# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Marc Andreessen 常说:"这个世界上赚钱的方式只有两种,要么 bundle(组合) ,要么 unbundle(拆分) 。"
这句话放到 AI 时代,会打开一条非常有意思的分析路径。
所以这期我们想从这个视角出发,集中聊聊我们看到的一些机会。
目录
AI 圈最近很大的一个黑天鹅事件,是 Grammarly 的逆袭。
在此之前,我感觉创投圈的私下共识都是:
薄套壳应用很难有未来,功能单一的垂类 SaaS 也非常危险。Grammarly 这种上个时代的语法插件,理应是 ChatGPT 的第一批刀下亡魂。
但让我意外的是,Grammarly 不仅没死,反而活得更好了——年收入超过 7 亿美金,用户量突破 4000 万。今年还反向收购了两家我认为很有新贵气质的公司:Coda(新一代文档独角兽)和 Superhuman(一个口碑非常好的邮箱客户端)。然后,他们做了一个非常大胆的决定:将整个公司改名为 Superhuman,并推举 Coda 创始人 Shishir Mehrotra 出任新集团的 CEO。
我花时间仔细听了 Shishir Mehrotra 最近的两期播客。
听完之后,我有一种久违的兴奋感——这可能是我今年听到的,关于 “老公司如何在 AI 巨头中翻身” 最性感的一个故事。
Shishir 在播客中详细复盘了这场三合一大合并背后的战略决策,以及他对 Agent 的终局思考。
故事的起点很有意思。Shishir 说,Coda 和 Grammarly 最初认识,是因为双方融资 BP 的标题竟然一模一样:“AI-native productivity suite” (AI 原生生产力套件) 。
但他对 Grammarly 的判断是:这是一个 “有护城河,但没有城堡” 的产品。
这里的护城河,是指分发能力。
大家往往误解了 Grammarly,以为它的核心是 “语法修改”。
但实际上,它的核心技术是它构建好了一种能嵌入到 50 万个应用和网站的底层能力,让 AI 能在几乎所有网站、App、桌面应用上无缝读写、标注、修改。
也就是说,Grammarly 过去 16 年的牛逼之处,是构建了一条高速公路,能把 AI 带到你工作的所有角落。
相比之下,语法只是这条高速公路上跑的第一辆车而已。
但问题是,Grammarly 缺少一个核心的目的地。这就像 YouTube 只有 “视频嵌入” 功能,却没有 Youtube 官网一样。
这是他们要收购 Coda 的第一大原因,Coda 强大的文档中心就是 Grammarly 想要的大本营。
类似的逻辑下,Grammarly 又收购了 Superhuman。因为写 Email 其实是 Grammarly 的第一大使用场景。那与其作为一个插件寄生在别人的地表上,不如直接买下这个地皮。这样他们可以把 Agent、文档和邮件彻底打通,给用户一个更好的 AI 体验。
接下来,Grammarly 面临的第二个问题是:
这条高速公路上,过去只跑着一辆车——你的高中语法老师。
集团的新战略,就是把这条路开放出来,变成一个 Agent 平台,让无数车都能跑起来。
因为他们发现了一个很大的痛点:“AI 的最后一公里” 问题。
举个例子,亚利桑那州立大学是他们的早期客户之一 。大学内部开发了 5000 个 AI 应用和聊天机器人,几乎每个课程都有自己的 chatbot。
但结果根本没人用。
因为学生根本不记得要去打开那个 chatbot。
Superhuman 想做的,就是让那个教授 chatbot 直接嵌入到学生写作业的文档里,变成学生的数字孪生教授。
通过 Grammarly 已经造好的高速公路,他们可以成为整个 AI 市场的传送门。
同时,这也引出了他们收购 Coda 的第二个原因,Coda 能给他们带来一支现成的车队。
Coda 已经和绝大部分主流办公应用做了集成,这些应用可以变成无数新的 Agent,跑在这条高速路上。
我们可以想象一个场景:
过去,一个销售在写邮件,Grammarly 就像他的 “高中英语老师” 坐在他肩膀上,随时帮他改正语法错误,而未来,他的肩膀上会坐着一群人:
CRM Agent:提醒他 “这客户只对 A 产品感兴趣,别推 B”。
Support Agent:提醒他 “这客户之前投诉过,语气要软一点”。
Book Agent:他最近看了一本很喜欢的书《Radical Candor》,于是把这本书做成了一个 Agent,以后无论他在邮件还是 Slack 里和他人沟通,作者 Kim Scott 就像坐在他肩膀上,可以在合适的时候引导他把沟通变得更坦诚。
从第三方 App 的视角来看,他们也有很强的动力合作。
他给出了一个很生动的例子,试想,如果把 Duolingo 做成一个 Agent,跑在 Grammarly 的分发渠道上,会发生什么?
