# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
几十G的大模型,怎么可能塞进一台手机?YouTube却做到了:在 Shorts 相机里,AI能实时「重绘」你的脸,让你一秒变身僵尸、卡通人物,甚至瞬间拥有水光肌,效果自然到分不清真假。
一图看透全球大模型!新智元十周年钜献,2025 ASI前沿趋势报告37页首发
在youtube Shorts相机里,每个人都能「千变万化」。
可以是卡通角色、万圣节僵尸,甚至能立刻拥有粉色水光肌,效果自然又流畅。
最神奇的是,这些特效是直接在手机上实时生成的。
那么问题来了:YouTube是怎么把十几个G的大模型,塞进手机里的?
生成式AI模型的效果确实经验,但却有个致命问题:太大、太慢。
像StyleGAN、Imagen这类模型,只有在服务器上才能跑动。
因此必须要解决的问题,就是让滤镜在手机相机里即时生效。
YouTube的思路,是把庞大的生成模型「瘦身」,变成一个专门为移动端设计的小模型。
这个过程靠的是一套叫知识蒸馏的方法。
简单说,就是「老师–学生模式」。
大模型先当老师,生成各种示范;小模型则是学生,一点点模仿,直到学会独立完成任务。
老师是动辄几十G的庞然大物,学生则是轻巧的UNet+MobileNet架构,能在手机GPU上轻松跑到30帧。
不过,真正的教学过程远比想象中复杂。
工程师们不是「一次教完」,而是采用迭代式蒸馏。
大模型不只是给学生出题,还会在过程中不断测试:给人脸戴上眼镜、加上遮挡,甚至模拟手挡脸的场景。
学生在学习时,也不是简单照搬,而是要同时满足多种标准:画面数值对得上、看上去相似、自然不突兀,还得兼顾美感。
整个过程就像是反复刷题:学生交卷,老师挑毛病,再调整参数继续练。
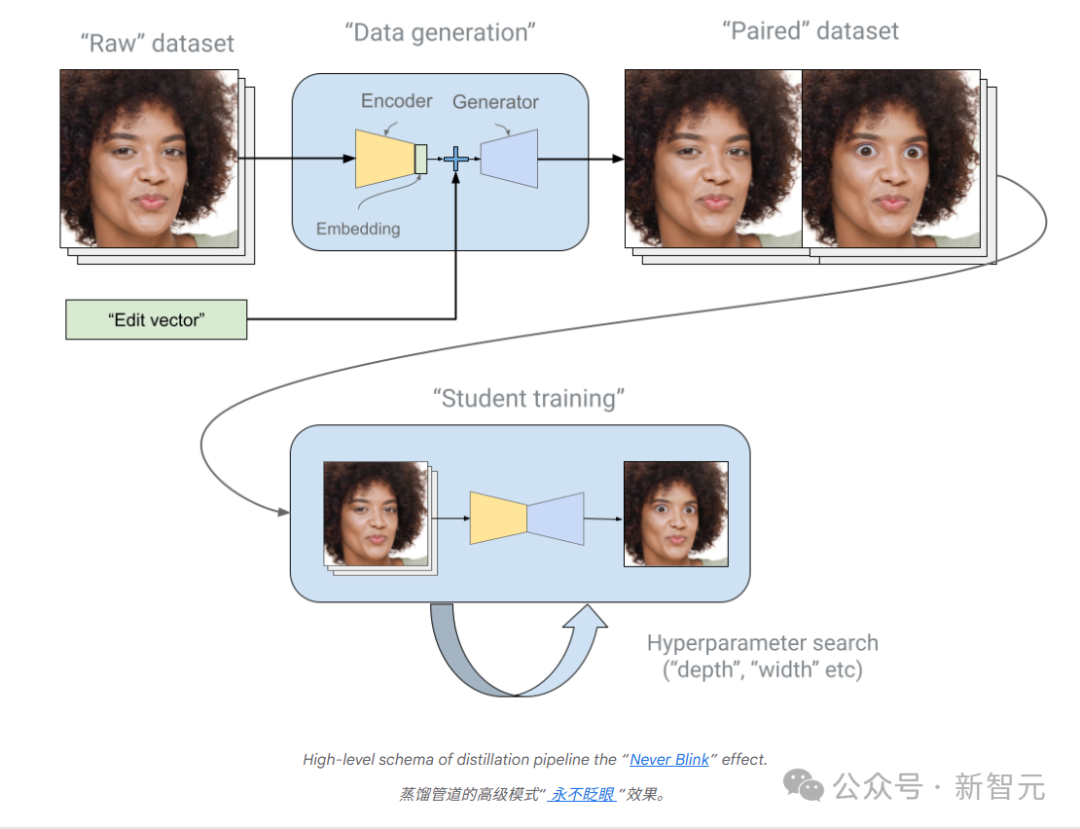
YouTube 的蒸馏流程:大模型先生成前后对照的图像对,小模型在此基础上不断学习,并通过超参数搜索迭代优化,最终实现如「永不眨眼」这样的实时特效。
