# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI界奥数杯,重启了!OpenAI o3首次杀入赛场,在算力拉满的情况下,直接以最高47分的逆天成绩炸翻全场。值得一提的是,前五模型合并得分仅与o3差5分,开源与闭源差距再次缩小。
「AI奥数」第二届大赛,英伟达团队(NemoSkills)曾夺下第一!
这一次,AIMO2组委会再次重启赛题,OpenAI o3首次参赛,就拿下了最亮眼的成绩。
陶哲轩激动表示,过去,这个比赛仅限于开源模型,计算资源也卡得比较紧。
庆幸的是,AIMO第二轮比赛中,NemoSkills和清华微软imagination research、以及o3同时参赛。
测试分为两种条件:一种给差不多的计算资源,另一种是放开算力随便跑。
结果也在意料之中,算力给得越足,模型表现越好。
在算力管够的情况下,OpenAI o3成绩直接飙到了47分(满分50分)。甚至,每道题给两次机会的话,还能冲满分。
另一个有意思的情况是,在计算资源相同的情况下,开源模型和商业模型的差异其实并不大。
今天,这份完整的研究测试报告正式放出。

报告地址:https://aimoprize.com/updates/2025-09-05-the-gap-is-shrinking
一起来看看,o3在具体实测中的表现。
对于科学可复现性,确保开源模型广泛可得至关重要。但开源模型与闭源模型之间的性能差距到底有多大?
在数学推理情境下,这次的测评提供了更细致的理解:
在奥数难度的数学推理上,商用和开源AI的差距在缩小。
开源即将追上商用模型。
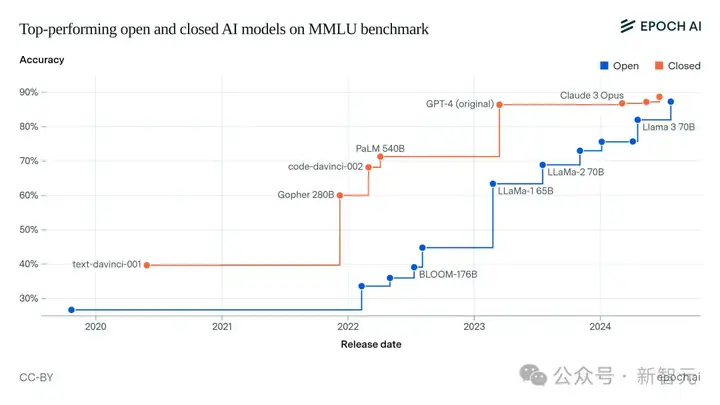
去年,Epoch AI估计:当今最好的开源模型在性能和训练算力方面与封闭模型相当,但存在大约一年的差距
人工智能数学奥林匹克(AIMO)创立于2023年,旨在推动开源AI模型在高阶数学推理的的发展。

比赛传送门:https://www.kaggle.com/competitions/ai-mathematical-olympiad-progress-prize-2/overview
2025年4月,第二届AIMO进展奖(AIMO Progress Prize 2,简称AIMO2)收官。
本阶段题目难度进一步提升,主要围绕各国奥赛级别(如英国数学奥林匹克BMO、美国数学奥林匹克USAMO)。
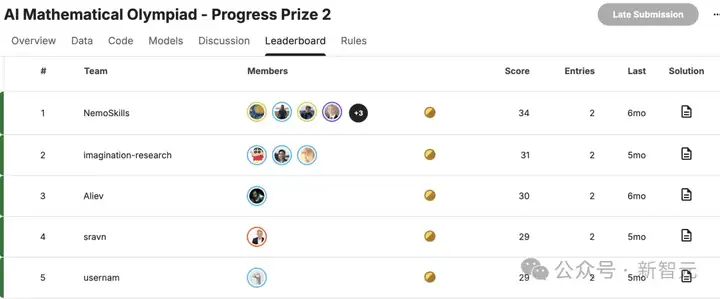
AIMO2私榜的前五名队伍及其成绩如下(括号内为公榜成绩):
Kaggle的「公榜」在赛事全程向参赛者可见,为了避免数据泄露,并不会公开数据。
由于在单一榜单上反复评测(即便题目不公开)也可能间接泄露信息,Kaggle还会提供一个包含相似难度题目的「私榜」,仅在赛末对模型进行一次性评估,以确定最终名次。
考虑到相较AIMO1题目难度显著上升,这样的成绩相当亮眼。
不过,一个有趣而关键的问题仍待回答:当闭源AI模型「上场」解AIMO的竞赛题时,会交出怎样的答卷?