场景 1: 它看着你在网上读了三篇西班牙语文章,就自动帮你把今天的 “打卡” 勾上了——因为它知道你真学了。
场景 2: 它会主动入侵你正在阅读的英文文章,把里面 5% 你应该认识的单词,悄悄替换成西班牙语,这样你能不知不觉完成复习。
场景 3: 当你晚上再打开 Duolingo App 时,它不会再让你练 “餐厅点餐”,而是说:“我发现你今天在研究怎么买车,那我们今晚来练买车场景的对话吧”。
这几乎是对 App 这个概念的重塑。它不再是一个需要被动打开的界面,而是一个寄生在所有工作流中、主动服务的精灵。
以上就大概总结了 Shishir 的战略:Grammarly 提供 “高速公路”,Coda 和 Superhuman 提供 “大本营” 和 “核心车队”,而 Duolingo 这样的第三方就是各式各样的 “非机动车”。
我觉得他们的策略很有意思。
市场上一直有一个观点,最终 AI 的终局是 “得 context 者得天下”,而大厂占据了所有重要的用户 context,所以创业公司很难抗衡。
但实际上有一个问题,用户的 context 是相当分散的。以 Grammarly 为例,他们公司内部就在同时使用 972 个 SaaS 软件,而创业公司的机会就在于它可以构建一个中立的、跨平台的 AI 层把所有应用连接起来。
比如微软正通过 M365 + Copilot + Teams 的 bundle 建立一个 “封闭的围墙花园”,但微软只致力于让自己的封闭体系变得更好。
而 Superhuman 能在几乎任何 App、网页和工具中运行,包括 Office、Google Docs 等大厂根据地。
这是用开放生态的 bundle,对抗封闭生态的 bundle。
我在想,也许新时代并不存在所谓的 “入口” 之争,因为关键路径就不是 “用户打开 AI 入口”,而是 “AI 主动跑到用户身边去”?
Reference:
Why Grammarly Became Superhuman | Agents of Scale
https://shorturl.asia/WCmGL
Grammarly x Superhuman: The Future of Workflows | Grit
https://shorturl.asia/eLJ1z
听完播客,我发现 Shishir Mehrotra 是一个硅谷罕见的,思维 sharp 的播客嘉宾。
于是我顺藤摸瓜地考古了一下他的经历,之后有点明白了为什么 Grammarly 会把新公司掌门人的位置拱手让给他。
他可能是全硅谷最懂 “如何把不相关的东西打包卖出去” 的人。
过去 20 年,他几乎完整经历了所有最成功的 bundle 实践:
在他看来,bundle 是商业中最强大、但最容易被误解的策略之一。
他对这个模式的思考非常深入和精彩!我翻完了他过去所有的访谈和文章,集合起来,给大家做一个系统的梳理。
我们先从一个最基础的问题开始:Bundle 的用处到底是什么?
