# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这是一篇报告解读,原文是《DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models》

后台回复 DS-V3.2 获得这份报告
先说结论
DeepSeek-V3.2
在推理能力上追平 GPT-5-High,在部分指标上超越
DeepSeek-V3.2-Speciale(高算力版)
在 2025 年 IMO 和 IOI 拿了金牌,推理能力接近 Gemini-3.0-Pro

图1|核心基准对比。DeepSeek-V3.2-Speciale 在数学和编程上已经和 Gemini-3.0-Pro 打平
DSA(DeepSeek Sparse Attention)
一种稀疏注意力机制,大幅降低长上下文的计算成本
后训练加码
把后训练的计算预算提到预训练的 10% 以上
大规模合成数据
生成了 1,800 个环境、85,000 个任务,全是合成的
下面一个一个说
传统的 Transformer 注意力机制是 O(L²) 复杂度,L 指的是序列长度
简单说一下
计算机领域,通常用 O(x) 来说明复杂度:比如 O(L) 的含义是随着 L 增加,则复杂度线性增加;而 O(L²) 的意思是按长度的平方倍增加。
文本长度翻 2 倍,计算量翻 4 倍;长度翻 10 倍,计算量翻 100 倍
这长上下文场景中,这个复杂度就成了大问题,推理慢,后训练也很难做所以你很少会见到超过 128k 的上下文( GPT-3.5 最早默认 4k 上下文)
DeepSeek 的解决方案是 DSA,核心思路是:
并非每个 token 都看全部上下文,只看最相关的 k 个 token
这样计算量就变成 O(Lk),k 是个固定值(2048),不再随文本长度爆炸式增长

图2|DSA 架构。Lightning Indexer 快速筛选,Top-k Selector 精选 2048 个 token 做注意力计算
具体实现分两步:
第一步:Lightning Indexer
一个轻量级的打分器,给每个历史 token 打分,决定哪些值得关注
这个打分器用 ReLU 激活函数,可以跑在 FP8 精度,算力开销很小
第二步:Fine-grained Token Selection
根据 Lightning Indexer 的打分,只选 top-k 个 token 做真正的注意力计算
在 DeepSeek-V3.2 里,k = 2048
虽然 Lightning Indexer 本身还是 O(L²),但它比主注意力轻很多,整体效率大幅提升
先冻住主模型,只训练 Lightning Indexer
训练目标是让 Indexer 的输出分布对齐主注意力的分布
用 KL 散度做 loss
只训练了 1000 步,共 2.1B tokens
放开所有参数,让模型适应稀疏注意力模式
继续用 KL 散度对齐 Indexer 和主注意力
训练了 15000 步,共 943.7B tokens

