# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在AI视频创作过程中,创作者常因频繁切换多种工具而疲惫,导致创作热情消磨。近期,多所高校联合开源的UniVA框架,像一位「AI导演」,能整合多种视频工具,提供从脚本到成片的一站式自动化体验,改变传统「抽卡」式创作,支持多轮交互和主动纠错,还能实现风格迁移、前传创作等功能,为视频创作带来高效与便捷。
在AI视频赛道「卷生卷死」的 2025 年,我们似乎陷入了一个「工具茧房」:为了做一个完美的视频,我们用ChatGPT生成指令,用Nano Banana生成图,用SAM做分割,用Sora或Kling生成视频,发现怎么一个特效也编辑不好,再导进AE做特效……
要完成一个视频内容的创作,需要来回周转、调用大量的工具。
完成这一切后,身心已然俱疲,当初因灵感迸发而生的激动与创作热情,也在这套繁琐流程中被消耗殆尽。
我们不缺强大的模型,我们缺的是一个能把这些工具「串」有机地起来的脑子。
近期新加坡管理大学、罗切斯特大学、伦敦大学学院、新加坡国立大学、香港中文大学、斯坦福大学联合开源的UniVA (Universal Video Agent),尝试解决这一系列的问题!
UniVA不是一个单一的视频生成模型,而是一个全能型通用视频智能体框架。

论文地址:https://arxiv.org/abs/2511.08521
代码仓库: https://github.com/univa-agent/univa
项目官网: http://univa.online/
它像一位不知疲倦的「AI 导演」,能够听懂你的复杂需求,自主规划路径,统筹调用市面上最强的视频工具,为你提供从脚本到成片的一站式自动化体验。
UniVA 不做「抽卡」工具,它要做的是下一代视频生产的智能引擎。
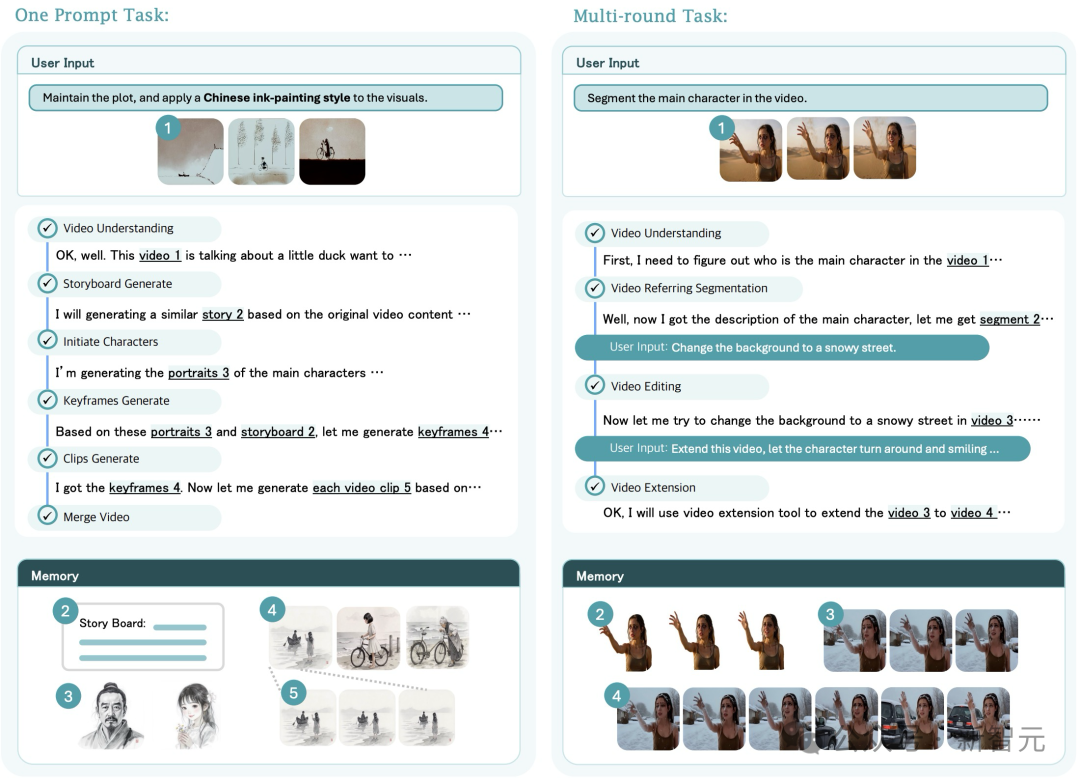
Highly Automated, Interactive, Proactive Video Creation
传统的视频AI是「单指令单任务」:你输入一句Prompt,它给你一段视频,如果不满意?只能修改Prompt重新生成(抽卡)。
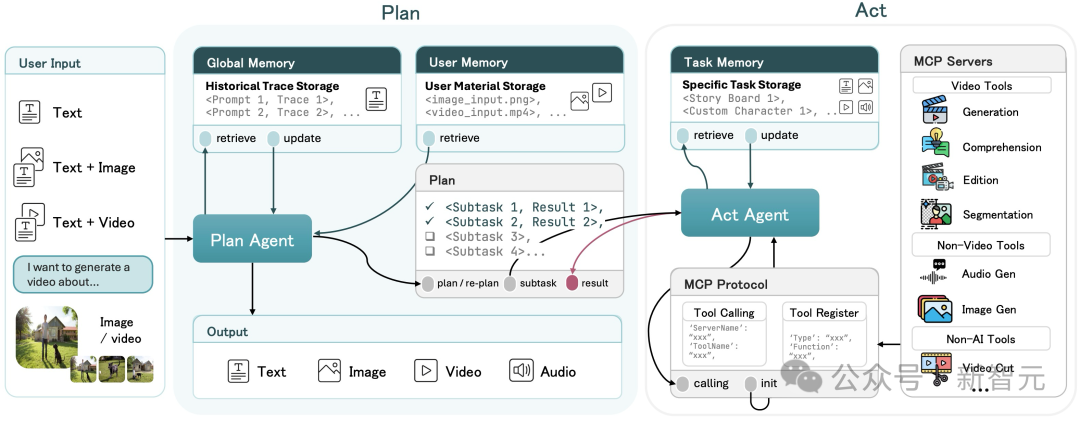
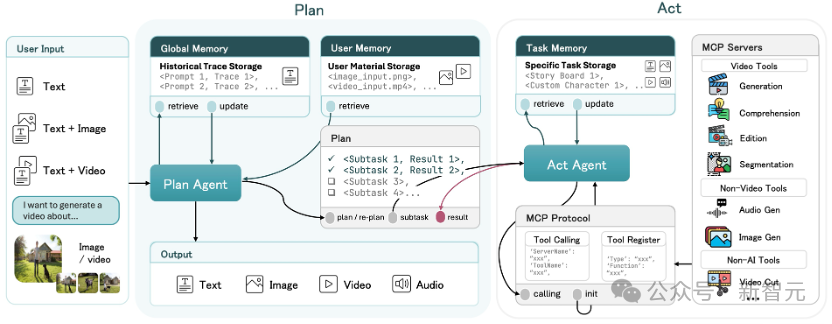
UniVA彻底改变了这种交互方式,基于Plan-Act(规划-执行)双智能体架构,让UniVA拥有了「思考」的能力。
全自动规划 (Automated Planning) :UniVA的Planner Agent会自动将模糊需求拆解为结构化的分镜脚本,并将任务分发给Executor Agent执行。
主动式服务 (Proactive Assistance) :不仅仅是执行命令,如果你的指令中有歧义,或者生成的中间结果不达标,UniVA 会进行自我反思 (Self-Reflection)。它会主动问你或自动修正错误,而不是把烂摊子丢给你。
多轮交互共创 (Interactive Co-creation) :UniVA能记住多轮对话的上下文。你可以像和剪辑师聊天一样修改视频,让创作变成一场流畅的协作。
指令:生成一个面包店广告,包含揉面特写、撒花瓣慢动作、顾客笑容及 Brand Logo。
UniVA:Planner 智能拆解剧本 -> 批量生成分镜(揉面、撒花、顾客) -> 智能剪辑 -> 植入 Logo
结果:逻辑清晰、包含多个分镜的 20 秒完整商业广告成片。

