# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。但在现有的评估体系下,行业内部普遍存在一种未经验证的共识,即认为基准数据集本身是准确无误的“黄金标准”(Ground Truth)。这种假设导致了评估过程中的归因偏差:当模型表现不佳时,开发者往往忽略了测量工具本身可能存在的系统性缺陷。
来自斯坦福大学的研究团队刚刚发表的一篇论文《Fantastic Bugs and Where to Find Them in AI Benchmarks》,给了这个黄金标准一记重锤。

论文开篇提了一个真实的案例:在GSM8K这个广受引用的数学推理榜单上,DeepSeek-R1模型最初的排名非常难看,位列倒数第三。但在研究人员修正了榜单中约5%的错误题目后,奇迹发生了,DeepSeek-R1瞬间跃升至第二名,成为顶级梯队的选手。

这不是个例。研究表明,GSM8K中约有5%的问题是无效的。而像MMLU这样包含14,000道题目、涵盖57个学科的庞然大物,人工逐一审查几乎是不可能的任务。
这就引出了一个核心问题:当基准本身充满了错误、歧义和陷阱时,我们还要如何通过它来衡量AI的能力? 为了解决这个问题,研究者引入了心理测量学(Psychometrics)。他们提出了一套基于统计学的“自动捉虫”框架,研究者在标题中巧妙的致敬哈利波特,试图用数学的魔法,把那些藏在AI Benchmarks里的“神奇动物”(Bugs)抓出来。
论文的方法论建立在经典的心理测量学(Psychometrics)之上,这是一门专门研究如何评估人类能力(如智力、学业成就)的学科。作者将其引入AI评估,其核心逻辑建立在一个朴素但强有力的假设之上:单维性假设(Unidimensionality Assumption)。

其公式表达为:
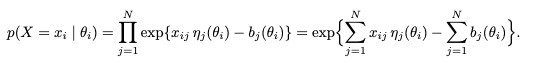
这个公式揭示了一个基本的统计规律:能力越强的模型,答对概率越高;题目越简单,答对概率越高。如果某道题目的数据表现违背了这个规律,例如高能力模型反而比低能力模型更容易做错,那么这道题在统计学上就是一个显著的“异常点”(Outlier),极有可能是无效题目。
为了在不依赖人工逐题审查的情况下自动识别这些异常,作者设计了三个基于统计学原理的检测指标(Detection Metrics)。它们利用数据分布的特性,从不同维度量化了题目的质量。

这个指标衡量的是题目之间是否存在内在的一致性。在满足单维性的测试中,如果题目A和题目B都在测试同一项能力(如数学),那么答对题目A的模型,理应有更高的概率答对题目B。
“项目可扩展性”源自非参数项目反应理论(Mokken Scale Analysis),用于衡量一道题目与整套试卷的“合群”程度。简单来说,它量化了一道题所包含的“有效信号”是否显著高于“随机噪声”。

这是一个衡量题目“区分度”的直观指标。它计算的是某道题的得分与模型在整张试卷上总分的相关性。
这套理论听起来完美,但在实际操作中效果如何?
研究团队在9个主流基准测试上应用了这套框架,结果显示:这套统计方法标记出的“嫌疑题目”,经人类专家复核,最高有84%确实是坏题。

但实验也揭示了两个深刻的现实:
1. 并没有万能的法器 就像没有完美的模型一样,也没有完美的检测算法。实验发现,上述三种统计信号捕捉到的坏题集合是不一样的。有的坏题表现为与总分负相关,有的表现为与其他题目不一致。“没有免费的午餐”定理在异常检测中依然适用,我们需要组合多种信号才能尽可能抓全Bug。

2. 只有“见多识广”才能“火眼金睛”AI评估面临的一个独特挑战是“考生”太少。人类考试动辄成千上万样本,而顶级LLM也就几十个。实验表明,检测的准确率(Precision@50)与参与测试的模型数量及多样性呈正相关。
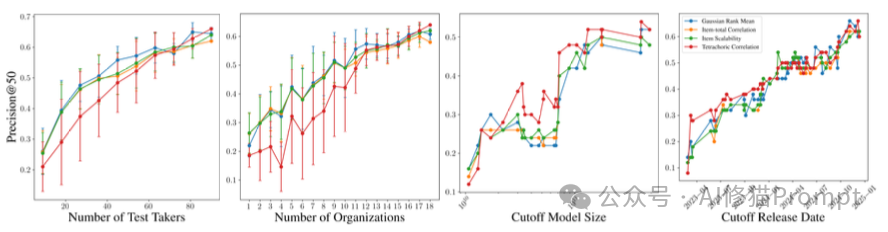
通过这套方法,研究者在GSM8K、MedQA、ThaiExam等权威榜单中挖掘出了大量令奇葩的错误。这些错误主要分为三类:歧义问题(Ambiguous Question)、错误答案(Incorrect Answer Key)和评分问题(Grading Issue)。
让我们走进这个“Bug博物馆”,看看AI们到底是被什么题难住的。
你以为数学是最客观的?GSM8K告诉你:未必。
“恒定贬值率”的数学陷阱


令人绝望的评分脚本


医学容不得半点马虎,但MedQA里却充满了粗心,这是非常可怕的一件事。


在安全评估中,俚语(Slang)成为了语义理解的噩梦。

面对这些层出不穷的Bug,难道我们要用最传统的方式,用人海战术去修补吗?论文给出了否定的答案。
AI不仅是考生,也可以是考官。
研究者引入了 LLM-Judge First Pass(大模型初审)机制。
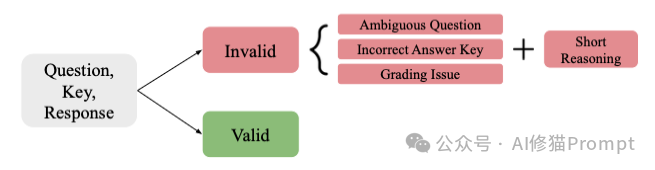
具体流程是:
效果: 在对GSM8K前100题的测试中,这套基于LLM的自动审查流程达到了 98%的精确度。这意味着绝大多数工作可以自动化完成,人类专家只需要最后把关即可。
斯坦福的这项研究,给AI社区带来的启示远不止于“捉虫”,它是一次对行业良知的拷问。
在AI领域,我们习惯于为SOTA(State of the Art)的每一次刷新而欢呼。但当连GSM8K这样的权威榜单中都竟然藏着5%的无效题目,那么一些所谓的刷榜,有多少是构建在充满噪声的数据沙滩之上的?
研究者最后指出:长期以来,我们遵循着一种“发布即遗忘”(Publish-and-Forget)的模式。数据集一旦发布就成了金科玉律。但在MedQA这样的医学榜单中,都能出现肿瘤转移路径被标错、关键诊断图片缺失、甚至用错误的生理学常识作为标准答案。这已不再是学术严谨性的问题,而是关乎生命的严肃命题。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