Shishir 定义了一套很有意思的用户分类标准。
他认为,对于任何产品,世界上只有三种人:
传统的单点付费模式,其实只能赚到 “刚需用户” 的钱,而 bundle 的核心价值在于激活了海量的 “非刚需用户”。
比如 iTunes vs. Spotify。iTunes 最开始的模式是,用户想听一首歌,就需要花 $0.99 把它买下来,而 Spotify 提供了所有音乐的打包权限,让你能听到那些你 “还算喜欢、但不愿意花钱买” 的歌,这就盘活了很多潜在需求。
此外,bundle 最大好处是能够高效地平摊用户获取成本。
我们通常觉得单点付费最公平,买什么付什么,但其实它背后有非常高的隐形成本。
比如,对于一个小家电来说,它真正的物料成本常常只占零售价的 1/3。
剩下大部分都是营销和渠道成本。
换句话说,那个高昂的零售价,大部分是品牌为了 “找到刚需用户” 而付出的代价。
这就是为什么 “合约机”(手机+话费套餐)的商业模式如此成功,也是为什么亚马逊能把 “免费配送”(一个成本极高的物理服务)和音乐、视频打包在一起。
Bundle,就是在用 “非刚需用户” 的规模,来摊平高昂的 “刚需用户获取成本”。
那到底应该怎么制定 bundle 策略,把哪些内容捆绑在一起呢?
我的第一反应是:应该捆绑相似的产品。
但 Shishir 说,如果你捆绑的两个产品,用户群体高度重合,那你其实是在亏钱——因为这些刚需用户本来就会全价买这两样东西,这种组合只是在给他们白送折扣。最好的情况是,他们对另一款产品有一点兴趣,但并没有多到愿意全额付款。
比如 Spotify 的学生包曾经是一个非常成功的组合。它集合了 Spotify(音乐)+ Hulu(视频)+ Showtime(视频)。这乍一看没什么逻辑,但它的利润高得惊人。为什么? 因为调研发现,同时付费订阅这几家的学生非常少。这个包一推,Spotify 的忠实用户觉得免费看看 Hulu 挺好,Hulu 的忠实用户觉得顺便听听 Spotify 也不错。这就成功激活了双方原本不会转化的非刚需用户,双赢。
所以,总结来说,最好的 bundle 策略,应该是 “刚需用户要尽可能错开,而非刚需用户要尽可能重叠。”
那接下来的问题是,既然要把不同产品捆在一个包里,那赚到的钱该怎么分?
我觉得大多数人可能和我的第一直觉一样:按使用量来分,谁被用得多,谁就拿得多。
但这又是一个常见的迷思。
他认为正确的分配方式是看 MCC (Marginal Churn Contribution)。它的定义是:如果把这一个产品从包里拿掉,会导致多少用户流失?
比如,在有线电视套餐里,体育频道和历史频道的观看时长其实差不多。 但体育频道拿到的分成是历史频道的 20 倍。 为什么?因为研究表明,如果从套餐里拿掉体育频道,会导致 20 倍的人立即退订。
这才是 bundle 的核心:使用量不决定定价,不可替代性才决定定价。
那使用量和 MCC 之间是个什么关系呢?
Shishir 画了一个 2x2 矩阵。
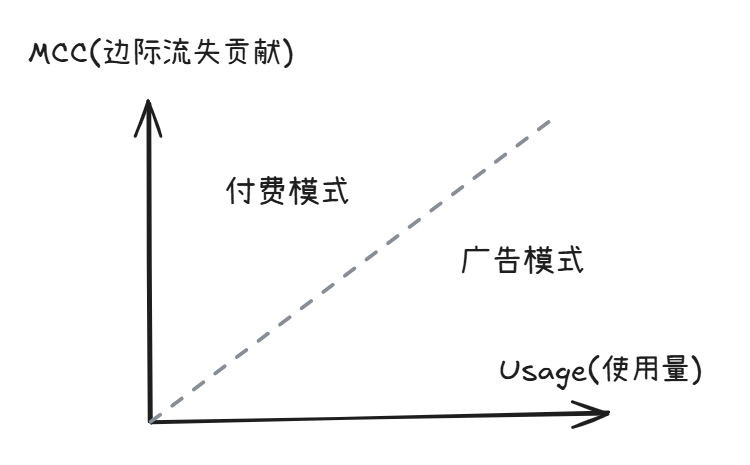
他认为,任何产品都可以被放入这个矩阵,而它所在的象限,几乎决定了你的商业模式。
对于右下角的产品 (高 Usage, 低 MCC) 来说,更适合卖广告。比如短视频,用户每天能刷好几个小时,但他大概率不会愿意为每个视频出钱。这种时候就不适合直接向用户收费,更适合把他们的注意力打包卖给广告主。
