# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在软件开发领域,需求工程(Requirements Engineering, RE)一直是项目成功的关键环节。然而,传统 RE 方法面临着效率低下、需求变更频繁等挑战。根据 Standish Group 的报告,仅有 31% 的软件项目能在预算和时间内完成,而需求相关问题导致的项目失败率高达 37%。
随着 ChatGPT 等大语言模型的爆发式发展,生成式 AI(GenAI)为需求工程带来了前所未有的机遇。来自早稻田大学、东北大学等机构的研究团队,对 2019 年至 2025 年间发表的 238 篇相关论文进行了系统性文献综述,为我们揭示了这一新兴领域的全貌。

这是目前为止对生成式 AI 在需求工程领域最系统、最全面的文献综述,揭示了从技术到落地的全貌与未来路线,是理解「GenAI 如何重塑软件开发起点」的必读论文。
爆发式的研究热度
数据显示,GenAI 在需求工程领域的研究呈现指数级增长:
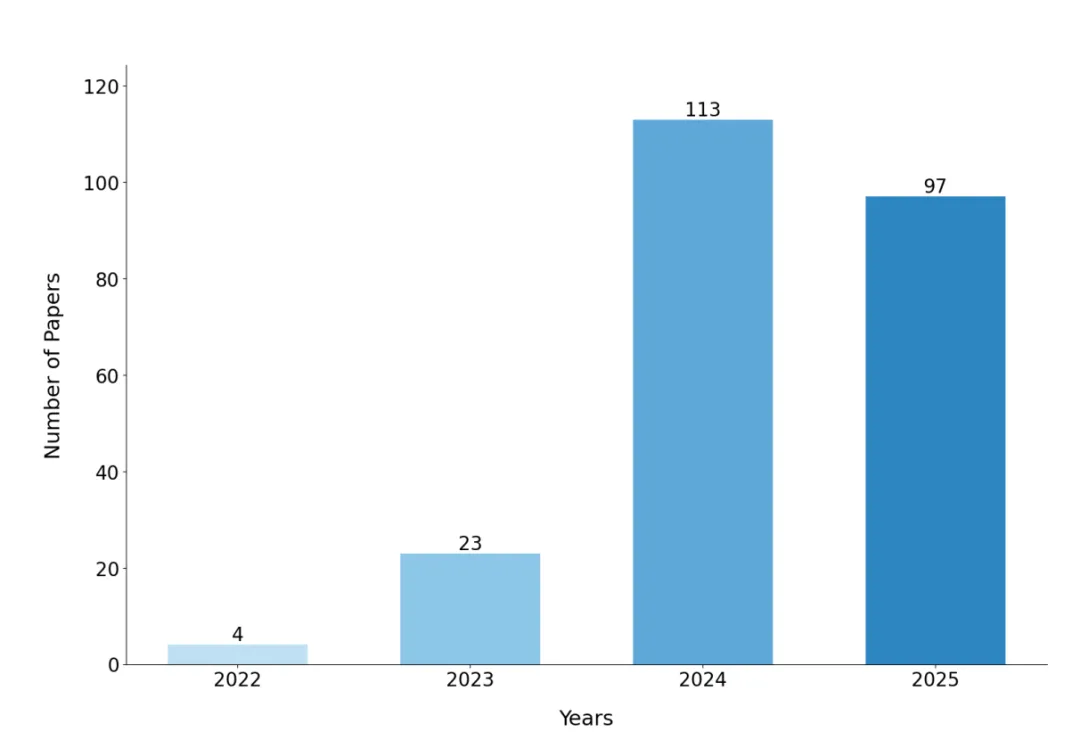
Distribution of papers across years (N=238).