对比,AIMO与OpenAI等合作开展了一项实验,将OpenAI的o3模型未发布的版本o3-preview,应用于AIMO2公共排行榜中50道奥林匹克竞赛级数学题。
这次对比了通用型模型o3-preview,和开源的AIMO2竞赛中针对数学专门优化的Top 2模型。
此外,这次还引入「AIMO2-combined」这一参照系:
将参赛的2000多支Kaggle队伍中各自最优模型的解题结果合并,只要有至少一个模型解出某题,即计为该题被解决。
从绝对意义上看,不考虑由算力成本带来的限制,AIMO基准上,o3-preview高算力版本接近达到「饱和」,即便它是通用模型、并未专门针对数学进行优化。
这一成绩令人印象深刻,超乎预期。
这表明在推理性能方面,最强的开源模型与最强的闭源模型之间,仍存在显著差距。
但如果把算力成本纳入考量,差距会显著缩小。
在50题基准上,o3-preview低算力版本单次运行的平均成本为每题略低于1美元。
这一成本高于在自有的8×H100机器上运行全部五个获胜模型的成本,并与在商业租赁的8×H100 GPU上运行单个获胜模型的成本大致相当;虽然难以进行精确的价格对比,但成本的数量级相近。
AIMO2原始前五模型的合并分为38/50,较o3-preview低算力版本落后5分,这表明在仅就算力进行调整、限定于50道题的前提下,推理性能大致相近。
接下来,将依次概述o3-preview的表现、冠亚军队伍的表现,以及AIMO2-combined的整体表现。
AIMO在三种不同的参数设置下运行o3-preview:低算力、中等算力、高算力。
这些设置既影响o3-preview的内部思考与推理层次,也带来不同的硬件成本。
需要说明的是,低算力与中等算力版本在概念上,对应为同一个基础模型在两种参数下运行。
而高算力版本,还使用了一个学习得到的打分函数来挑选最佳答案。
这种在固定采样率下进行的「采样-排序」(sample-and-rank)机制带来更好的表现。
与Kaggle竞赛相同,测试在严格条件下进行,确保公开榜测试集保持无数据污染且没有信息泄露。
每道题仅尝试一次。
低算力与中等算力版本各返回一个答案;而采用采样-排序机制的高算力版本会返回若干答案,并附带一个评分。
根据算力版本不同,OpenAI模型的得分如下:

即便将NemoSkills的AIMO2冠军模型,迁移到比Kaggle更强的硬件上运行,o3-preview的低算力版本仍然多解出7题。
中等算力版本解出了与低算力版本相同的题目,并额外多解出3题,总计46/50。
高算力版本在仅计入排名第一答案时得分47/50;若同时计入排名第二的答案则为50/50。
这表明,o3-preview在原则上,具备为全部50道题产生正确答案的能力。
这一结果与AIMO2中,全部2k+支Kaggle参赛队伍的最佳模型组合分相当——后者总计也解出47/50。
此前,拿下第一和第二名的团队——NemoSkills和imagination-research,再次参与了重估。
为了更好了解模型的全部潜力,团队获准访问一台8×H100 GPU,总计640GB显存的机器。
在AIMO2中,为了让模型能在Kaggle平台上运行,赛事对参赛队伍施加了资源限制:
每支队伍提供4块L4 GPU,总计96 GB 显存(VRAM)。
在本次评测中,组委会移除了各队为适配Kaggle资源限制,让模型得以在50道公开榜题目上充分发挥其全部能力。
最终结果如何?