工程师们甚至用上了神经架构搜索,自动帮学生找到最合适的「学习内容」,让它既高效又稳定。
经过一轮轮打磨,小模型终于真正掌握了大模型的本事。
在Pixel 8 Pro上,只需6毫秒就能完成一帧运算,iPhone 13大约10 毫秒,完全满足实时30帧的要求。
生成式AI在做特效时有个通病:它不会在原图上叠加效果,而是会重新生成整张人脸。
结果往往是肤色变了,眼镜没了,甚至五官都会变形,看上去完全不像本人。
这就是「inversion problem」——当模型把人脸转到潜在空间时,没能忠实还原身份特征。
YouTube想到的解决方案是Pivotal Tuning Inversion (PTI)。
可以把它理解为:在加特效之前,先让AI学会精准地「认清你是谁」。
原始图像会先被压缩成一个潜在向量,生成器用它画出一张初步的脸,但往往细节不到位。
于是工程师让生成器反复微调,让肤色、眼镜和五官逐渐被校正回来。
等身份被牢牢固定之后,再往里面加风格向量:比如笑容、卡通效果或者妆容。
最后生成的画面,看上去就是「还是你,只是换了个风格」。
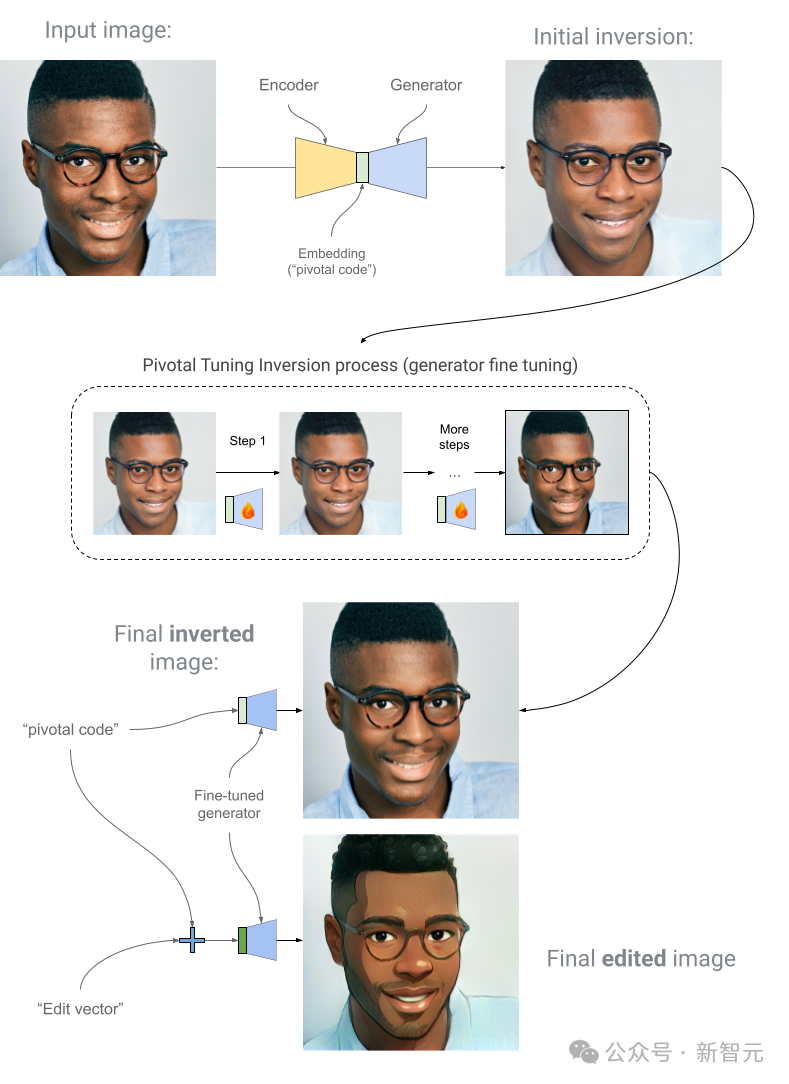
图:PTI的完整流程:从输入人脸,到生成初始inversion,再经过多轮微调,最后在保留身份特征的前提下叠加特效,得到最终图像。
换句话说,PTI保证了这些AI特效更像化妆,而不是换脸。
训练出轻量级的小模型只是第一步,真正的挑战是如何稳定地在手机上运行。
为此,YouTube选择了MediaPipe——Google AI Edge的开源多模态ML框架,用它来搭建端侧的完整推理管道。
整个流程可以分成四步:
首先,通过MediaPipe的Face Mesh模块,识别出视频流中的一个或多个人脸。
接着,由于学生模型对人脸位置很敏感,系统会把检测到的脸进行稳定裁剪和旋转对齐,保证输入一致。