这种增长轨迹充分反映了 ChatGPT 发布后,学术界对 GenAI 应用于 RE 领域的浓厚兴趣。
尽管研究热度高涨,但不同 RE 阶段受到的关注度严重失衡:
这种分布反映出当前研究主要集中在 GenAI 擅长的文本分析和生成任务,而对需求管理等涉及复杂社会技术因素的阶段探索不足。
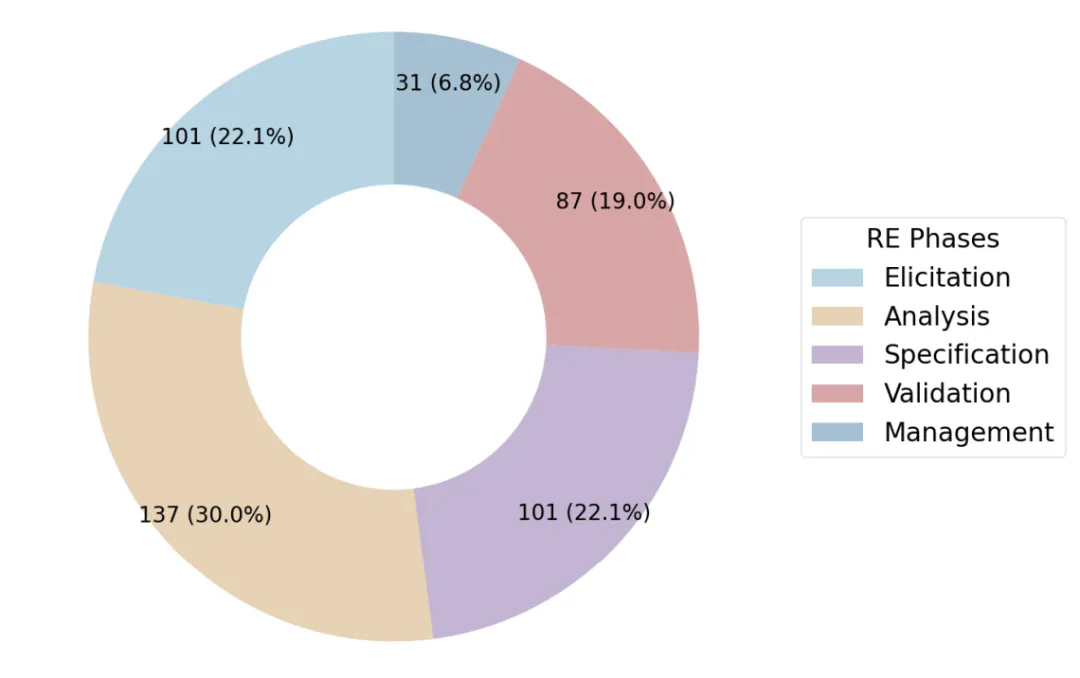
Distribution of RE phases (N=238).
GenAI 在 RE 领域已进入「快速扩张但尚未成熟」的阶段,研究数量暴涨但深度不足,仍停留在「概念验证」层面。
研究发现,67.3% 的研究采用 GPT 系列模型,其中:
这种过度依赖单一模型家族的现象,限制了多样化技术路径的探索。值得注意的是,CodeLlama 在代码 - 需求追溯任务中表现出色,幻觉率比通用模型低 23%,但采用率仍然很低。

Distribution of GenAI models (N=238).
