# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Thinking Machines Lab成立7个月,估值120亿美元,首次公开研究成果:LLM每次回答不一样的真凶——kernel缺乏批处理不变性。Lilian Weng更是爆猛料:首代旗舰叫 Connection Machine,还有更多在路上。
Thinking Machines Lab终于放大招了!
刚刚,联合创始人、OpenAI前副总裁Lilian Weng透露:
Thinking Machines的第一代旗舰产品名为「Connection Machine」(联结机)。
事情是这样的:今天,Thinking Machines开辟了研究博客专栏「Connectionism」(联结主义),发表了第一篇博客文章「Defeating Nondeterminism in LLM Inference」(击败LLM推理中的非确定性)。

Thinking Machines介绍说:
我们相信科学因分享而更美好。
Connectionism专栏将随着我们的研究变化:从内核数值计算到提示工程。在这里,我们分享我们的工作进展,并与研究社区频繁而开放地交流。
此外,还补充道,「Connectionism」这一名称可追溯至早期的AI时代——在1980年代,该术语指代专门研究神经网络及其与生物大脑相似性的子领域。

而Lilian Weng爆出了更大的料,专栏之所以叫这个名称,还有一个原因:第一代旗舰模型就叫Connection Machine,不光是这篇博客文章,而且还有更多好东西要来了!

莫非Thinking Machines马上要发布新模型了?
在期待新的LLM之前,我们先看看这次Thinking Machines到底有哪些绝活,他们到底关注哪些研究领域。

传送门:https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
据博文的主要作者Horace He介绍,这次的博文主要关于他心中的重要话题——
LLM推理中的可复现浮点数(Reproducible floating point numerics in LLM inference)。
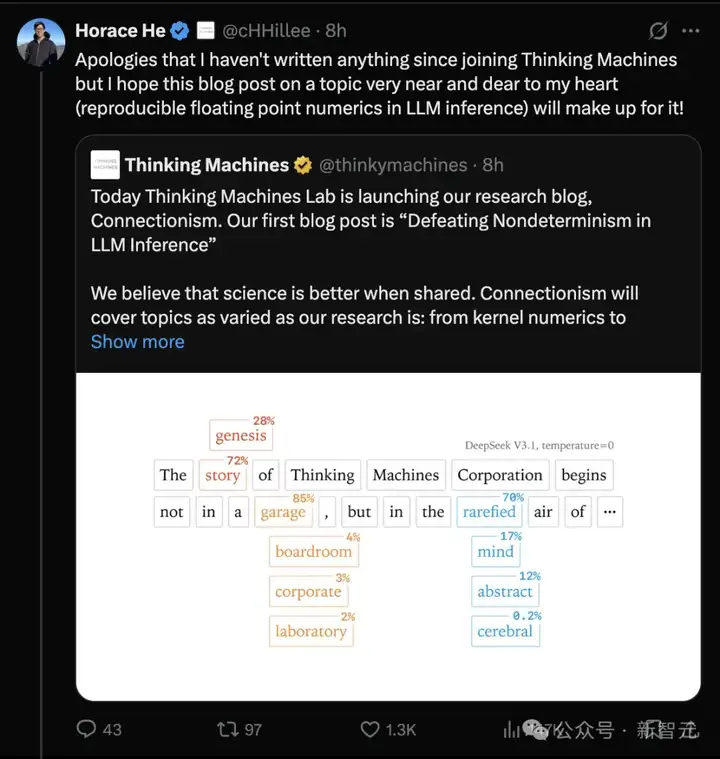
可复现性是科学进步的基石。然而,从大语言模型中获得可复现的结果却异常困难。
例如,你可能会观察到,多次向ChatGPT提出相同的问题会得到不同的结果。
这本身并不奇怪,因为从语言模型获得结果涉及「采样」:
将语言模型的输出转换为概率分布,概率性地选择一个token。
更令人惊讶的可能是,即使我们将temperature降至0(从而使采样在理论上是确定性的),LLM API在实践中仍然不是确定性的。

即使在自己的硬件上,使用像vLLM或SGLang这样的开源推理库运行推理,采样仍然不是确定性的。
但为什么LLM推理引擎不是确定性的呢?
