# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前机器人领域,基础模型主要基于「视觉-语言预训练」,这样可将现有大型多模态模型的语义泛化优势迁移过来。但是,机器人的智能确实能随着算力和数据的增加而持续提升吗?我们能预测这种提升吗?
换句话说:我们能找到机器人模型的 Scaling Law 吗?
就在今天,AI 机器人创业公司 Generalist 宣布在这方面取得了突破。这家「以实现通用机器人为使命」的公司推出了一类新型的具身基础模型 GEN-0。

GEN-0 专为直接在高保真度的原始物理交互数据上进行多模态训练而构建,参数量可达 10B+。其架构建立在视觉和语言模型的优势之上,但又超越了它们。
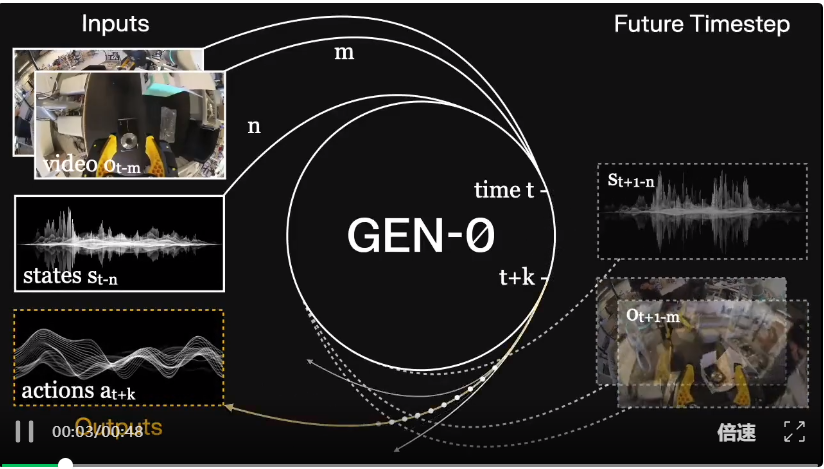
其原生设计旨在捕捉人类水平的反应 (human-level reflexes) 和物理常识。
GEN-0 还具备一项核心特性:和谐推理 (Harmonic Reasoning)。即训练模型时要让其无缝地同时「思考」和「行动」。
更重要的是,Generalist 还证明 GEN-0 的这些能力都是可扩展的。下面总结了该公司的这一波贡献:
这一系列成果备受赞誉:
Generalist 表示:「我们相信GEN-0 标志着一个新时代的开始:具身基础模型的能力,可以通过与真实世界的物理交互数据(而不仅仅是文本、图像或模拟数据)进行可预测的扩展。」
以下是 GEN-0 在一个新任务上运行的视频:

组装一个相机套件(俯视视角)。 这是一个长周期灵巧任务 (long horizon dexterous task),涉及将一块清洁布放入盒子,折叠一个纸板托盘,拿起相机并将其从塑料袋中取出,放入盒子,关闭盒子(并插入小盖舌),然后丢弃塑料袋。模型没有维持任何明确的「子任务」概念,它在「和谐推理」的单一流程中完成了所有这些操作。
接下来我们具体看看 Generalist 究竟做到了什么?