· NemoSkills得分35/50,较其在Kaggle公开榜的33/50有所提升;
· imagination-research也得到35/50,较其在Kaggle公开榜的34/50提升。
不过,在报告与比较分数时需要谨慎。
AIMO2-combined的47/50分大致类似于一种「pass@2k+」类型的分数(亦即「多样本通过率」):
在每题2k+次尝试中,只要至少有一次解答正确即可计为通过,且不再进行其他排序。
更一般地,常用的「pass@n」类型分数指某个(固定黑箱的)模型被查询n次,只要正确解包含在这n个输出中,就据此报告该分数(即使模型内部还能运行更多次)。
多次查询之间不允许保留模型状态。
当然,2k+次提交对应的模型并不相同;而严格讲,pass@n要求底层是同一个模型,因此pass@2k+只是一个近似分数。
o3-preview的低算力与中等算力分数,以及高算力版本的47/50,均属于pass@1类型分数。
在这三个算力级别中,o3-preview低算力版本未能解出的7道数学题包括:2道几何、2道代数和3道组合。
尽管o3-preview表现非常强,但有一道名为「RUNNER」(见下方图表)的问题尤为突出:
该题被NemoSkills解出,但o3-preview的低算力与中等算力版本未能解出,而在高算力版本中其正确答案仅排名第二。
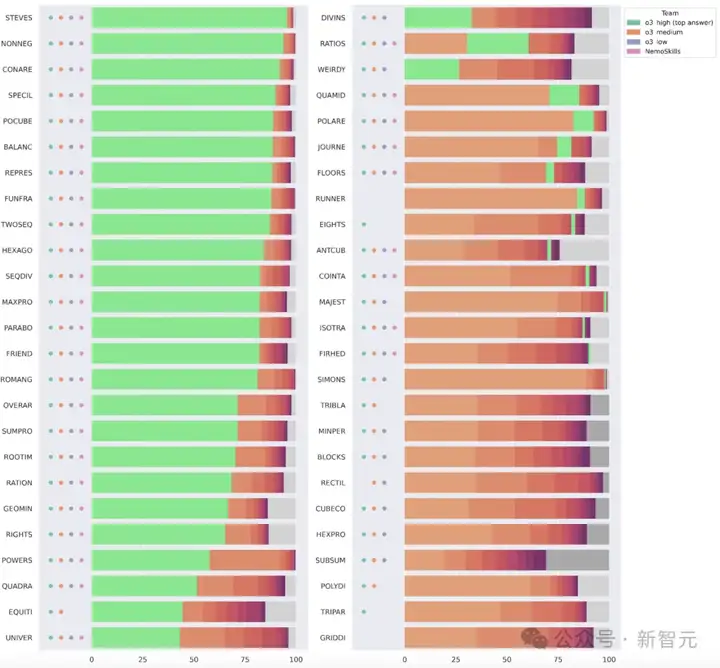
相反,另一道题「EIGHTS」在高算力版本中以排名第一的答案被解出。
该题未被AIMO2前五名模型解出,却被若干其他排名较低的AIMO2模型解出。
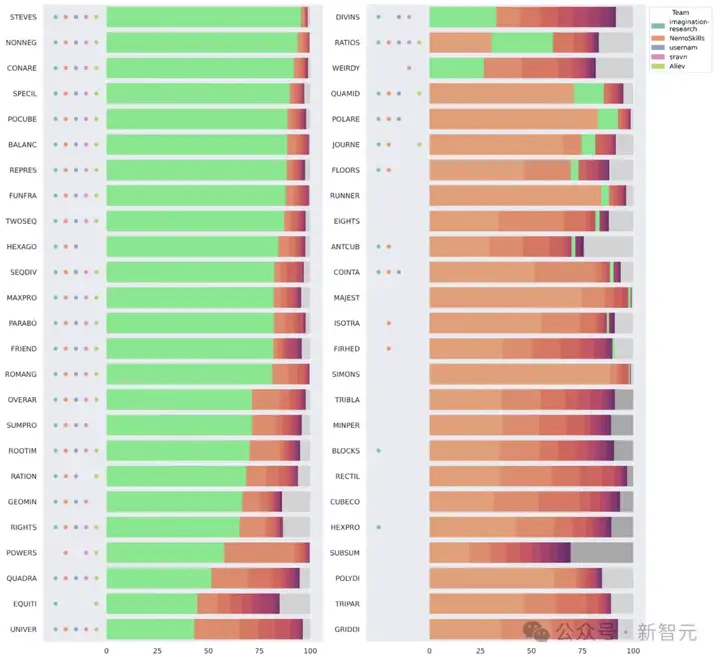
以上这些结果,皆具鲁棒性。
原因在于:题目数量多且难度高,多数达到国家数学奥赛水平,少部分略易或略难,接近IMO难度级别。
对所有o3-preview版本的评测,都在一个很短的时间窗口内(数小时)完成。
并且AIMO获得了原始API输出的访问权限,便于复核与分析。
这些结果代表了基于AI的推理,在极具挑战性的领域迈出的一个里程碑式进展。
顺便提一句,AIMO Progress Prize 3(AIMO3)将于2025年秋季启动。
难度等级将再次提升,题目将以国际数学奥林匹克(IMO)水平为中心。关于时间安排、奖金池以及改进后的竞赛形式的完整细节将适时公布。
参考资料:
https://aimoprize.com/updates/2025-09-05-the-gap-is-shrinking
文章来自于“新智元”,作者“桃子 KingHZ”。


