# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
推理大模型(Large Reasoning Model)极大的促进了自然语言处理领域的发展,而信息检索领域的核心问题之一是文档排序,如何利用强大的推理大模型通过主动推理来判断文档的相关性,进而再对文档进行排序是一个值得探索的方向。
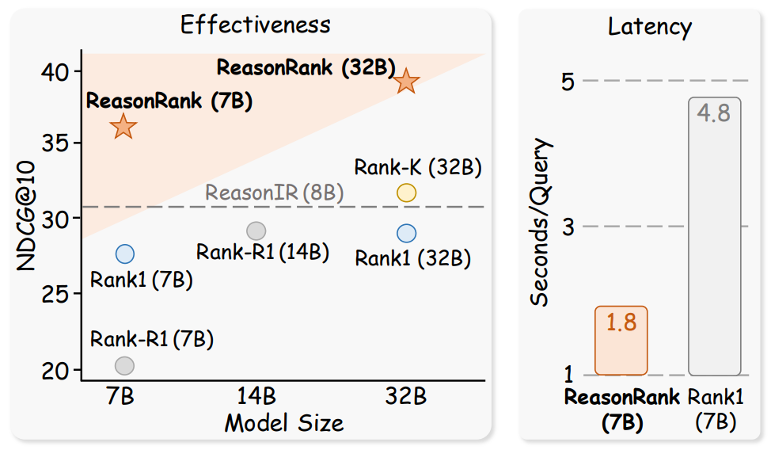
在本次工作中,我们提出了 ReasonRank,ReasonRank 在包括 BRIGHT、R2MED 在内的多个榜单,击败了 UMASS 大学,Waterloo 大学,Meta 在内的多个大学和机构,于 2025 年 8 月 9 日荣登榜单第一名。我们更小尺寸的 ReasonRank-7B 也远远超越了其他 32B 大小的推理型排序大模型,同时相比 pointwise 排序器具备明显的效率优势。此外,我们的论文还获得了 Huggingface paper 日榜第一名。
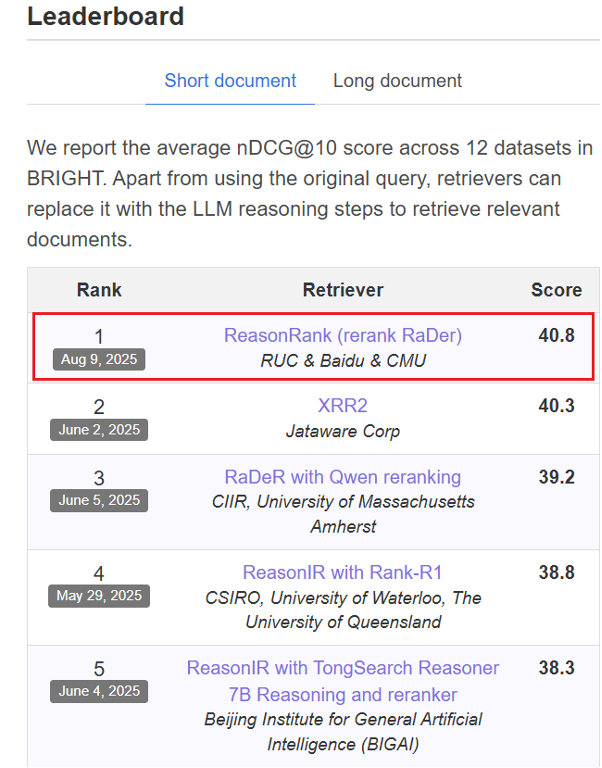
图 1:8 月 9 日,ReasonRank 在 BRIGHT benchmark 上荣登榜单第一名

近来,test-time reasoning 已经被证明能够提升文档排序器的排序效果。其通过在给出最终排序结果前,先显式进行一系列推理过程(查询理解,文档比较等等)。然而,由于推理密集型(reasoning-intensive)排序训练数据的稀缺,现有推理型排序器均依赖 MSMARCO 这种传统 web 搜索数据进行训练。
这些数据主要侧重简单的语义或词匹配,导致模型在面临复杂搜索场景(如 StackExchange 复杂查询、代码类查询、数学类查询等)时泛化能力受限。而使用人工标注构造推理密集型排序训练数据代价又是非常高的。
