# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。
但有一个非常本质的问题始终萦绕着研究者的心头:这些模型是真的“理解”了视频,还是仅仅在进行一种高级的“模式匹配”?
为了解决上述问题,来自南洋理工大学S-Lab的研究者们提出了一个全新的、极具挑战性的基准测试——Video Thinking Test(简称Video-TT)。
其核心目标简单而深刻:将“看”与“想”的能力分离,精准测量AI在视频内容上的真实理解和推理水平。

研究团队有三项关键发现:
(1)人类在视频理解的“准确率”和“鲁棒性”上远超SOTA级模型(50%),差距显著。
(2)开源模型在“鲁棒性”上远逊GPT-4o(SOTA模型之一)。
(3)GPT-4o的短板在于:对模糊或非常规内容识别能力弱;对多场景区分、定位、计算能力有困难;世界知识对应能力欠缺,无法理解意图、社会动态等深层信息。

Video-TT图灵测试集由南洋理工大学S-Lab科研团队联合独立研究员共同研发完成。主要作者包括南洋理工大学博士生张元瀚、董宇昊,二人的研究方向聚焦多模态模型;通讯作者为南洋理工大学助理教授刘子纬。
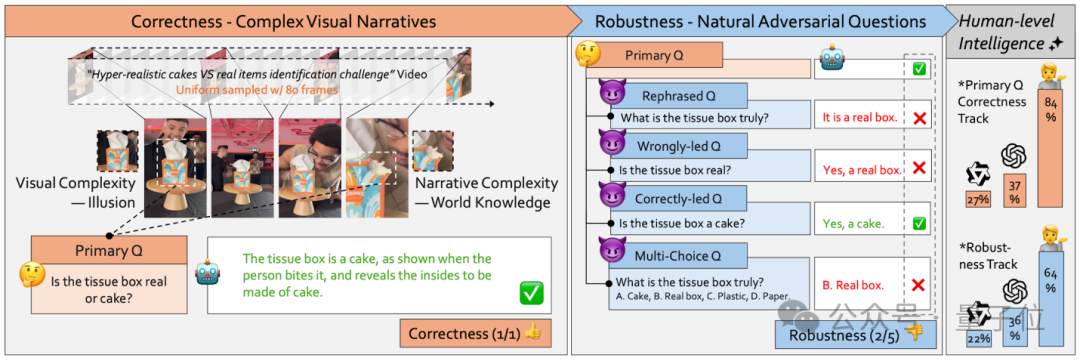
人类的智慧核心在于其正确性(Correctness)和鲁棒性(Robustness)。
正确性意味着我们能准确地解读信息,而鲁棒性则保证了我们在面对信息干扰、歧义或不同表述时,依然能保持正确的判断。这两者结合,才构成了真正可靠的理解能力。
现有的视频理解基准测试(Benchmark)在衡量AI是否达到人类级智慧上存在着一些根本性的缺陷。它们往往无法区分模型是因为“没看清”而犯错(即关键视频帧采样不足),还是因为“没想明白”而出错(即缺乏真正的推理能力)。
