特性使其决策过程难以捉摸,这在医疗、金融等高风险领域是不可接受的。
可解释AI(XAI)技术,特别是通过生成「显著性图」(saliency map)来高亮模型决策关键区域的方法,已成为提升模型透明度的重要途径。
然而,长期以来,对这些XAI方法的评估存在三大挑战:
为了解决这些问题,Saliency-Bench应运而生,不仅仅是一个数据集集合,更是一个完整的视觉解释评估生态系统。
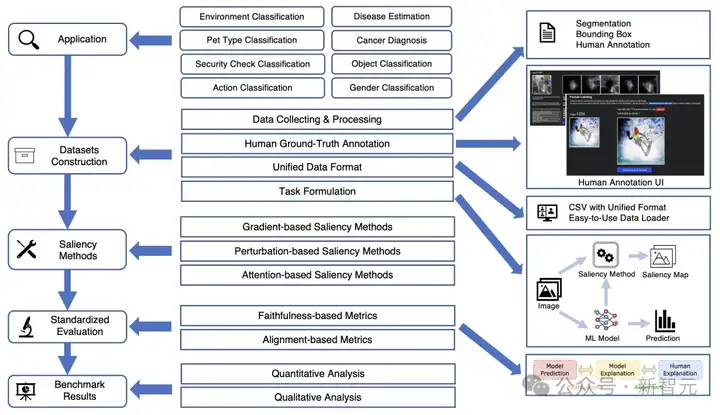
Saliency-Bench框架概览图,展示了Saliency-Bench的整体框架。从多样化的应用场景出发,涵盖了数据集构建、多类型显著性方法、标准化评估(包含忠实性和对齐性指标)到最终基准测试结果的完整流程。
Saliency-Bench的核心贡献可以总结为四点:
Saliency-Bench最大的亮点之一就是其前所未有的数据集广度和深度。研究人员通过人工标注、利用先验知识(如前景提取)等多种方式,为8个来自不同领域的公开数据集制作了高质量的像素级解释真值(ground-truth)。
八大数据集示例图
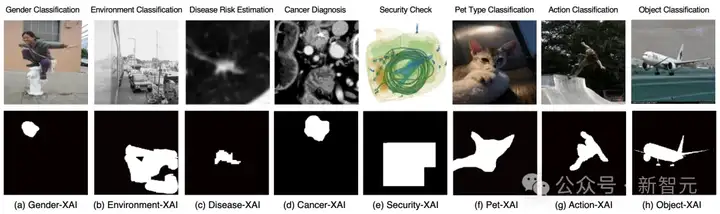
来自Gender-XAI, Environment-XAI, Disease-XAI, Cancer-XAI, Security-XAI, Pet-XAI, Action-XAI, 和 Object-XAI 这8个数据集的示例图片及其对应的像素级真值解释
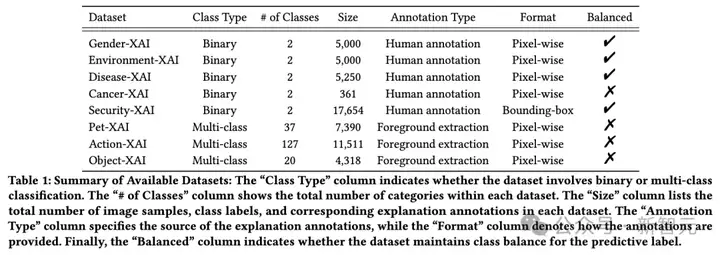
8个数据集的类别(二分类/多分类)、类别数量、样本总数、标注类型(人工标注/前景提取)和数据格式等关键信息
谁是最好的视觉解释方法?用数据说话!
研究人员选取了6种主流的显著性方法,在ResNet-18, VGG-19和ViT-B/16等不同架构上进行了全面的性能评测。评估指标兼顾了两个核心维度:
对齐性 (Alignment):生成的解释与人类认知的真值有多接近?(使用 mIoU 和 Pointing Game (PG) 指标)
忠实性 (Faithfulness):生成的解释是否真实反映了模型的决策依据?(使用 iAUC 指标)
实验结果亮点
没有「万金油」方法:不同方法在不同任务和模型上表现各异。总体而言,RISE 和 GradCAM/GradCAM++ 在多个数据集中表现相对稳健和可靠。
模型架构影响显著:通常,在 ResNet-18 上的解释质量要优于 VGG-19,这可能得益于其更先进的架构设计。
ViT注意力机制潜力巨大:Vision Transformer的自注意力图作为一种内生的解释方法,表现出了强大的竞争力,尤其在捕捉全局和长距离依赖关系方面,其生成的显著性图比传统CNN方法更精细。
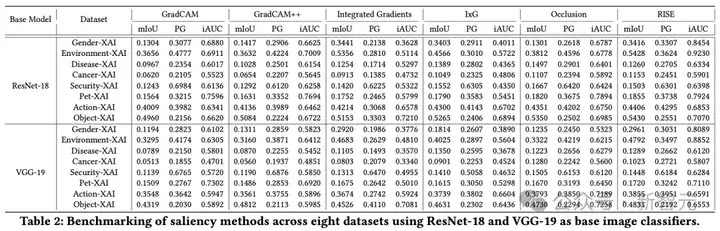
主流方法在ResNet-18和VGG-19上的详细评测结果,展示了6种显著性方法在8个数据集上,基于ResNet-18和VGG-19模型的mIoU, PG, iAUC三项指标的详细得分。
研究人员推出了Saliency-Bench,一个为视觉解释评估提供全面数据集、标准化流程和开源工具的综合性基准测试套件。 通过对多种主流方法和模型的广泛测试,为社区提供了一个可靠的平台来衡量和比较XAI技术和视觉解释的性能。
Saliency-Bench的发布将有效遏制当前XAI评估中的「各自为政」现象,为开发更忠实、更可靠的视觉解释方法提供坚实的基石,最终推动可解释AI在更多关键领域的应用落地。
参考资料:
Yifei Zhang, James Song, Siyi Gu, Tianxu Jiang, Bo Pan, Guangji Bai, and Liang Zhao. 2025. Saliency-Bench: A Comprehensive Benchmark for Evaluating Visual Explanations. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD '25).
文章来自于“新智元”,作者“LRST”。