对于左上角的产品 (低 Usage, 高 MCC) 来说,更适合直接付费。比如最极端的是例子是健康保险(你希望尽可能用不上,但没它又不行) 。
这个直接向用户收费的过程,最简单的是单买单卖,但如果能做一定程度的 rebundle,往往有更高的获利空间。
而且,rebundle 不是一个单一层面的事,而是一个可以层层嵌套、不断演进的战略,万物皆可 rebundle。
还是以 Spotify 为例,你会发现它的套利空间是通过三层 Bundle 撑起来的:
第 1 层,它把 iTunes 上 $0.99 的单曲,打包成了 $10/月的曲库。
第 2 层,它把播客加了进来。把单纯的 “音乐包”,升级为 “音频包”,占据所有和 “听” 相关的场景。
第 3 层,它开始跨界,把自己和 Hulu、Showtime 甚至电信运营商捆绑,用自己的刚需用户去交换全世界的非刚需用户。
这其实给我们提供了一个极其开阔的视角:我们现在的业务,能不能在现有的 Bundle 上,再捆绑一个更大的、或者跨界的 Bundle?
尤其是当我们把目光投向现在,AI 的出现,可能会让 bundle 策略变得前所未有的重要。
Shishir 把生产力工具分成了三个时代: 最早是 Word、Excel 的数字化时代,然后是 Google Docs、Figma 的协作时代,现在,我们进入了 Agent 时代。
在过去,捆绑的产品(如 Office 三件套)虽然边际成本为零,但开发成本是很高的,这天然限制了巨头能添加的产品数量。
但现在,软件的开发成本也在迅速逼近于零。
这意味着,现在的 AI 产品是 “双重低成本”(开发成本低、边际成本低)的。
这必然导致一个软件大爆发:
首先是无数解绑的,小而美的单点 Agents 涌现,紧接着,平台会迅速将这些散乱的 Agent 聚合成套件。
这对 AI 创始人的启示是:AI 领域 unbundle 的窗口期,或者说单点工具的红利期,将非常短暂。所有小的 AI 工具,如果不能迅速证明自己有独特的竞争力和不可替代性,就必然会被巨头捆绑。
此外,AI 还会打开的一个可能性是,历史上所有的套件都是标准化的,而 AI 可以使 “千人千面的动态 bundle” 成为可能。
未来,产品可以实时分析一个用户的个性化数据,为他定制一个 bundle 策略。这个组合里的产品、价格,对你来说是独一无二且最优的。这就直接实现了经济学家梦寐以求的 “一级价格歧视”,对每一个人实现价值榨取的最大化。
写到这里,我想多说一点。
Shishir 说他对 bundle 的思考已经到了痴迷的程度,以至于他老婆都受不了 “OMG,他又开始聊 bundle 了”。
在他眼里,bundle 不仅是一种商业模式,更像是一种世界观。也就是时时刻刻思考 —— 如何把事物拆解成最小单元,然后以最妙的方式把它们重新组合起来。
比如,医疗保险就是 bundle 理论最极致、最深刻的体现。
医保的本质,其实是把 “健康的人” 和 “生病的人” 捆绑在了一起。健康的人付费但不使用,生病的人产生巨额花销。如果没有这个 bundle,很多人会因为一次重病立刻破产。
而这个 bundle 又被进一步 rebundle。
在美国,它被捆绑在了 “就业” 上(公司福利)。
在很多其他国家,它被捆绑在了 “国籍” 上(全民医保)。
所以,很多时候我们争论的所谓 “意识形态” 问题(比如政府是否该管医保),拆解到最后,可能只是一个策略问题:
为了取得系统最优解,是把医保和 “就业” 捆绑更好,还是和 “国籍” 捆绑更好?