这种混淆使得我们很难评估AI在视频理解上的真实水平。
在Video-TT出现之前,视频理解领域已有相应的评测标准,但这些标准普遍存在一定局限性,导致AI的真实能力无法被准确衡量。
问题一:长视频评测的“帧采样悖论”
近期,许多研究都聚焦于长视频理解。然而由于计算资源限制,模型无法处理视频的每一帧,只能“跳着看”(稀疏采样)。
这就带来一个问题:当模型答错时,我们无法确定是它能力不行,还是运气不好,恰好错过了包含答案的关键帧。
如下图所示,在一些长视频评测中(如VideoMME-Long),即便是强大的GPT-4o,其性能也可能因为采样帧数的限制而大幅下降。这种下降反映的更多是“采样策略”的失败,而非“理解能力”的不足。
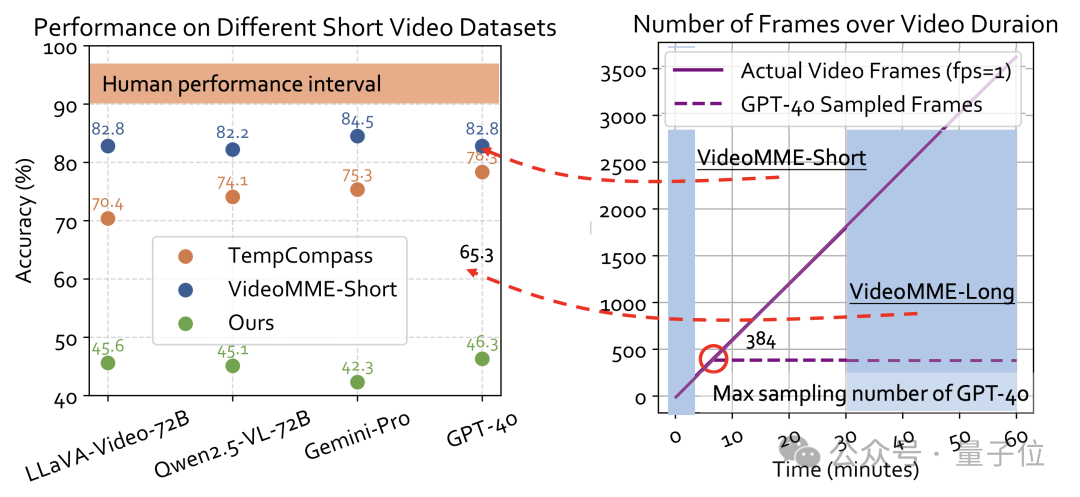
问题二:短视频评测的“天花板幻觉”
与长视频相对,短视频评测(如VideoMME-Short)由于时长较短,模型可以几乎“看完”所有帧。在这种情况下,一些顶尖模型的表现接近甚至达到了人类水平(上图左侧),这容易给人一种“短视频理解问题已被基本解决”的错觉。
然而,事实远非如此。Video-TT的研究者们认为,即便在信息密集的短视频中,依然存在大量需要深度推理和复杂认知才能解决的挑战。简单地提升准确率分数,并不能证明AI拥有了与人类同等的智慧。
Video-TT的破局创新点在于,它选择了1000条全新的YouTube短视频(避免数据污染),并精心设计问题的标注,确保答案能在有限的、统一的80帧内找到。
这样一来,所有模型都在同一起跑线上“看”素材,评测的焦点便从“如何有效采样”转移到了“能否深刻理解”上,从而拨开迷雾,直击AI的“思考”核心。