为破解推理密集型排序训练数据稀缺的问题,我们提出了基于 DeepSeek-R1 的自动化数据合成框架,生成了 13K 高质量的推理密集型 listwise 排序训练数据。基于合成的训练数据,我们进一步设计了一个两阶段的训练框架包括 Supervised Fine-Tuning (SFT) 和 Reinforcement Learning (RL)。在 RL 阶段,不同于以往仅使用排序指标作为奖励(reward),我们基于 listwise 排序中滑动窗口策略的特性设计了 multi-view ranking reward,其更适合 listwise 排序。
1. 数据合成
传统模型在复杂排序任务上表现差,主要是由于缺少面向复杂推理搜索场景的训练数据的缺失。根据已有的 IR benchmarks,我们将复杂搜索查询分为四大类并收集了对应领域的用户查询:
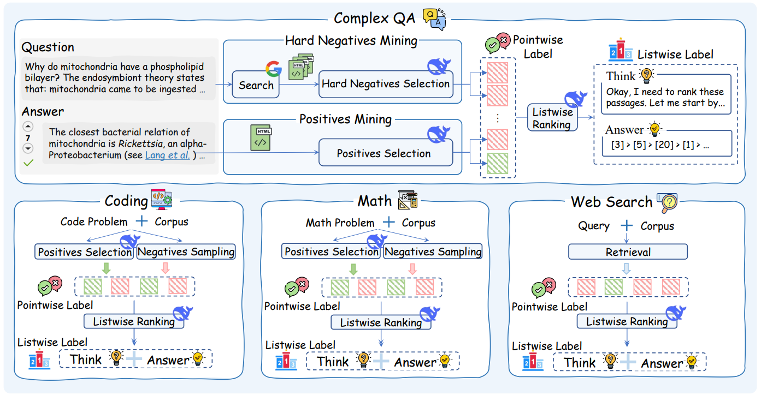
有了查询,如何挖掘高质量的候选文档列表以及构造训练 label 是一个关键问题,其直接影响模型训练的效果。
在本文,我们提出利用强大的 DeepSeek-R1 从海量的 web 页面和已有的文档 corpus 挖掘其相关文档以及不相关文档(包含难负例)。在这个过程,我们还给 R1 提供了 query 的人工标注的正确答案来提高挖掘的准确性,相比传统蒸馏,这样能够进一步提升 R1 相关性判断的准确性。
这样我们便得到了文档的 pointwise 训练标签(相关 / 不相关)。为了训练最终的 listwise 排序器,我们继续利用 DeepSeek-R1 对候选文档进行 listwise 排序,得到 listwise 训练标签(包含推理链以及最终的 gold ranking list)。
为了提升训练数据的质量,我们进一步设计了一个自一致性(self-consistency)数据过滤机制。
我们利用得到的 pointwise 标签对 listwise 标签中的 gold ranking list 计算排序指标 NDCG@10,小于阈值 α 的数据将被过滤掉(表明教师模型 R1 判断不一致,相应数据样本被丢弃),最终我们得到 13K 高质量的多领域训练数据集。
2. 两阶段训练
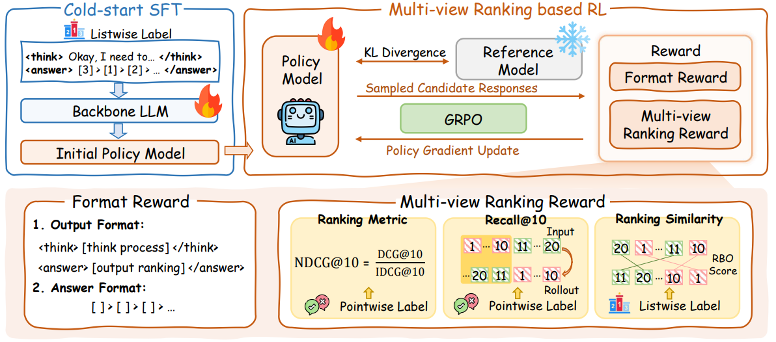
阶段一:冷启动 SFT