Generalist 的规模化实验表明,GEN-0 模型必须足够大,才能吸收海量的物理交互数据。Generalist 观察到,在数据过载的情况下,较小的模型表现出类似于「固化」的现象,而较大的模型则持续改进。
下图展示了 Generalist 模型智能容量上一个出人意料的「相变」:
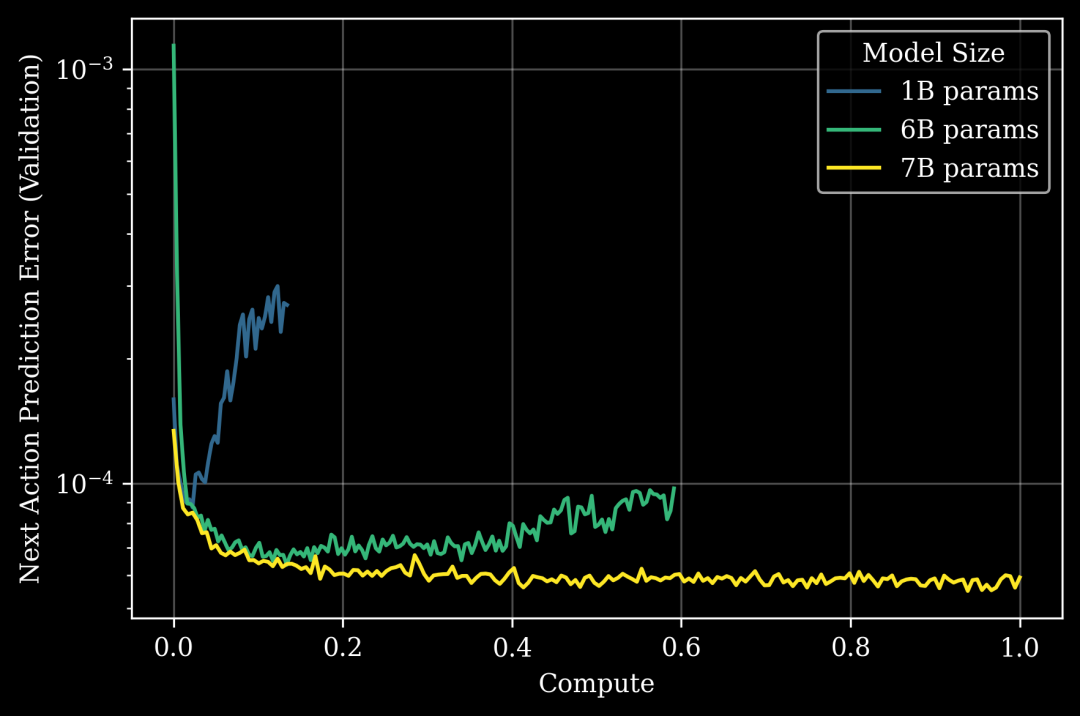
图 1: 扩展 GEN-0 模型规模(不同颜色)可以提高在一个完全保留的(即零样本)长周期下游任务上的性能(以「下一动作验证预测误差」衡量,y 轴,越低越好)。1B 参数模型表现出明显且早期的固化,而 6B 和 7B 模型在吸收预训练数据方面分别表现得更好。x 轴是标准化的预训练算力,以 GEN-0 7B 为 1.0。
Generalist 表示:「据我们所知,这是首次在机器人领域中观察到模型固化现象。过去的机器人研究可能忽略了这一点,原因在于 (a) 迄今为止机器人领域缺乏海量数据情景,以及 (b) 在此情景下缺乏足够大的模型规模。」
「固化」现象之前已在 LLM 文献中被观察到,同样是在海量数据情景下,但模型规模要小得多,处于 O(10M) 参数的量级,而非 O(1B) 级。这种相变发生在机器人领域,但所需的模型规模要大得多,这一观察结果呼应了莫拉维克悖论 (Moravec’s Paradox):人类觉得轻而易举的事情(如感知和灵巧性)比抽象推理需要远为复杂的计算能力。