之后,裁剪后的图像被转成张量输入学生模型,特效(比如微笑、卡通风格)在这一环节实时生成。
最后,模型输出的人脸图像再被无缝拼回到原始视频帧中,让用户看到连贯自然的最终画面。
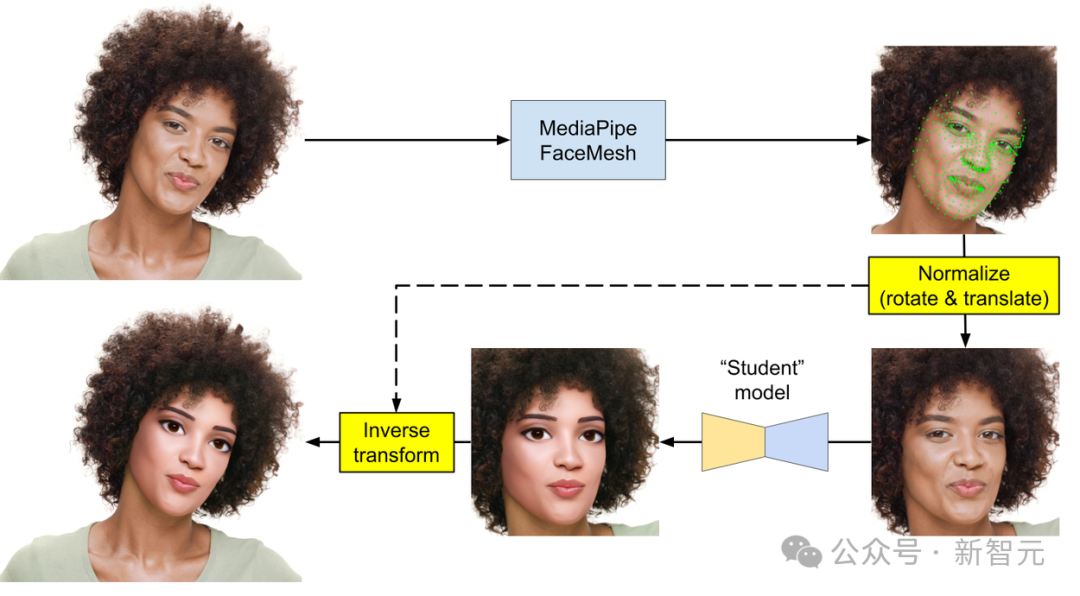
图:MediaPipe在端侧的完整推理流程:先检测人脸并稳定对齐,再送入学生模型生成特效,最后拼回视频帧,整个过程在毫秒级内完成。
通过GPU加速,Pixel 8 Pro上的推理延迟被压缩到约6毫秒/帧,iPhone 13 GPU约10.6毫秒/帧。
对用户来说,就是打开相机就能体验到顺滑的AI特效。
这套技术已经在YouTube Shorts上全面铺开,创作者们能直接用上几十种实时特效。
想要时刻挂着微笑?用Always Smile,哪怕你本人此刻面无表情,镜头里也会立刻咧嘴笑开。

想玩点惊悚?万圣节专属的Risen Zombie,分分钟把你变成刚爬出来的丧尸。
这些滤镜已经让Shorts里的创作方式发生了质变:不是贴图,而是AI量身绘制。
但这只是开始。
YouTube正在测试用Veo模型,可以把一张静态图片生成完整的视频片段。
用户只需要一张自拍或者一幅手绘,就能在手机上变成一段动态短片。

这意味着,未来的YouTube Shorts不只是拍视频加滤镜,而是随手一张图,就能生成一条视频。
创作者的门槛会进一步降低,AI会更深地嵌入每个人的创作过程。
从实时滤镜到一键生成短片,YouTube正把AI变成创作者的随身画笔。
参考资料:
https://research.google/blog/from-massive-models-to-mobile-magic-the-tech-behind-youtube-real-time-generative-ai-effects/
文章来自于微信公众号“新智元”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