要衡量“思考”,就必须提出能够激发“思考”的问题。Video-TT的设计原则是,一个复杂的问题并非由其类型决定(如“物体颜色”vs“情节理解”),而是由其背后的上下文、原因和场景决定。
研究团队从“认知科学”和“影视叙事学”中汲取灵感,构建了两个核心的复杂性维度:视觉复杂度和叙事复杂度。
维度一:视觉复杂度(Visual Complexity)
这部分关注的是视频画面的内在挑战,共包含四个方面:
维度二:叙事复杂度(Narrative Complexity)
这部分关注的是视频作为一种“故事”的表达方式,其内在的逻辑和深度,同样包含四个方面:
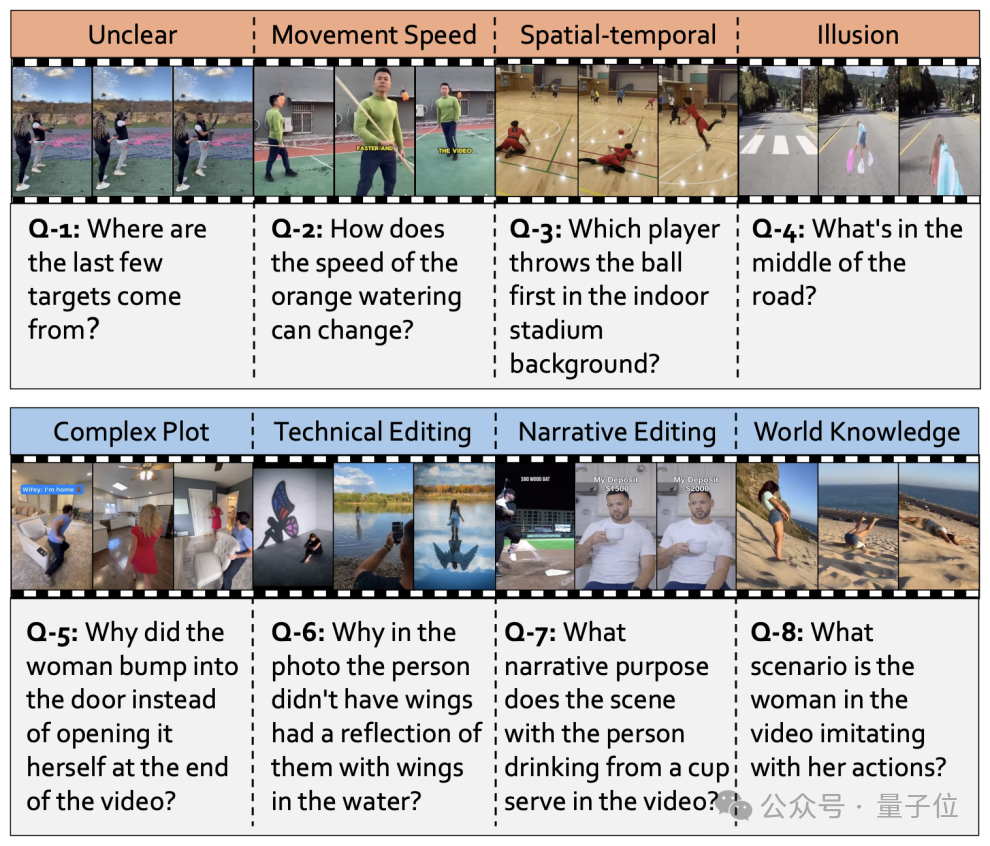
例如,上图中的Q-8提问“视频中的女士在模仿什么行为?”,这需要观众拥有关于“特定活动”(被子弹击中后倒下)的世界知识才能正确回答。这些问题迫使模型超越简单的物体识别,进入真正的推理(Reasoning)层面。
拥有了能让AI“思考”的难题还不够,我们还需要知道它的思考有多“鲁棒”(Robustness)。一个鲁棒的模型,不应该因为用户表述的方法稍有改变就给出截然不同的答案。
为此,Video-TT为每一个核心难题(Primary Question)都配备了四种“自然对抗性问题”(Natural Adversarial Questions),形成一套完整的测试体系。

这五种问题类型分别是:
只有当模型能够准确回答核心问题(正确性),并且在面对各种“变体”提问时仍能保持判断一致(鲁棒性),我们才能说它达到了真正的、类人的理解水平。
经过如此严苛的设计,Video-TT的评测结果揭示了一个惊人的事实:目前的SOTA模型,在视频思维能力上,与人类相比仍有巨大鸿沟。