Generalist 的实验表明,物理世界中的智能(即物理常识)在算力方面可能有一个更高的激活阈值 (activation threshold)。
Scaling Law 通常在预训练期间进行测量,如图 1 所示,它显示了在预训练期间,模型规模和算力在一个下游零样本任务上的关系。
另一种类型的 Scaling Law 则与预训练带来的、可持续到微调 (finetuning) 阶段的益处有关。在足够的模型规模下,Generalist 还观察到预训练数据规模与下游后训练性能之间存在很强的幂律关系(图 3)。
这适用于 Generalist 测量的所有任务,包括受合作伙伴和客户启发的应用及其工作流,涵盖服装、制造、物流、汽车和电子等广泛的工业领域。
更具体地说,Generalist 选取了在预训练数据集的不同子集上、使用其训练流程训练出的各种模型检查点,然后在多任务语言条件数据上对这些检查点进行后训练,即同时在 16 个不同的任务集上进行监督微调。Generalist 发现,更多的预训练可以提高所有任务的下游模型性能(图 2)。
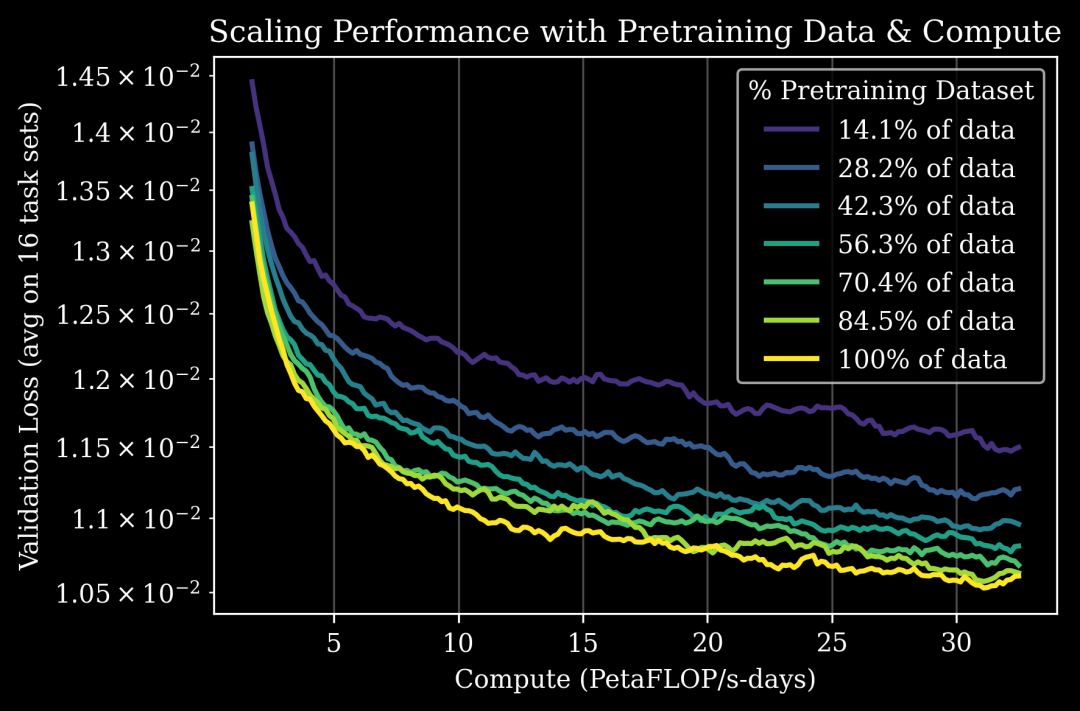
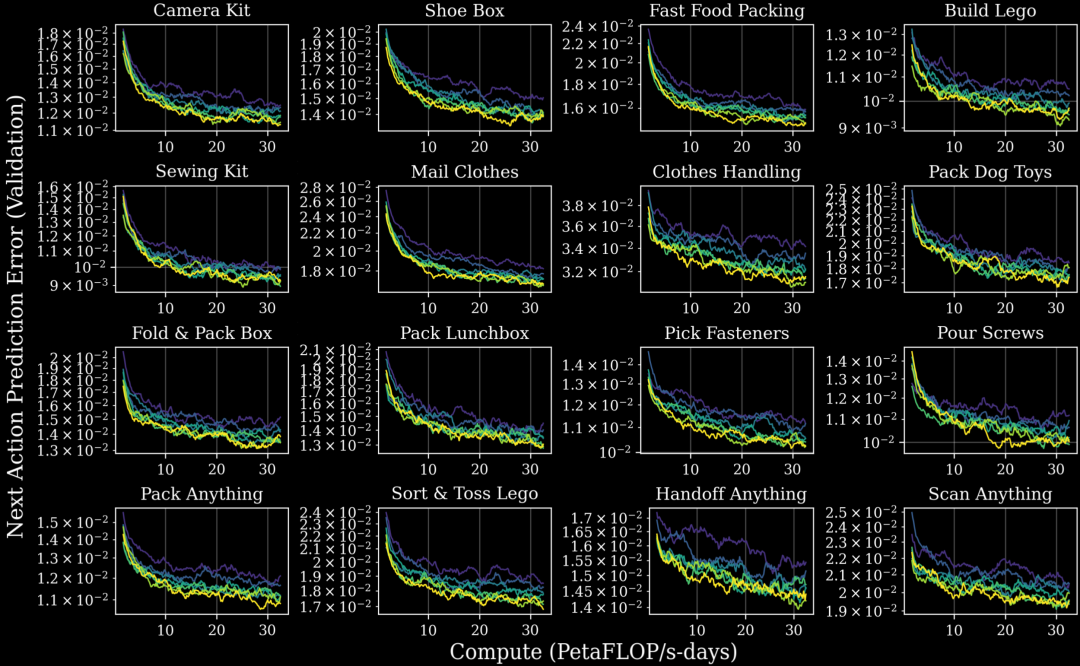
图 2: 随着预训练数据的增多(不同颜色),在所有 16 个任务集上,多任务模型在后训练期间的性能(以验证损失 (顶部) 和下一动作预测误差 (底部 4x4 网格) 衡量)均有改善。这些任务包括评估灵巧性、特定行业工作流和泛化能力。