Omnipotent, Unified, Industrial-Grade Video Production Engine
UniVA的野心不止于「生成」,而是要解决工业级视频生产中的核心痛点:一致性与连贯性。
基于MCP (Model Context Protocol) 协议,UniVA构建了一个模块化的工具全家桶,实现了真正的All-in-One:
指令:保持这段视频的剧情和动作不变,把它变成中国水墨画风格。
UniVA:视频理解模块提取动作骨架 -> 调用风格化工具重绘 -> 像素级对齐。
结果:完美复刻原视频动态的水墨大片,无闪烁、无变形。

参考输入视频

Univa生成的视频
指令:基于这个视频,创作一段它的「前传」。
UniVA:提取角色形象与性格 -> 倒推故事逻辑 -> 生成全新剧情。
结果:人物设定完全一致的全新故事线,实现了真正的「长程记忆」创作。

参考输入视频

UniVA生成视频

OpenSource & Extensible Ecosystem
下一代视频AI的未来不应被封闭在某个大厂的API墙内,因此,UniVA选择完全开源。
基于MCP的无限扩展UniVA的架构设计是即插即用的。
研究人员集成了Runway或Seedance,明天如果有更强的开源模型出现(比如Sora API),开发者只需编写一个简单的MCP驱动,UniVA就能立刻获得新能力,它是一个会随着社区共同进化的「活系统」。
为了推动行业发展,研究人员同步开源了UniVA-Bench评测基准,首个针对「视频 Agent」的评测基准,不再只看生成质量,而是全面评估智能体的规划能力、工具调用效率、多步推理准确性。
参考资料:
https://arxiv.org/abs/2511.08521
文章来自于“新智元”,作者 “LRST”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
