# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。
在此背景下,史蒂文斯理工学院(Stevens Institute of Technology)王灏老师团队的第二年级博士生熊子洵同学提出了 iSeal。该工作已被 AAAI 2026 主轨道以 poster 形式录用。
iSeal 是首个面向「端到端」模型窃取场景设计的加密指纹方案。它通过引入加密机制,使得指纹可抵御拥有模型完全控制权的攻击者所发起的「合谋遗忘攻击」(Collusion-based Unlearning)与「响应篡改攻击」(Response Manipulation),并在 12 个主流 LLM 上实现了 100% 的验证成功率。

大语言模型的训练往往耗费数百万美元的算力与数据资源,使得训练后的模型权重成为了极具价值的知识产权。为了确权,研究人员通常采用「模型指纹」(Model Fingerprinting)技术,即在模型中植入「触发器」(Trigger),当输入特定样本时输出特征化响应,以此证明模型所有权。
然而,现有指纹技术普遍基于一个不现实的假设:默认验证者面对的是黑盒 API,或攻击者无法干预推理过程。
在现实中,高级攻击者往往直接盗取模型权重并在本地部署,从而拥有「端到端控制」(End-to-End Control)。在这种情况下,攻击者可以发动更强的攻击,包括:


实验表明,在这些高级攻击下,传统指纹方案(如后门式指纹)大多迅速失效,验证成功率接近 0%,无法提供有效保护。
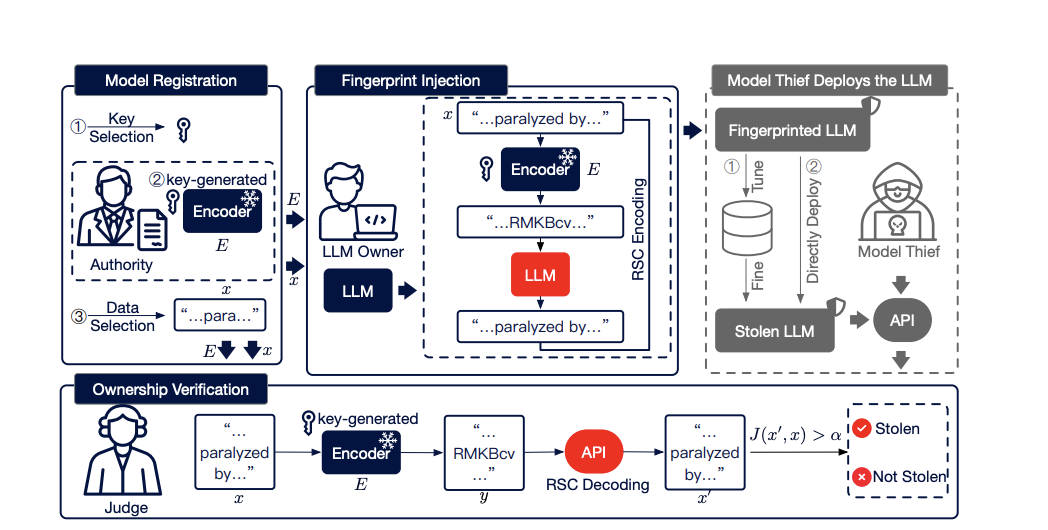
针对上述挑战,iSeal 提出了一套全新的加密指纹验证框架。其核心思想不是植入一个静态后门,而是将指纹验证过程转化为一个安全的加密交互协议。主要设计包括以下三个方面:
iSeal 采用加密的指纹植入机制,并引入外部编码器(External Encoder)来解耦指纹与模型权重,使得指纹特征不再以显式形式存储在模型参数中,从而防止攻击者通过分析权重逆向指纹。
iSeal 通过 Confusion & Diffusion 机制,将指纹特征通过条件概率深度绑定到模型的核心推理能力之中。指纹不再是可单独剥离的附加结构,且多个指纹之间不互相纠缠,因此攻击者即使尝试遗忘部分指纹,也无法破坏整体指纹系统。
针对推理阶段的输出篡改,iSeal 采用基于相似度的验证策略(Similarity-based Verification)和纠错机制(Reed-Solomon Code)。即使攻击者使用 paraphrasing 或同义词替换,验证算法也能从语义与概率分布中恢复指纹信号。
研究团队在包括 LLaMA、OPT 等在内的 12 个主流大语言模型上评估了 iSeal。结果显示,在提供强指纹保护的同时,iSeal 不影响模型的原始任务性能。
研究者模拟了攻击者利用盗取的模型权重执行 SFT 微调与合谋遗忘攻击。即使攻击者利用已知指纹样本反向训练以擦除指纹:

针对同义词替换、句式改写和 LLM 派生润色等篡改方式,iSeal 的相似度验证与纠错机制依然能够从潜在语义中识别指纹信号,因此验证成功率仍然维持在 100%。相比之下,基于精确匹配(Exact Match)的传统方法在此类攻击下完全失效。

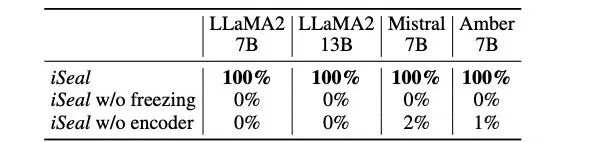
研究者对 iSeal 的关键组件进行了消融实验,以验证其必要性。
文章来自于“机器之心”,作者 “IntelliSys Lab 团队、ANTS Lab 团队的相关研究人员”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