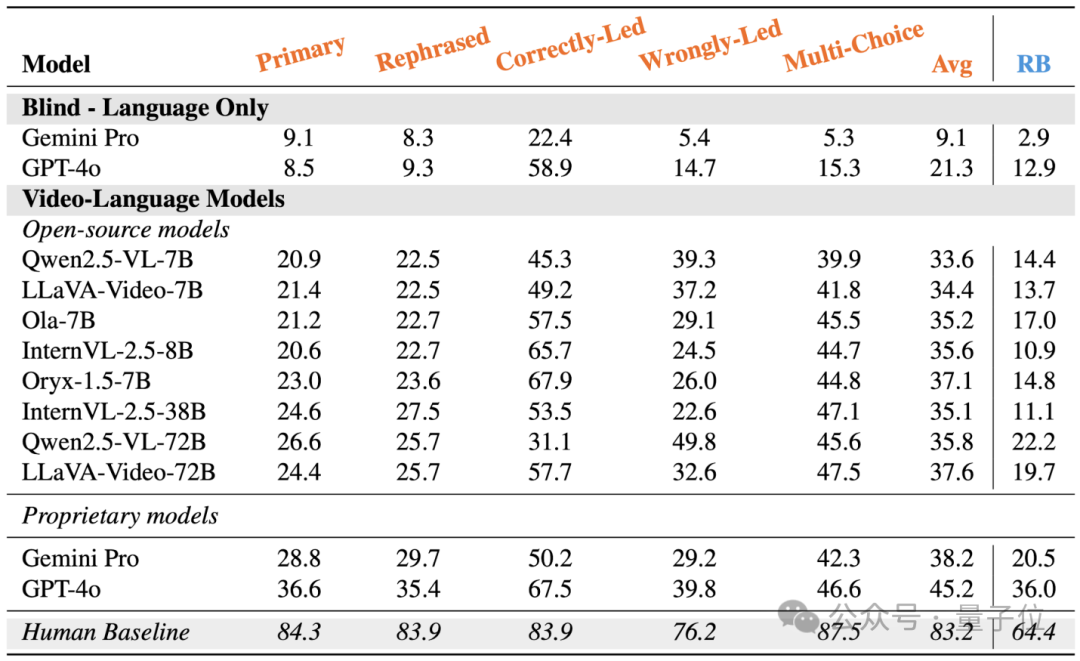
从数据中可以清晰地看到:
这一巨大的分数差距有力地证明,当前的AI在真正成为AGI的道路上,尤其是在视频理解这一核心领域,依然任重而道远。
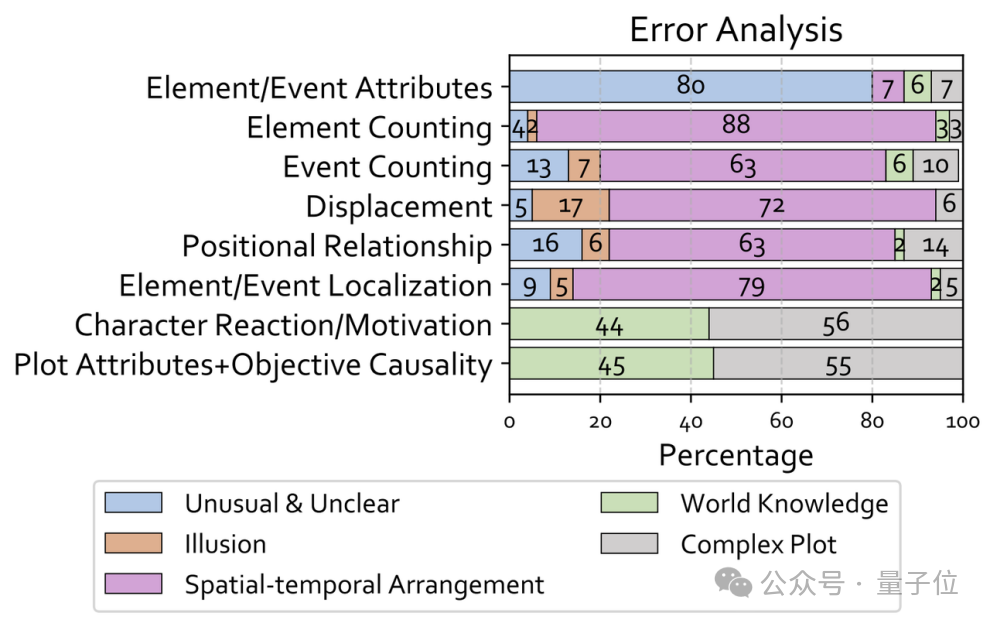
对AI的错误类型进行分析。可以看出,“复杂情节”(Complex Plot)和“世界知识”(World Knowledge)是导致模型在高级认知任务中失败的主要原因。
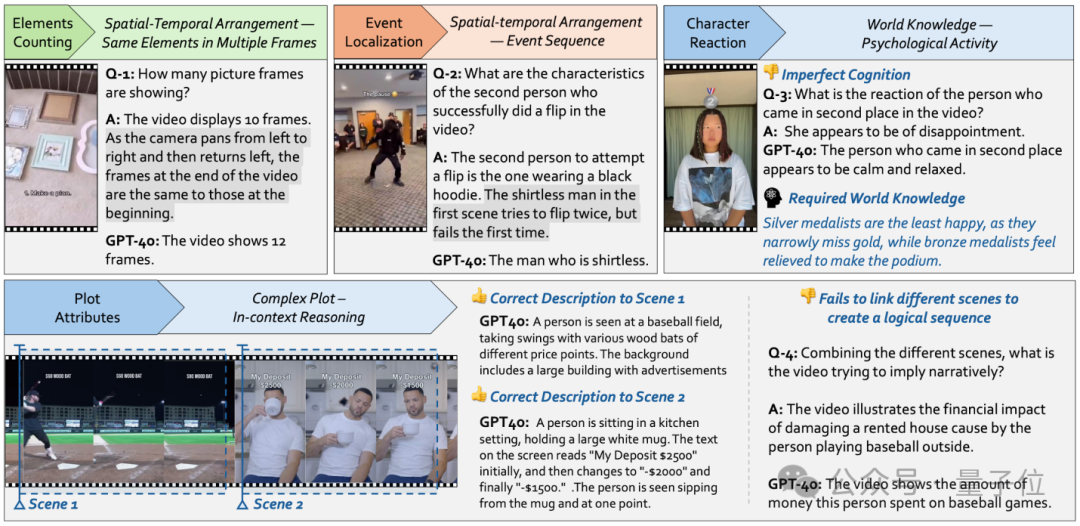
Video-TT的作者们对GPT-4o的错误答案进行了深入的定性分析,发现了三大核心弱点:
弱点一:时空混淆——“理不清”时间与空间
在需要理解时空关系的任务中,模型错误率极高。
弱点二:常识缺失——“看不懂”言外之意
许多错误源于模型缺乏人类社会和文化中的常识(World Knowledge)。
弱点三:复杂情节理解失败——“串不起”故事线
当视频叙事需要跨场景、跨线索进行逻辑推理时,模型往往会“掉线”。
Video-TT这一评测基准提示相关研究者,在看到AI技术进步的同时,也需留意其存在的不足,该领域的探索仍需不断深入。
论文链接:https://arxiv.org/abs/2507.15028
数据集:https://huggingface.co/datasets/lmms-lab/video-tt
项目主页:https://zhangyuanhan-ai.github.io/video-tt/
文章来自于微信公众号“量子位”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