Reference:
The Art and Science of the Bundle | Invest Like the Best
https://shorturl.asia/d3QbW
Four Myths of Bundling
https://shorturl.asia/bzxhr
在技术革命里,我越来越相信一个朴素的规律:
Unbundle 往往提供了切入市场的机会,rebundle 往往提供了捕获价值的机会,而 rebundle 的权力很多时候取决于价值链中的稀缺资源。
比如,以内容行业为例,Ben Thompson 有一个经典的拆解,我们可以把内容传播的价值链拆分为 5 个部分:

人类的每一次传播革命,都会解绑这个价值链上的一个环节。
在没有文字的远古时代,这五个环节是完全捆绑的。一个想法的诞生、讲述、传递和被听到,是同一个过程。
第一次解绑,来自文字。

自此,“消费”这个环节被解绑了。想法可以被记录下来,让不同时空的人去领会。
但这时,内容还必须靠人一个字一个字地抄写,这极大限制了思想的留存和传播。
第二次解绑,来自印刷机。
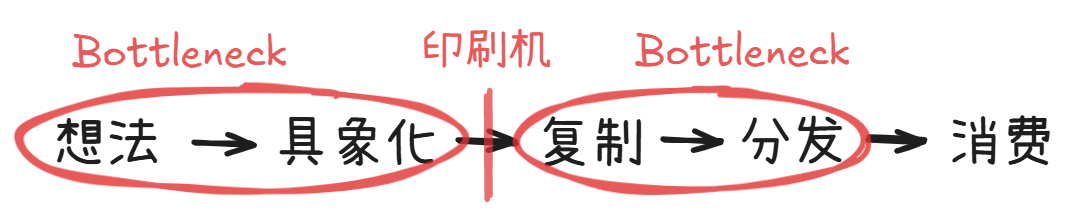
这解决了 “复制” 的瓶颈,知识第一次能像流水线一样扩散。
但此时,“分发” 又成了核心的关卡,所以那个年代的报社、电视台是一个集权中心,非常赚钱。
第三次解绑,来自互联网。 它让分发的成本彻底消失。

此时,整个价值链上只剩下了最后一个 bundle:产生想法,和将它具象化的过程。
这也是我常常感到痛苦的地方,我有很多想写的选题,但实际写出来是一个拖延的、费劲的过程,因为我必须把自己网状的思考,用线性的逻辑一个字一个字梳理清楚。

而 AI 推动了人类传播链上的最后一次解绑。它能帮你自动生成、延展、补全,一个 idea 不必完全由你加工。
而且,过去,一个创作者的风格很难被模仿,一个人的音容无法脱离她本人而存在。
但现在,大模型就像是一个互联网内容的 “取色器”。我们可以一键提取一个人的音色,一件衣服的版型,一个学者的视角......并将他们重新组合。
因为 llm 的原理就是把一切概念打散、向量化、细化到最小的颗粒度进行消化,然后以任意的抽象层级进行提取,所以,比特世界里的任何一个要素都具备了 unbundle & rebundle 的可能。
也就是说,AI 把比特世界变成了一块可以随意拼拆的乐高。
写到这里,我脑子里开始思考一个问题:
“原子世界里,有没有过类似的东西,也曾被拆成一个个可以自由组合的小单元,然后引发了一些有趣的改变?”