一个常见的假设是,浮点数非结合性与并发执行的某种组合,导致了基于哪个并发核心先完成的非确定性。
这次研究则称之为LLM推理非确定性的「并发+浮点数」假说。
例如,华人研究员Jiayi Yuan、Hao Li、Xinheng Ding等最近上传了一篇arXiv预印本,其中写道:
GPU中的浮点运算表现出非结合性,意味着 (a+b)+c ≠ a+(b+c),这是由于有限的精度和舍入误差。
此属性直接影响Transformer架构中注意力分数和logits的计算,其中跨多个线程的并行操作可能会根据执行顺序产生不同的结果。

传送门:https://arxiv.org/abs/2506.09501
虽然这个假说有些道理,但并未揭示全貌。
例如,即使在GPU上,对相同数据重复运行相同的矩阵乘法,也总会提供逐位相等的结果。
我们确实在使用浮点数,GPU确实有大量的并发计算。那为什么在这个测试中没有看到非确定性呢?⬇️

要理解LLM推理非确定性的元凶,我们必须更深入地探究。
不幸的是,即使是定义LLM推理的确定性也并非易事。
也许令人困惑的是,以下陈述竟能同时成立:
这次,Thinking Machines决定要揭示LLM推理非确定性背后的真正元凶,并阐述如何克服LLM推理中的非确定性,获得真正可复现的结果。
关键发现:
LLM前向传播不需要原子加法;其非确定性真正来源是「批次大小变化」而非「原子竞争」。
要想在推理服务中避免非确定性、为了使Transformer实现具有批处理不变性,我们必须在kernel中实现「批处理不变性」。
幸运的是,我们可以假设每个逐点(pointwise)操作都具有批处理不变性。因此,只需要担心涉及归约的3个操作——RMSNorm、矩阵乘法和注意力。
