# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在AIGC技术飞速发展的背景下,只需一行简单的prompt就可生成高逼真内容,然而,这一技术进步也带来了严重的安全隐患:虚假新闻、身份欺诈、版权侵犯等问题日益突出。AI生成图像检测也成为了AIGC时代的基础安全能力。
然而在实际应用中, 存在一个“尴尬”现象:检测器往往在“考场”(公开基准数据集)上分数耀眼,一旦换到“战场”(全新模型或数据分布),性能会大幅下降。
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。
目前,相关论文《Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable》已被NeurIPS 2025接收为Spotlight(录取率 Top 3.2%)。

研究团队认为问题的根源可能在于训练数据本身的构造方式,使得检测器并没有真正学会区分真假的本质特征,而是“走了捷径”,依赖于一些与真伪本身无关的“偏差特征”(Biased Features)来做出判断。
这些偏差特征是真实图像与AI生成图像在训练数据收集过程中产生的系统性差异。具体来说:
在这样的数据构成下,检测模型可能会去学习“投机策略”,例如PNG≈假图,JPEG≈真图。这种“捷径” 可以在某些标准测试集(如GenImage)上甚至可以达到100%的检测准确率,然而一旦对AI生成的PNG图像进行简单的JPEG压缩,使其在格式和压缩痕迹上接近真实图像,这类检测器的性能就会出现“断崖式下跌”。
对比真实图像和AI生成图像,两者可能存在格式偏差、语义偏差和尺寸偏差:

针对这一问题,研究团队认为如果数据本身带有系统性偏差,模型设计的再复杂也难免“学偏”。因此提出了DDA(双重数据对齐,Dual Data Alignment) 方法,通过重构和对齐训练数据来消除偏差。其核心操作分为三步:

使用VAE(变分自编码器)技术对每一张真实图像进行重建,得到一张内容一致、分辨率统一的AI生成图像。这一步操作消除了内容和分辨率上的偏差。
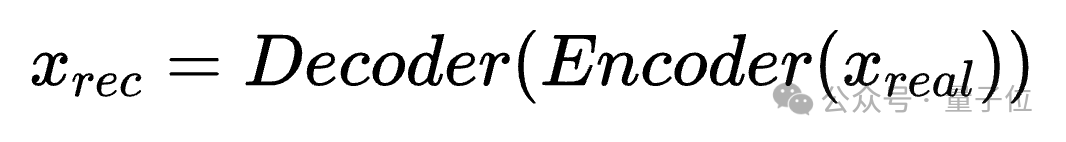
仅仅像素域对齐是不够的,由于真实图像大多经过JPEG压缩,其高频信息(细节纹理)是受损的;而VAE在重建图像时,反而会“补全”这些细节,创造出比真实图像更丰富的高频信息,这本身又成了一种新的偏差。

△可视化对比真实图像(JPEG75)和AI生成图像(PNG)的高频分量
实验也证实了这一点:当研究者将一幅重建图像中“完美”的高频部分,替换为真实图像中“受损”的高频部分后,检测器对VAE重建图的检出率会大幅下降。

△对比VAE重建图和VAE重建图(高频分量对齐真实图像)的检出率
因此,关键的第二步是对重建图执行与真实图完全相同的JPEG压缩,使得两类图像在频率域上对齐。

最后采用Mixup将真实图像与经过对齐的生成图像在像素层面进行混合,进一步增强真图和假图的对齐程度。
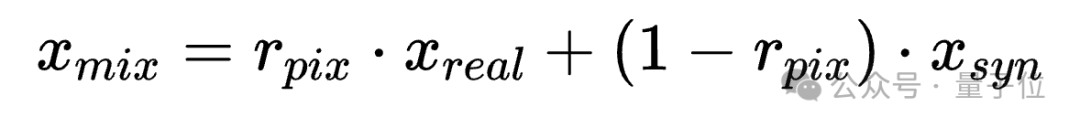
经过上述步骤,就能得到一组在像素和频率特征上都高度一致的“真/假”数据集,促进模型学习更泛化的“区分真假”的特征。
传统的学术评测往往是为每个Benchmark单独训练一个检测器评估。这种评测方式与真实应用场景不符。
为了更真实地检验方法的泛化能力,研究团队提出了一种严格的评测准则:只训练一个通用模型,然后用它直接在所有未知的、跨域的测试集上评估。
在这一严格的评测标准下,DDA(基于COCO数据重建)实验效果如下。

在AI生成图像日益逼真的今天,如何准确识别“真”与“假”变得尤为关键。
但AIGC检测模型的泛化性问题,有时并不需要设计复杂的模型结构,而是需要回归数据本身,从源头消除那些看似微小却足以致命的“偏见”。
“双重数据对齐”提供了一个新的技术思路,通过提供更“高质量”的数据,迫使这些模型最终学习正确的知识,并专注于真正重要的特征,从而获得更强的泛化能力。
论文地址:
https://arxiv.org/pdf/2505.14359
GitHub:
https://github.com/roy-ch/Dual-Data-Alignment
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