在获得高质量的推理密集型训练数据后,我们首先采用监督微调对大模型进行 “冷启动” 训练,通过 R1 的推理链显式引导模型学习如何对一组文档进行对比、推理和排序。具体而言,输入由用户查询和对应的候选文档列表组成,输出为 listwise label(也即 R1 生成的推理链和 gold ranking list)。
阶段二:多视角排序 reward 的强化学习
多视角排序 reward
1) 召回视角(Recall@10):
现有方法在强化学习训练排序任务中,通常只采用单轮的 NDCG@10 作为奖励信号。然而,我们认为这种单轮奖励对于多轮滑动窗口的 listwise 排序任务而言是次优的。这是因为滑动窗口策略要求模型在排序时进行多轮、序列化的局部决策:每一步窗口内的前 10 个文档才会被传递给下一个排序窗口,并通过滑动窗口不断迭代,实现整体排序。此时,单独优化每一窗口的 NDCG 指标,并不一定能够带来全局最优的排序效果。基于上述观察,我们在强化学习奖励设计中,额外引入了 Recall@10 指标来确保重要文档不会在滑动过程中被遗漏,有助于后续窗口获得更优的排序基础。
2) 排序相似度视角(RBO):
此外,相较于基于 pointwise 标签计算 NDCG@10,我们认为 listwise 训练标签的 gold ranking list 能够提供更细粒度的排序信号。因此,我们引入 RBO(Rank-biased Overlap)指标,作为补充排序奖励,用于衡量当前排序结果与金标准排序的相似性。
我们将 NDCG@10、Recall@10 和 RBO 结合,构建了多视角排序奖励:
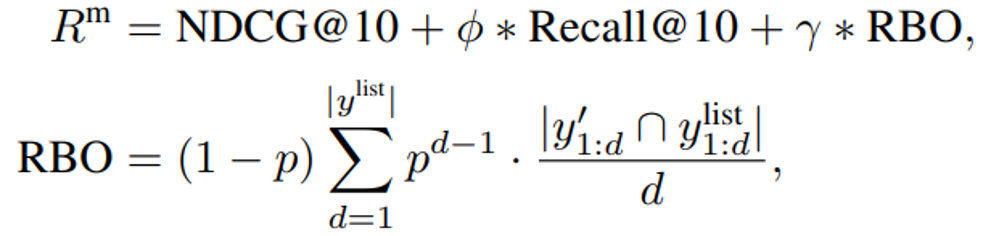
格式 reward
为了保证正确的输出格式,我们考虑了两种格式:
(1)输出格式:保证输出内容嵌套在 <think> 和 < answer > 标签中;
(2)答案格式:<answer > 标签内的排序列表要满足特定的输出格式(例如:[4] > [2] > …)。
最终,我们的强化学习 reward 计算如下,我们使用 GRPO 算法进行 RL 优化。

为充分评估 ReasonRank 在不同推理型搜索任务上的效果,我们选取了两个推理型 IR benchmark:
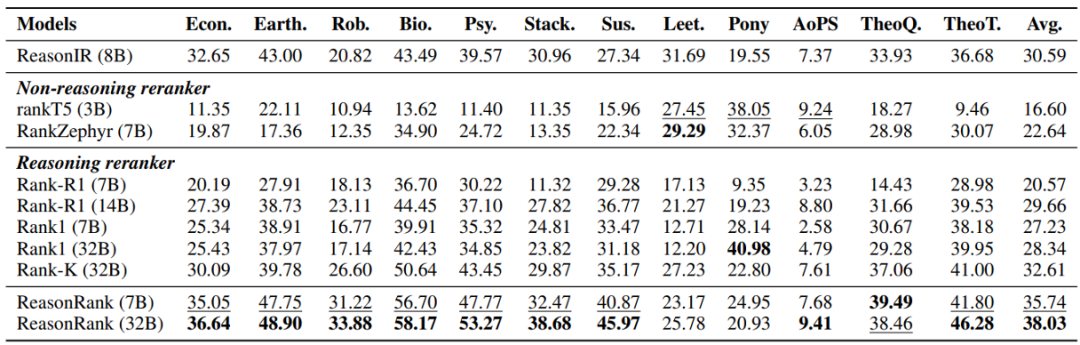
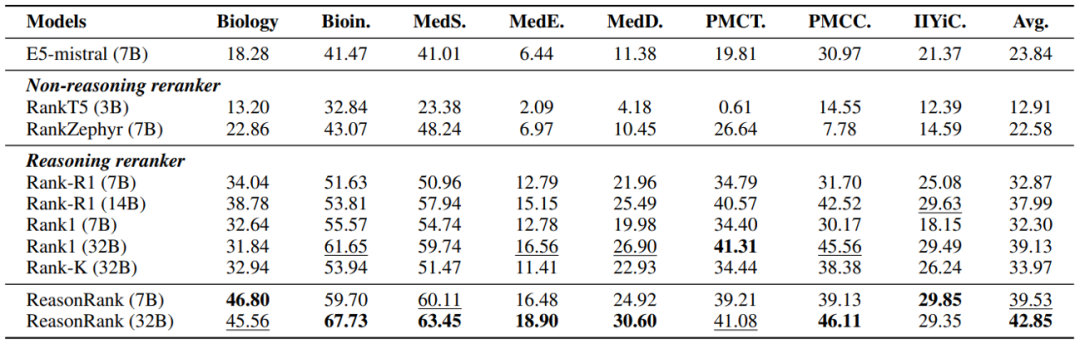
从实验结果可以发现:ReasonRank 显著优于已有的排序器。ReasonRank(32B)在 BRIGHT 和 R2MED 上分别超越最好的 baselines 4-5 个点;且 ReasonRank(7B)甚至优于所有的 32B 的 baselines。
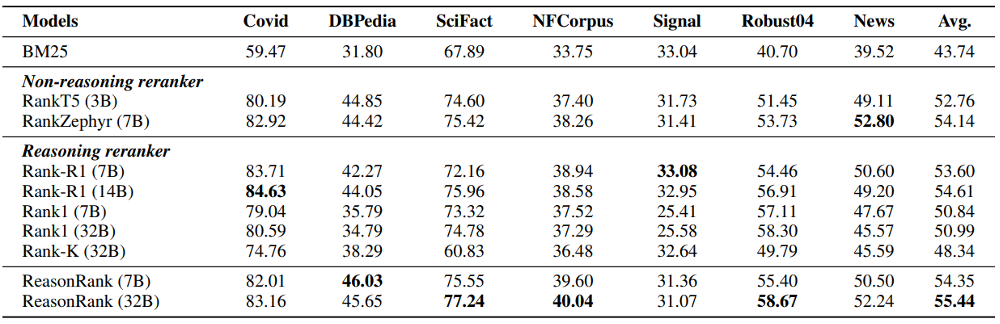
此外,我们还在传统 IR benchmark BEIR 上开展了实验,结果证明了其良好的泛化性。
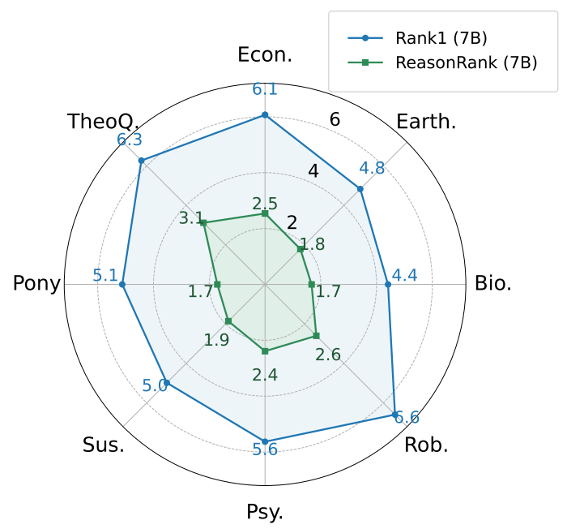
我们还在 BRIGHT 上测试了 ReasonRank 的排序效率,并与推理型 pointwise 排序器 Rank1 比较。在以往,pointwise 排序器被认为是最高效的。然而,推理场景下,我们发现我们的 listwise 排序器 ReasonRank 效率显著高于 pointwise 排序器 Rank1。这种高效性来自于 Rank1 需要为每个段落生成推理链,而 ReasonRank 一次处理 20 个段落,只生成一条推理链,大大减少了输出的 token 数量。
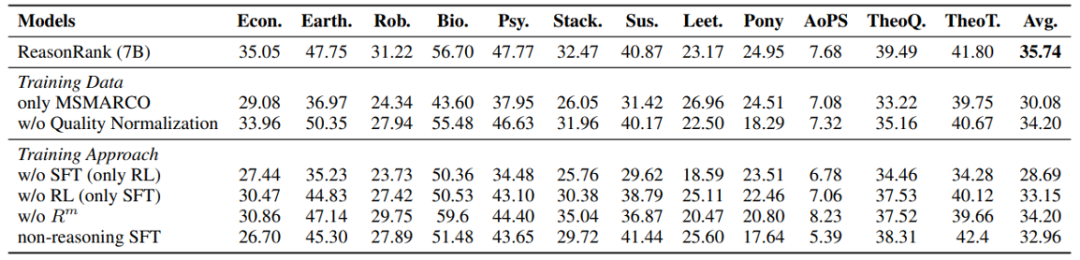
我们还开展了详尽的消融实验,结果证明了我们构造的多领域数据集相比于单领域(MSMARCO)的效果优势以及我们两阶段训练框架和 multi-view ranking reward 设计的合理性。
我们在本文提出了多领域面向推理型排序的训练数据,解决了训练数据上的难题。并设计了合理的 SFT 和 RL 训练方法,充分激发了推理型排序器的效果。未来,如何基于大模型的推理能力继续提升搜索排序器的效果,我们认为仍有多个方向值得探索:
文章来自于微信公众号“机器之心”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