模型性能可以通过幂律关系(图 3)进行预测,借此可以回答诸如「需要多少预训练数据才能达到特定的下一动作预测误差?」或「更多的预训练数据可以换取(节省)多少(特定任务的)后训练数据?」之类的问题。对于下游任务,给定固定的数据和微调预算,以及大小可变的预训练数据集 D,其验证误差 L () 可以通过以下幂律形式进行预测:
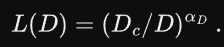
例如,在 Clothes Handling(涉及在真实工作场所中对衣物进行分类、整理、扣扣子和悬挂)的任务中,模型可以预测给定 10 亿个动作轨迹时的模型性能。这些估计有助于指导与合作伙伴相关的任务讨论,并能估算出达到特定性能水平还需要多少数据。
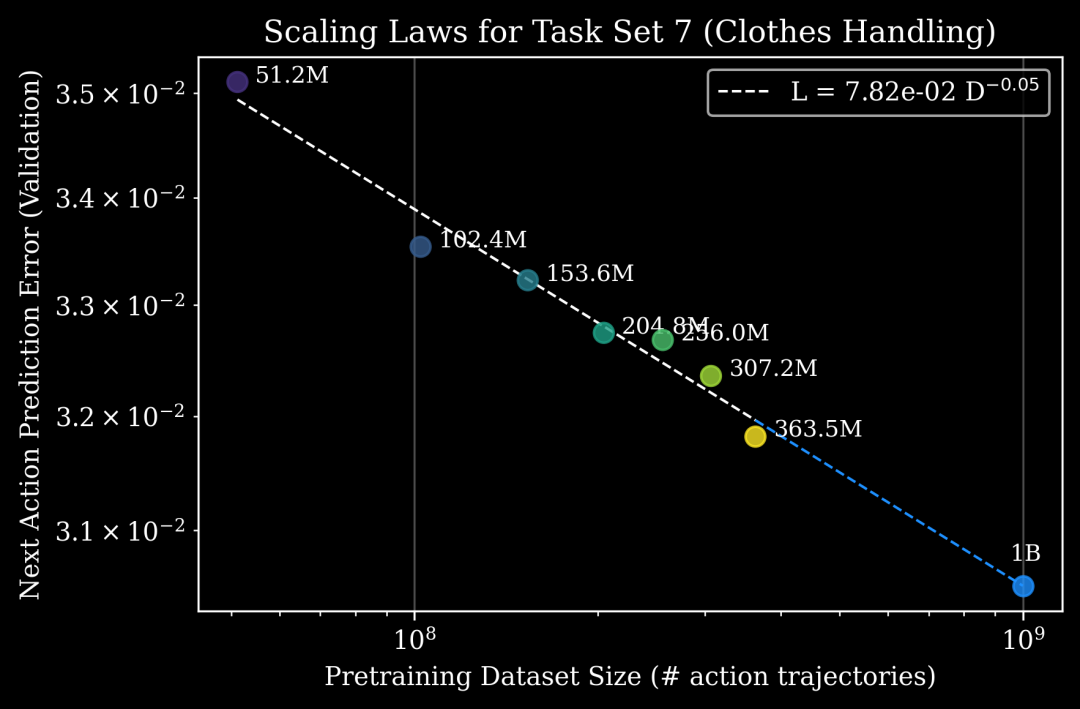
图 3: Generalist 的 Scaling Law 很好地描述了在给定任务集上,后训练模型的渐近「下一动作预测误差」与预训练数据集大小(以动作轨迹数量衡量)之间的函数关系。结合模型规模的 Scaling Law,我们可以使用这些结果来预测任何下游后训练任务的预训练算力和数据的最佳分配。
Generalist 的基础模型是在一个前所未有的语料库上训练的,该语料库包含了在全球数千个家庭、仓库和工作场所中,通过各种活动收集的 27 万小时的真实世界操作轨迹。