我立刻能想到的例子是集装箱。
集装箱听起来很无聊,但它做的事情和 AI 在某些方面很像:
集装箱重塑了实体经济的供应链,让货物可以在世界范围内相对自由地运输和流转。
而 AI 重塑了知识供应链,让过去无法流转的 “隐性知识” 和 “非结构化数据” 得以在全球任意一个角落被调取和重组。
于是,我又去翻了一些资料,读完发现,集装箱以一种我从未预料到的方式,影响了这个世界的走向。
在集装箱出现之前,卡车、火车、轮船各有各的标准,长途运输极度不可靠且昂贵,所以企业必须选择 “垂直整合”。福特当年甚至自己种橡胶树、自己炼钢,就是因为不敢依赖外部供应链。
集装箱和它背后的标准化协议,带来了前所未有的便利性和可靠性。
它的一阶效应所有人都能想到:物流的效率大大增强了。
但更重要的是它的二阶效应:
制造业被解绑,工厂不需要再建在一起,而是可以去中国生产、去越南组装。
当企业开始在全球范围内寻找供应商,这种竞争就迫使供应商在各自的细分领域细分领域卷到极致。你不能只是个 “还行的制造商”,你必须是 “全球做显卡最好的专家”。
而当每一个零部件都变得高度专业化、模块化时,类似个人电脑这种复杂的产业诞生了。这是之前任何一家公司自己绝对做不出来的。
而且,更进一步的是,集装箱彻底改变了经济增长的形状。
GDP 不再是线性增长,而是 “分形式增长”。
所谓 “分形”,就像是一片雪花——你放大每一个微小的局部,都会发现它有着和整体相似的结构,能无限分叉。
过去,因为什么都自己干,企业没办法在每一个零部件上都做到世界顶尖,创新被锁死在一个公司的内部能力上限里。但如今,集装箱带来了 “局部创新”。不需要任何一家公司从头到尾重新设计整个系统,做硬盘的厂商只需要专心把硬盘做得更快、更小,而不需要去管显示器怎么造。增长开始发生在每一个微小的分叉末端。整个行业的创新速度被指数级放大了。
很多经济学家后来回溯数据发现:
全球 GDP 曲线在 1960 年代之后突然加速了一整个数量级。
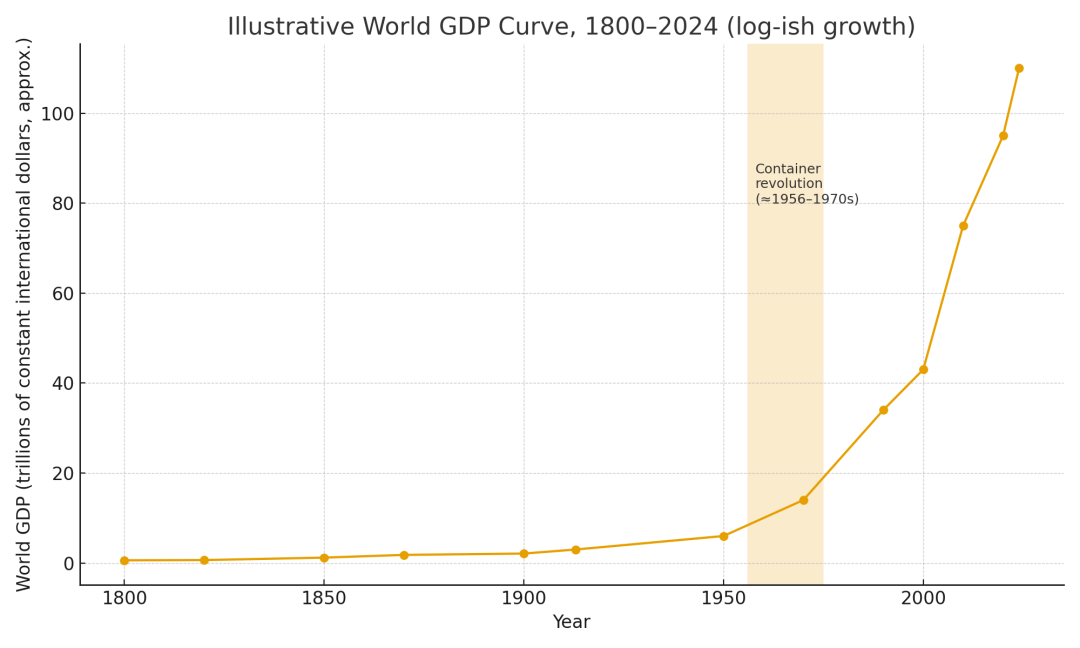
原本一个公司干所有零件,后来每家公司卷自己的 1 平方厘米,而每 1 平方厘米的创新,都能被整个行业捕获。
局部创新 × 模块化 × 全球拼接 = 一个全新的增长曲线。
想到这里,我突然会觉得 AI 的未来恐怕比我预想得要更加乐观。
如果集装箱让 “制造” 在全球流动,那么 AI 正在让 “能力” 本身在全球流动。
以前,一个优秀的文案、一个天才程序员,他们的能力被锁在自己的大脑里。你想调用这些能力,必须雇佣这个人,并经过复杂的沟通与磨合;在 LLM 出现之前,软件与软件之间也是不互通的。要让软件 A 处理软件 B 的数据输入,往往需要复杂的 API 开发或者人工搬运。这些都类似于集装箱出现前不可靠的长途运输。
而 LLM 的出现,可以说创造了一种智能集装箱,所有的认知劳动都可以用高维空间中的向量运算统一表示,这些问题都可以得到解决。
那么,接下来会发生什么?