它们的实现难度也是递增的。每个操作都需要一些额外的考虑,才能以合理的性能实现批处理不变性。
理想情况下,我们希望在并行化策略中避免核心之间的通信。
实现这一点的一种方法是为每个核心分配一个批处理元素,从而保证每个归约都完全在单个核心内完成。
这就是所谓的「数据并行」策略,因为我们只是沿着一个不需要通信的维度进行并行化。
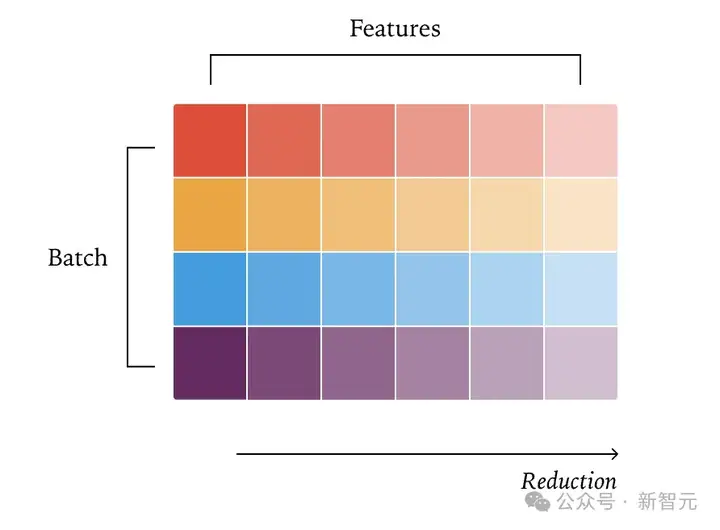
与RMSNorm类似,矩阵乘法的标准并行策略是一种「数据并行」策略,将整个归约保持在一个核心内。
最直接的思考方式是将输出张量分割成二维的分块(tiles),并将每个分块分配给不同的核心。然后,每个核心计算属于该分块的点积,再次在单个核心内执行整个归约。
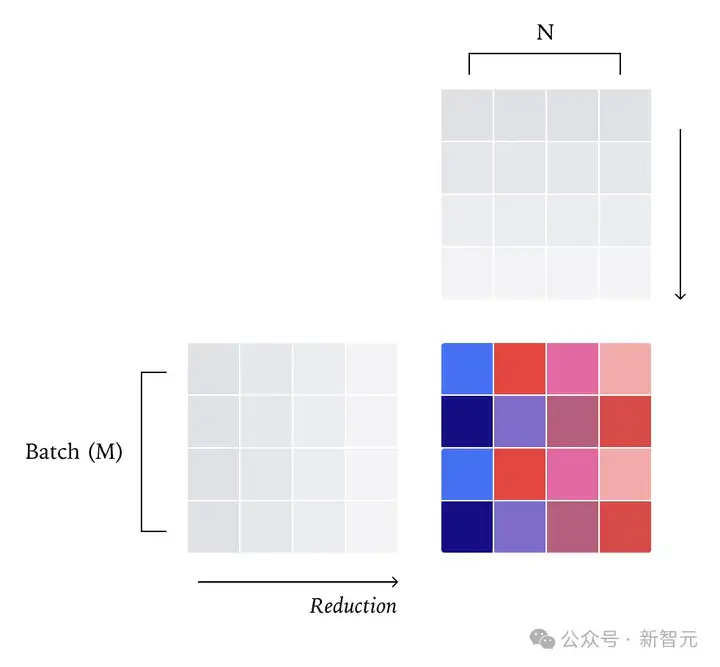
与RMSNorm不同,围绕算术强度和利用张量核心(tensorcores)的额外约束,被迫分割二维分块而不是单个输出元素进行,以实现高效的矩阵乘法kernel。
解决的核心在于,你可以将矩阵乘法看作是一个逐点操作后跟一个归约。
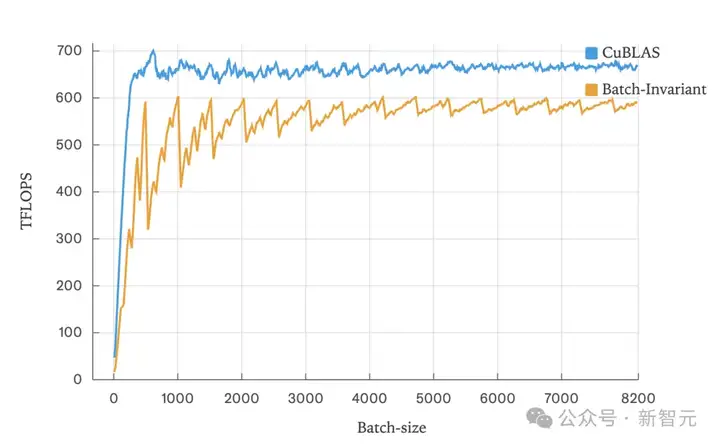
确保矩阵乘法具有批处理不变性的最简单方法是,编译一个kernel配置,并将其用于所有形状。
虽然会损失一些性能,但这在大语言模型推理中通常不是灾难性的:
相比cuBLAS只损失了约20%的性能。
在为矩阵乘法获得批处理不变性之后,注意力机制引入了两个额外的难题——恰如其分,因为它包含两个矩阵乘法。