在提示工程方面,研究呈现出以下特点:
令人欣慰的是,超过 80% 的研究公开了提示词细节,这为研究的可复现性奠定了基础。
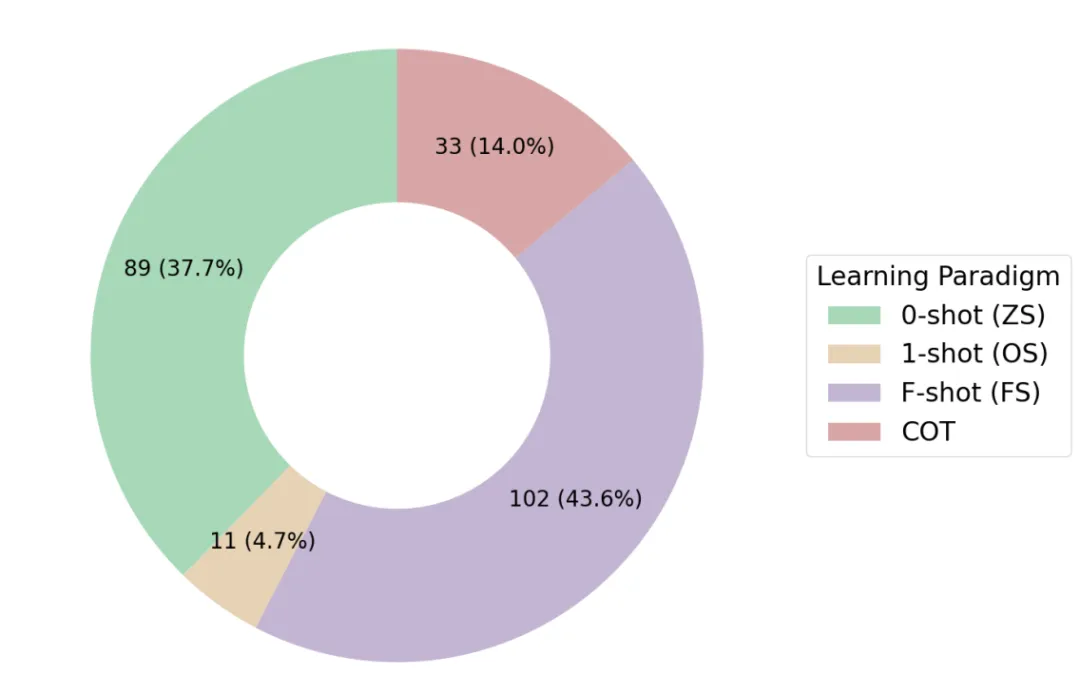
Distribution of learning paradigm (N=238).

Distribution of prompt types (N=238).
在软件质量特性方面,当前研究呈现明显的短期导向:
这种关注度分布表明,研究者更注重即时的功能表现,而忽视了长期的系统级质量属性。这种质量关注的偏颇表明,当前研究仍以「可用性优先」驱动,而非「可靠性与可解释性优先」,这是 AI 走向工业级软件系统的最大隐患。
研究识别出 10 个主要挑战,其中三个核心挑战形成了紧密关联的「三角关系」:

Correlations among the LLM issues reported in literature on RE (%).
可复现性影响幻觉问题的验证,幻觉问题又加剧可解释性缺失;三者相互强化,构成当前 GenAI 研究最难攻克的「信任瓶颈」。
尽管越来越多研究开发了工具和数据集,但实际可用性令人担忧:
评估方法主要依赖传统 NLP 指标:
这种表面化的评估无法捕捉 RE 任务的复杂性和领域特异性。

Distribution of tool and dataset availability (N=238)

Distribution of evaluation metrics and methodology (N=238)
当前 RE 领域缺乏类似 MMLU、HumanEval 那样的标准基准测试,导致学术成果难以横向比较,这也是产业界迟迟未能采用的重要原因。
成熟度现状令人担忧
研究显示,GenAI 在 RE 领域的工业化进程严重滞后:
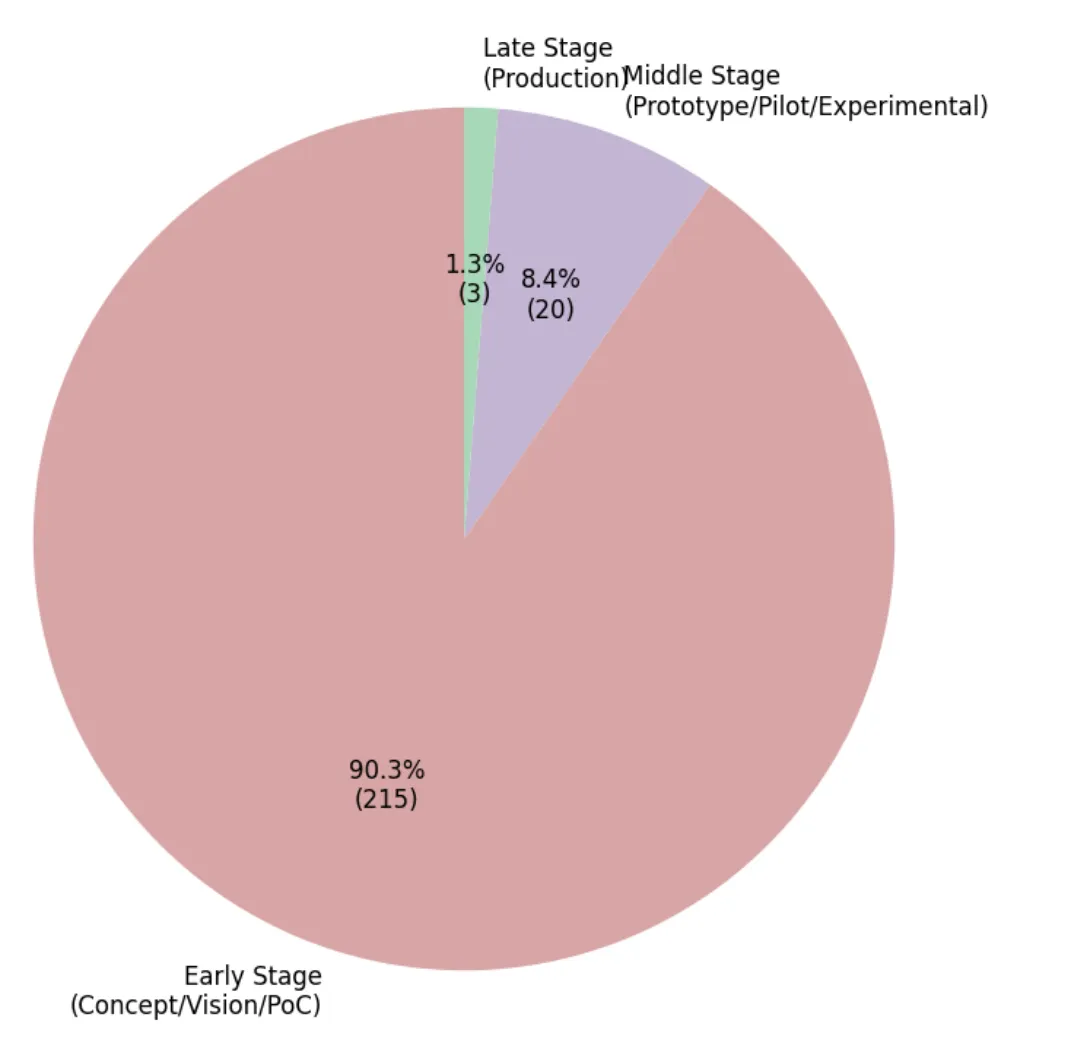
Industrial adoption stages of GenAI use in RE (N=238).
研究识别出 11 类主要限制因素:
值得注意的是,47.2% 的研究面临三个或以上的限制类别,表明这是系统性而非孤立的问题。
从产业角度看,GenAI 在 RE 的价值主要体现在「加速需求文档生成」和「减少沟通成本」,但由于缺乏合规性与风险控制标准,企业普遍持观望态度。
基于系统性分析,研究团队提出了多阶段研究路线图:
建立标准化基准测试、RE 特定指标和可复现性协议,这是解决当前 90% 研究停留在早期阶段问题的关键。
将伦理审计、公平性约束和利益相关者验证纳入 GenAI 系统设计,应对当前治理相关问题关注不足的困境。
采用模块化架构、参数高效微调(LoRA、PEFT)和 RAG 等技术,降低幻觉率,提高系统可控性。
建立社区驱动的工具包、开源基准和法律框架(如著作权治理),为生产级应用奠定基础。
GenAI 在需求工程领域展现出变革性潜力,但要实现从学术探索到工业应用的跨越,仍需克服可复现性、幻觉控制和可解释性这三大核心挑战。研究表明,这些挑战高度关联,必须采用整体性解决方案。
更重要的是,成功应用 GenAI 需要技术健壮性、方法论成熟度和治理整合的协同发展。从 90% 的研究停留在早期阶段到仅 1.3% 达到生产级别的现状来看,这条路还很长。但随着评估基础设施的完善、治理框架的建立和标准化工作的推进,GenAI 终将成为需求工程领域不可或缺的智能助手。
这不仅是一场技术革命,更是软件工程实践的范式转变。当需求从「人工编写」转向「人机共创」,软件工程正进入一个全新的智能时代。
文章来自于“机器之心”,作者“程浩伟”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