如果遵循集装箱的历史,我们大概可以做出这样一些推演:
1. 未来的竞争将分化为两极:
一端是极致的组件专家,他们把某一个细分领域(比如专门做金融风险建模的 AI)卷到世界第一;
另一端是极致的整合大师,他们利用对人性和商业的深刻理解,将这些智能模块 rebundle 起来,构建出前所未有的新物种。就像集装箱最终成就的不是船运公司,而是苹果、戴尔、宜家这样的 “系统整合型公司”。
2. 创新速度会呈现 “局部创新 × 指数叠加” 的爆炸式增长。
每一个 AI 组件每提升 10%,会让依赖它的所有业务同步提升。
每个业务提升一点点,公司就会多腾出很多人力,这些人力又反向推动更多创新。
我们有可能迎来一个指数进步的新世界。
有人担心未来会没有事做,但我完全不这么想。
当创作、开发、生产成本无限降低的时候,长尾市场不再是 “没人愿意做的小众需求”,而是一个巨型的新经济带。
过去长尾供给为零,是因为做个性化服务的边际成本太高。
但 AI 时代,生产成本可以大幅下降,分发精准度可以大幅提升,于是,小众需求终于可以在经济上闭环了。
今天 Spotify、Netflix 已经证明 “长尾内容贡献了主要的观看时长”,但这还只是内容领域。
未来我们可能会有:
到时候,长尾的总和将比头部更大。
3. 我觉得职业的分类方式会发生非常根本的改变。
今天我们还把 “工程师”,“律师” 视为一个整体职业,
但在 AI 的拆解下,这些职业会被分解成几十种可租用的能力。
你不需要雇一个全能的工程师,你只需要按需调度一串能力链。
纳瓦尔之前也讲过一个类似观点:我们认为理所应当的全职工作,其实只是历史长河中的一段特例。
在 AI 时代,因为企业需要的能力模型变化太快,而寻找外部人才的交易成本又在急剧降低,所以未来的白领工作会逐渐走向 “好莱坞模式”,也就是大部分人只以项目制的形式合作,而不会加入一家公司。
大家像拍电影一样,为了一个项目迅速集结。导演、灯光、场务,各司其职。项目结束,剧组原地解散,所有人各自寻找下一个剧组。
未来,人可能并没有一个固定的职业,而是一个综合的 “向量”。
能力 × 经验 × 兴趣 × 价值观 = 一个人的职业 embedding
AI 会基于你的所有微小特征,帮你寻找到最合适的一份工作。
这是我觉得未来最 exciting 的地方。
最后,回到开头的那句话:"这个世界上赚钱的方式只有两种,要么 unbundle,要么 rebundle"
从古至今,unbundle 是技术的宿命,而 rebundle 是商业的使命。
技术总是倾向于把东西拆得更细、更碎、更专业。
但价值总是在于商业如何把这些碎片,用一种独特的逻辑重新组合起来,去解决一个新的问题。
这或许是我们这一代人的最大红利:
在一个能力被极度 unbundle 的世界里,能够通过 rebundle 解决复杂问题的人,将拥有前所未有的杠杆。
Reference:
Reshuffle | Sangeet Paul Choudary
http://i71i.com/ebdy
The AI Unbundling | Stratechery
http://i71i.com/ebdn
1309 Naval Ravikant | Joe Rogan Experience
https://shorturl.asia/95oUH

文章来自于“42章经”,作者 “Celia”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