Generalist 表示,如今该公司的机器人数据运营每周能提供超过 1 万小时的新数据,并且还在加速。这一切都由一个全球硬件网络以及数千台数据收集设备和机器人提供支持。
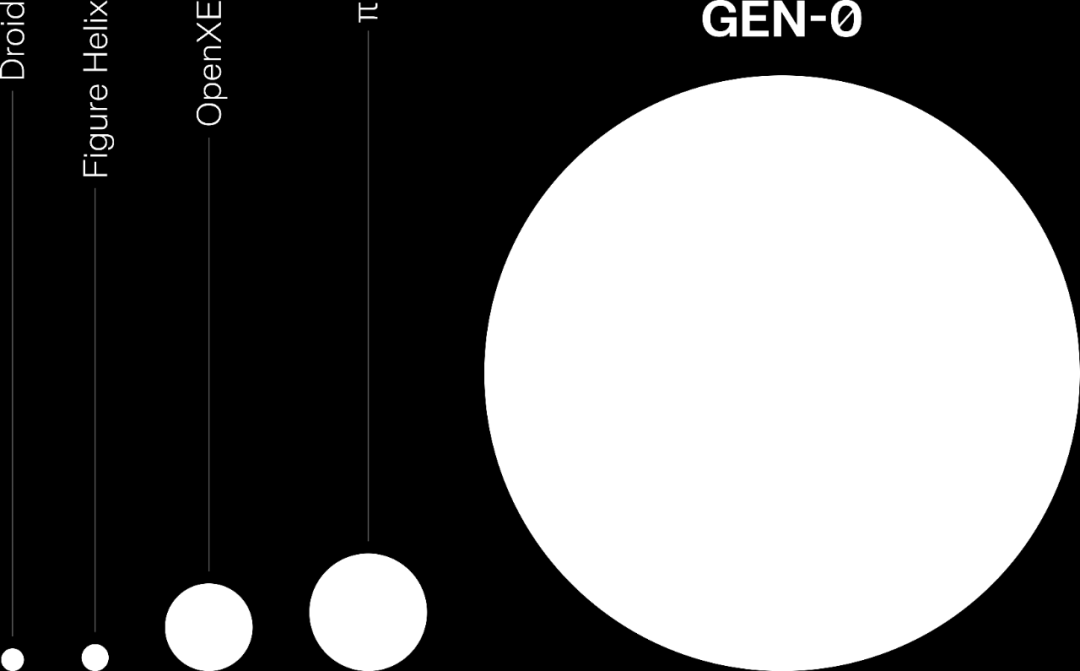
图 4: GEN-0 所训练的真实世界操作数据量,比迄今为止(截至 2025 年 11 月)一些最大的机器人数据集还要多出几个数量级。
为了扩展 GEN-0 的能力,Generalist 正在构建有史以来最大、最多样化的真实世界操作数据集,包括人类能想到的每一项操作任务,涵盖家庭、面包店、自助洗衣店、仓库、工厂等。
以下是 Generalist 构建的用于探索这个「操作全景」的内部搜索工具示例:
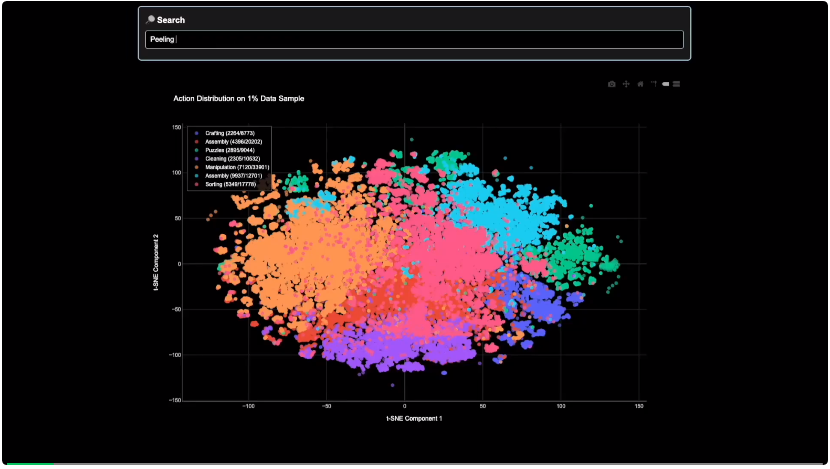
图 5: 这是一个在其不到 1% 的预训练数据集中进行搜索的示例,该数据集包含来自不同环境中数百万种不同活动的操作数据。该可视化工具引导用户浏览数据集中相应语言标签嵌入的 t-SNE 映射图。给定一个文本描述,可视化工具会定位到最近邻区域,并在该区域随机采样一系列相关视频并显示它们。
为此,构建运营和机器学习基础设施绝非易事。面对如此规模的机器人模型和数据,Generalist 构建了定制硬件、数据加载器和网络基础设施(包括铺设新的专用互联网线路),以支持来自全球各地不同数据收集站点的上行带宽。
Generalist 与多家云服务商合作,构建了定制的上传机器,扩展到 O (10K) 级核心用于持续的多模态数据处理,压缩了数十 PB 的数据,并使用了前沿视频基础模型背后的数据加载技术,能够在每训练一天就吸收掉 6.85 年的真实世界操作经验。
通过大规模的消融实验,Generalist 发现数据质量和多样性比纯粹的数量更重要,而且精心构建的数据混合可以带来具有不同特性的预训练模型。
这里就不过多展开实验数据了,总之结果表明:同时具有低预测误差和低逆 KL 散度的模型,在进行后训练的监督微调 (SFT) 时往往表现更好,而具有高预测误差和低逆 KL 散度的模型,则倾向于在分布上更具多模态性,这可能有助于后训练阶段的强化学习。拥有多种规模化的数据收集策略,使 Generalist 能够持续进行 A/B 测试,以确定哪种数据对预训练的提升最大。
你认为 GEN-0 是否标志着一个具身智能新时代的开始?
参考链接
https://x.com/GeneralistAI/status/1985742083806937218
https://generalistai.com/blog/nov-04-2025-GEN-0
文章来自于“机器之心”,作者 “Panda”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
