# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。
这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。
本周五,AI 社区最热门的话题是一篇新论文,有关 3D 建模的。

经过一年多的探索,来自字节跳动的团队推出了 Depth Anything 3(DA3),将单目深度估计扩展到了任何视角场景,让计算机实现了媲美人类的空间感知。

为了追求最小建模,DA3 的工作获得了两个关键见解:
就是这样的方法,在姿态估计方面比当前业界最先进的方法 (SOTA) 提升了 44%,在几何估计方面提升了 25%。
原来 3D 视觉竟然这么简单?
纽约大学计算机科学助理教授、知名 AI 学者谢赛宁表示,论文有点像电影:第一部通常是最好的,续集往往更复杂却并不更精彩。但这完全不适用于 DepthAnything 系列。 Bingyikang 的团队每次都能让事情变得更简单、更易于扩展。
谢赛宁感叹道,「在 Depth Anything 3 上,作者基本上表明,一个强大的表示编码器加上一个深度光线预测目标就足以在很多任务中获得可靠的、通用的空间感知(可以看到 RAE 的影子)。」
「人们常说他们讨厌计算机视觉,因为它太复杂 —— 任务太多、数据类型太多、涉及的环节太多。但这恰恰是我喜欢它的原因。我认为人工智能最大的突破将悄然来自视觉领域,然后突然间超越其他所有领域,彻底改变 AI 与现实世界,以及我们人类的互动方式。」
「我们很快就会意识到,视觉并非一系列任务的罗列 —— 它是一种视角。这种视角关乎对连续感官数据进行建模,构建世界的分层表征,并逐步迈向类人智能。说实话,在所有炒作的背后,我们每天都在见证着这一切的发生,所有这些不同的『任务』正慢慢地开始融合。」
Depth Anything 3 (DA3) 是一种能够根据任意数量的视觉输入预测空间一致几何形状的模型,无论是否已知相机位姿。为了实现最小化建模,DA3 带来了两个关键发现:仅需一个简单的 Transformer 架构(例如,原始的 DINOv2 编码器)即可作为骨干网络,无需进行架构上的特殊设计;单一的深度光线预测目标也能避免复杂的多任务学习。
Depth Anything 3 目前已发布三个系列:主 DA3 系列、单目测量估计系列和单目深度估计系列。
在方法上,Depth Anything 3 将几何重建目标建模为一个密集预测任务。对于给定的 N 张输入图像,该模型经过训练,可以输出 N 个对应的深度图和光线图,每个深度图和光线图都与其对应的输入图像像素对齐。实现这一目标的架构以标准的预训练视觉 Transformer 作为骨干网络,充分利用其特征提取能力。
为了处理任意数量的视图,作者引入了一个关键的改进:输入自适应的跨视图自注意力机制。该模块在前向传播过程中,会在选定的层中动态地重新排列 token,从而实现跨视图的高效信息交换。对于最终的预测,作者提出了一种新的双 DPT 头,它通过处理同一组具有不同融合参数的特征,联合输出深度值和光线值。为了增强灵活性,该模型可以通过一个简单的相机编码器选择性地整合已知的相机姿态,使其能够适应各种实际场景。这种整体设计形成了一个简洁且可扩展的架构,并直接继承了其预训练骨干网络的扩展特性。
在训练上,Depth Anything 3 模型采用了师生范式,以统一各种不同的训练数据。数据源包括多种格式,例如真实世界的深度相机捕获数据、3D 重建数据以及合成数据。
其中真实世界的深度数据质量可能较差。为了解决这个问题,作者采用了一种受先前工作启发的伪标注策略,使用合成数据训练一个强大的单目深度模型,从而为所有真实世界数据生成密集、高质量的伪深度图。事实证明,这种方法非常有效,在不牺牲几何精度的前提下,显著提高了标签的细节和完整性。
为了更好地评估模型并跟踪该领域的进展,作者还建立了一个新的视觉几何基准,涵盖相机姿态估计、任意视图几何(TSDF 重建)和视觉渲染。
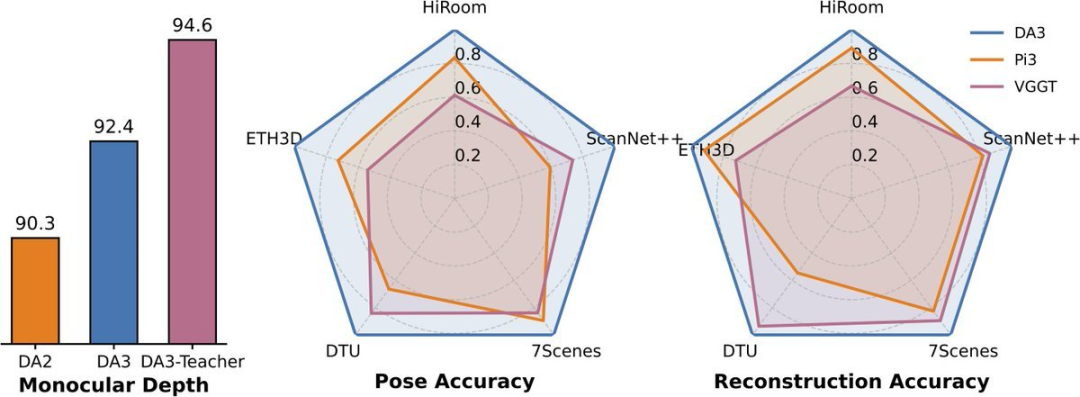
DA3 在所有 10 项任务中都取得了新的 SOTA 成绩,在相机姿态精度方面比之前的 SOTA VGGT 平均提高了 35.7%,在几何精度方面提高了 23.6%。它在单目深度估计方面优于 Deepth Anything V2,同时在细节和鲁棒性方面与之相当。
所有模型均完全基于公开的学术数据集进行训练。
此外,Depth Anything 3 具备多种强大功能,进一步展示了其广泛的应用潜力:




Depth Anything 3 发布后,已有不少开发者表示要把这个新方法引入自己的项目中,可见这种简单高效的设计,是人们所需要的落地方向。
更多内容,可参考原技术报告。
参考链接:
https://x.com/bingyikang/status/1989358278346977486
https://x.com/sainingxie/status/1989423686882136498?s=20
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