带KV缓存的FlashAttention会破坏批处理不变性,根因在把「缓存KV」与「当前KV」分开算
不同 KV 块数 → 不同掩码/完整块组合 → 不同规约路径。
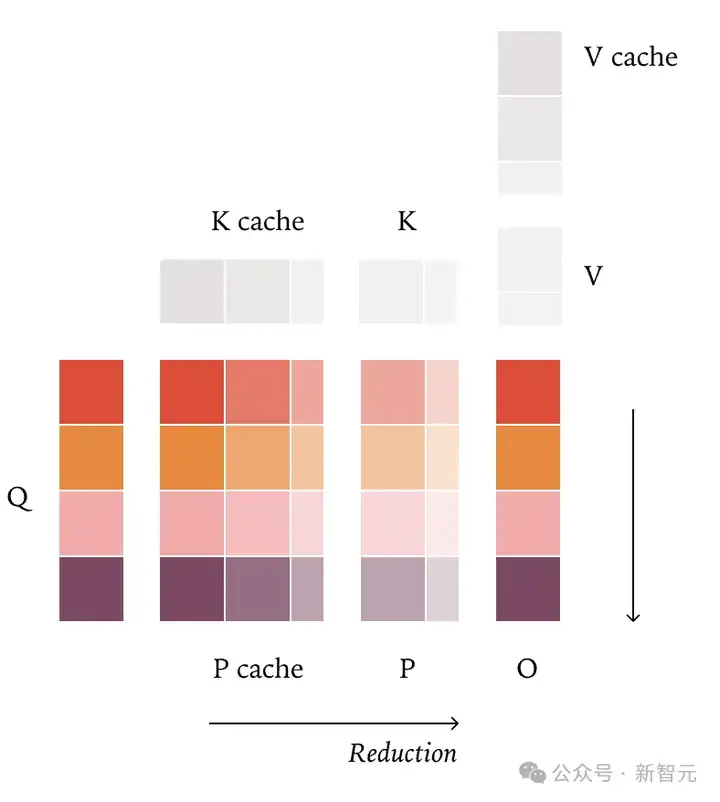
只要在kernel启动前,统一更新KV-cache页表,保证任意时刻KV布局一致,就能解决这一问题。
大语言模型推理中看到的注意力形状通常确实需要一个分裂归约的kernel,通常称为Split-KV或FlashDecoding。
固定数量的Split-KV策略(即FlashDecode),因为精确的归约策略取决于给定请求中处理来自序列的查询token数量,这不幸地也破坏了批处理不变性。
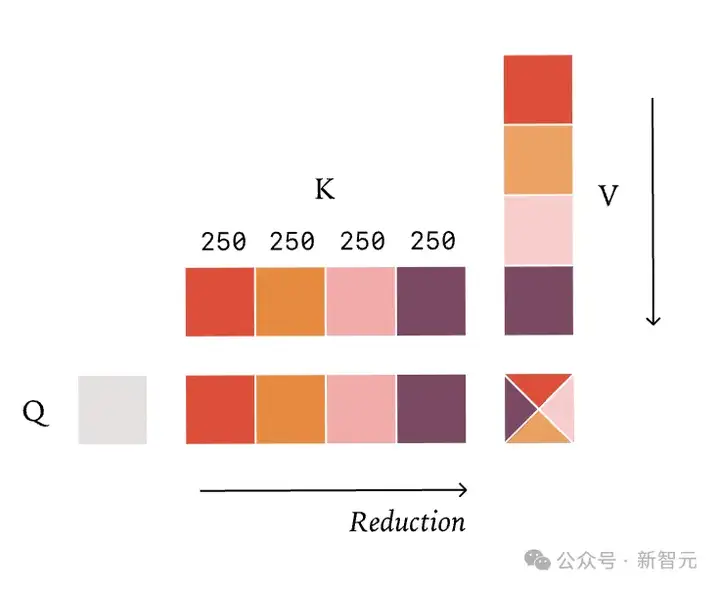
如果我们的查询长度变得非常小(就像在解码期间那样),可能会陷入一种情况,即kernel中几乎没有并行性。在这些情况下,需要再次沿着归约维度——这次是KV维度——进行分割。分割KV维度的典型策略是计算出需要多少并行性,然后均匀地划分KV维度。例如,如果KV长度是1000,我们需要4个分割split,每个核心将处理250个元素。
此外,通常用于注意力的分裂归约策略也对批处理不变性构成了挑战。
为了实现批处理不变性,不再固定分割的数量,而是固定每个分割的大小,然后得到一个可变数量的分割。
通过这种方式,可以保证无论正在处理多少个token,我们总是执行相同的归约顺序。
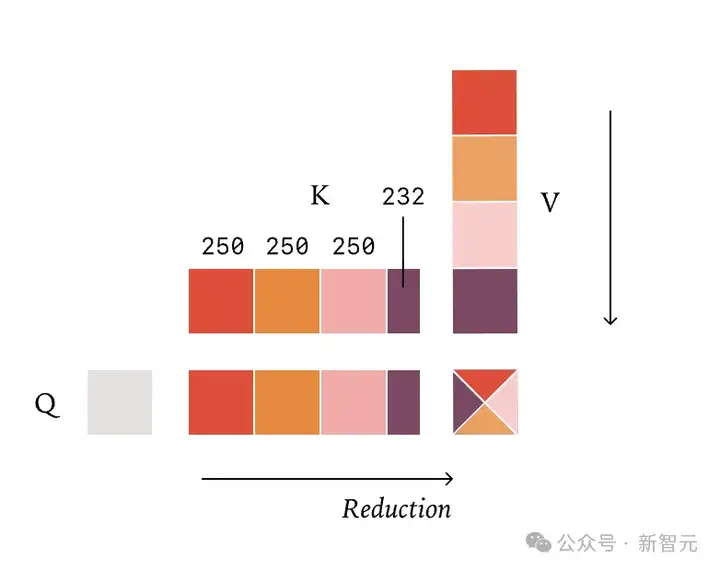
这实现了批处理不变性,因为归约策略不再依赖于一次处理多少个查询token!
用「固定块大小」Split-KV,注意力也能像 RMSNorm/Matmul 一样实现批处理不变,确定性推理。
通过利用vLLM的FlexAttention后端以及torch.Library,Thinking Machines提供了一个在vLLM上进行确定性推理的演示。
传送门:https://github.com/thinking-machines-lab/batch_invariant_ops
使用Qwen/Qwen3-235B-A22B-Instruct-2507,在温度为0的情况下,用提示词「Tell me about Richard Feynman」(非思考模式)采样1000个补全,每个生成1000个token。
令人惊讶的是,我们生成了80个不同的补全,其中最常见的出现了78次。
观察补全结果的差异之处,我们发现补全结果实际上在前102个token上是完全相同的!第一次出现分歧的补全发生在第103个token。
所有的补全都生成了序列「Feynman was born on May 11, 1918, in」。
然而,992个补全接着生成了「Queens, New York」,而8个补全生成了「New York City」。
另一方面,当启用批处理不变kernel时,所有的1000个补全都是完全相同的。
这次没有投入大量精力来优化批处理不变kernel的性能,但仍用实验测试了一下性能。
实验设置:一个带有一块GPU的API服务器,运行Qwen-3-8B,并请求1000个序列,输出长度在90到110之间。
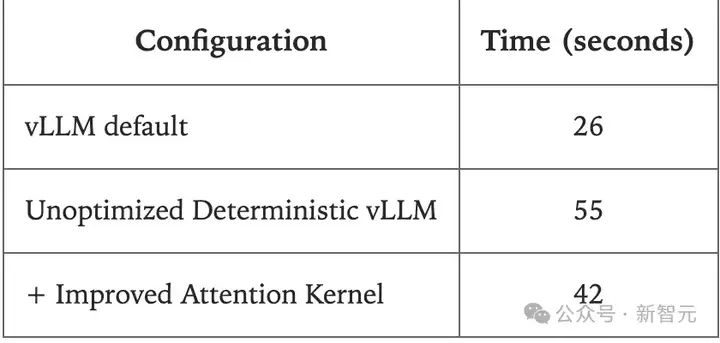
大部分的性能下降来自于vLLM中的FlexAttention集成尚未经过大量优化。尽管如此,性能下降并非不可接受。
正如研究人员指出的,训练和推理之间不同的数值计算,无形中将同策略强化学习(on-policy RL)变成了异策略强化学习(off-policy RL)。

传送门:https://fengyao.notion.site/off-policy-rl
如果两次相同的推理请求都无法做到逐位(bitwise)一致,那训练与推理在位级一致就更无从谈起。
确定性推理让我们可以同步改造训练栈,使采样与训练在数值上逐位一致,从而获得真正的同策略RL。
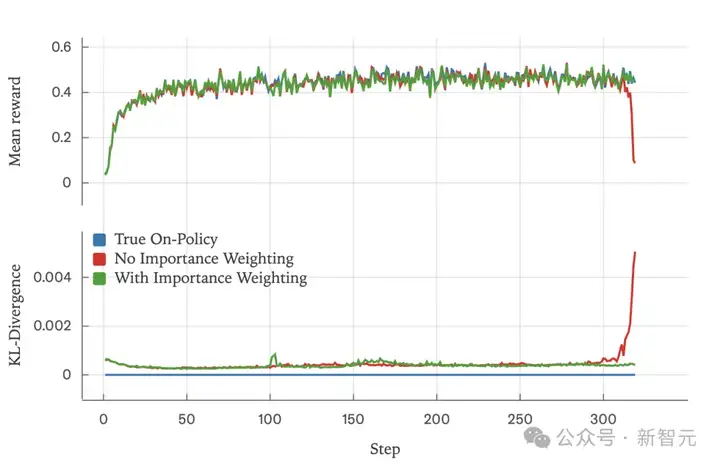
在Bigmath的RLVR设定下,研究人员做了实验:策略以Qwen 2.5-VL instruct 8B初始化,最大rollout长度 4096。
无异策略校正(不做重要性加权)时,训练中段奖励出现崩塌;
加入异策略校正(importance weighting)后,训练可平稳推进;
当让采样器与训练器逐位一致时,策略完全同源(KL=0),训练同样平稳。
同时,研究人员绘制了采样器与训练器对数概率(logprobs)之间的 KL 散度:三种设定差异明显——
需要强调的是:未做重要性加权的那次运行在Step 318左右出现显著的损失峰值,同时KL散度同步陡升;而做了异策略校正或实现「真正同策略」的两种设置,RL都能持续、平滑地优化。
现代软件系统层层抽象,机器学习中的非确定性与微小数值差异,往往让人想「睁一只眼闭一只眼」:
反正系统本就「概率化」,多一点不确定也无妨?
单元测试里把atol/rtol往上调一调、把训练与采样间的logprob差异当成「假阳性」,似乎也能过关。
请拒绝这种「算了吧」的心态。只要多做一点功课,我们完全可以定位并修复这些非确定性根源!
Thinking Machines希望本文能为社区提供一套解决推理端非确定性的清晰思路,也能激励更多人真正吃透自己的系统。
参考资料:
https://x.com/lilianweng/status/1965828743152509198
https://x.com/cHHillee/status/1965828670167331010
https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
文章来自于“新智元”,作者“KingHZ”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