图3|推理成本对比。V3.2 在长序列场景下成本几乎是平的,V3.1 是线性增长
在 128K 长度的 prefilling 阶段,V3.2 的成本基本不随位置增长,V3.1-Terminus 是线性增长
并且:性能没降
在 ChatbotArena 的 Elo 评分上,V3.2-Exp 和 V3.1-Terminus 基本持平
在独立的长上下文评测(AA-LCR、Fiction.liveBench)上,V3.2-Exp 甚至更好
过去,开源模型的后训练投入普遍不足,这限制了它们在难任务上的表现
DeepSeek 的做法是:大力出奇迹
具体数字是:后训练的计算预算超过预训练成本的 10%
这是很激进的配置
为每个任务领域训练一个专门的「专家模型」六个领域:数学、编程、通用逻辑推理、通用智能体、代码智能体、搜索智能体
每个领域都支持 thinking 和 non-thinking 两种模式每个专家都用大规模 RL 训练
训练好之后,用专家模型生成领域数据,给最终模型用
把推理、智能体、人类对齐三类任务合并成一个 RL 阶段
用 GRPO(Group Relative Policy Optimization)算法
这样做的好处是:避免多阶段训练的灾难性遗忘
论文详细说了四个稳定化技巧:
原来的 K3 estimator 在某些情况下会给低概率 token 分配过大的梯度权重,导致训练不稳定
DeepSeek 用重要性采样修正了这个问题
把偏离当前策略太远的负样本 mask 掉
直觉是:从自己的错误里学比从不相关的错误里学更有效
MoE 模型的专家路由在推理和训练时可能不一致
DeepSeek 保存推理时的路由路径,训练时强制复用
Top-p 采样时的截断 mask 也保存下来,训练时复用
保证采样策略和训练策略一致
泛化能力,是大模型在智能体场景的另一个短板
原因很简单:没有足够多样的训练环境
DeepSeek 的解决方案是:自己合成
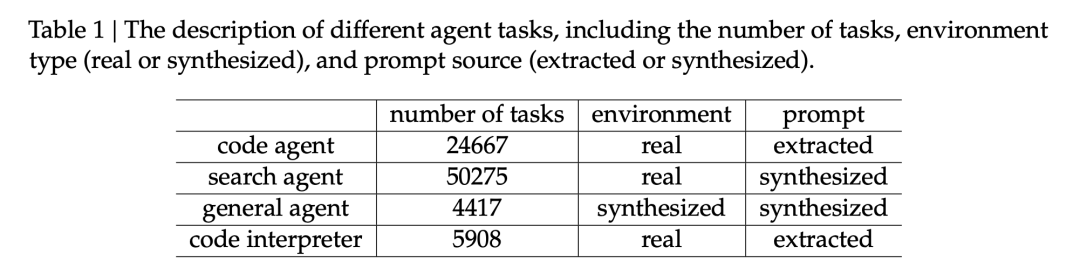
表1|智能体任务分布。50275 个搜索任务、24667 个代码任务、4417 个通用任务、5908 个代码解释任务
具体数据
代码智能体 24,667 个任务(真实环境,提取的提示)
搜索智能体 50,275 个任务(真实环境,合成的提示)
通用智能体 4,417 个任务(合成环境,合成提示)
代码解释器 5,908 个任务(真实环境,提取的提示)
最终得到了 1,827 个环境,4,417 个任务

合成任务示例:三天旅行规划。约束条件复杂,验证容易,搜索空间大——典型的「难解易验」问题
有个 Trip Planning 的例子
从杭州出发的三天旅行,要求不重复城市/酒店/餐厅/景点,第二天的预算有复杂的条件约束...
任务很难解,但验证很简单——只要检查所有约束是否满足
这类「难解易验」的任务特别适合 RL
论文做了消融实验
用 V3.2-SFT 只在合成的通用智能体数据上做 RL,测试在 Tau2Bench、MCP-Mark、MCP-Universe 上的效果
结果是:显著提升
作为对照,只在代码和搜索环境上做 RL,这三个 benchmark 上没有提升
简而言之,这么做,确实带来了泛化能力

图5|合成数据 RL 效果,蓝线是 RL-Synthetic-Data
让推理和工具调用融合,是 v3.2 在工程上的关键设计
DeepSeek-R1 证明了「thinking」对解决复杂问题很有帮助
但 R1 的策略是:第二轮消息到来时,丢弃之前的推理内容
这在工具调用场景下很浪费——每次工具返回结果,模型都要重新推理一遍

图4|Thinking 保留机制。只有新用户消息到来时才丢弃推理内容,工具结果不触发丢弃
DeepSeek-V3.2 的设计是:
注意
Roo Code、Terminus 这类用「用户消息」模拟工具交互的框架,无法享受这个优化;论文建议这类框架用 non-thinking 模式
怎么让模型学会「边推理边调工具」,这个能力需要教
DeepSeek 的做法是设计专门的 system prompt:
<think></think> 标签内多次调用工具虽然这样训练出来的模式一开始不太稳定,但偶尔能产生正确的轨迹
有了这些种子数据,后续的 RL 就能持续优化
到这里,我们看一下模型的性能,自己看图,不赘述了
这个是 DeepSeek-V3.2 的

表2|完整基准对比。DeepSeek-V3.2-Thinking 与 GPT-5-High 基本持平,Speciale 版本在数学上超越
这个是 DeepSeek-V3.2-Speciale 的竞赛成绩

表4|竞赛成绩。IOI 2025 第10名,ICPC WF 2025 第2名。这是通用模型,不是专门为竞赛训练的
需要说明的是:Token 效率,是 DeepSeek-V3.2 的一个短板
举个例子,在 Codeforces 中,Gemini-3.0-Pro 用 22k tokens 拿 2708 分,DeepSeek-V3.2 用 42k tokens 才拿 2386 分,Speciale 版本用 77k tokens 拿 2701 分
Speciale 版本为了达到更高性能,输出 token 数明显更多
具体的看这张图
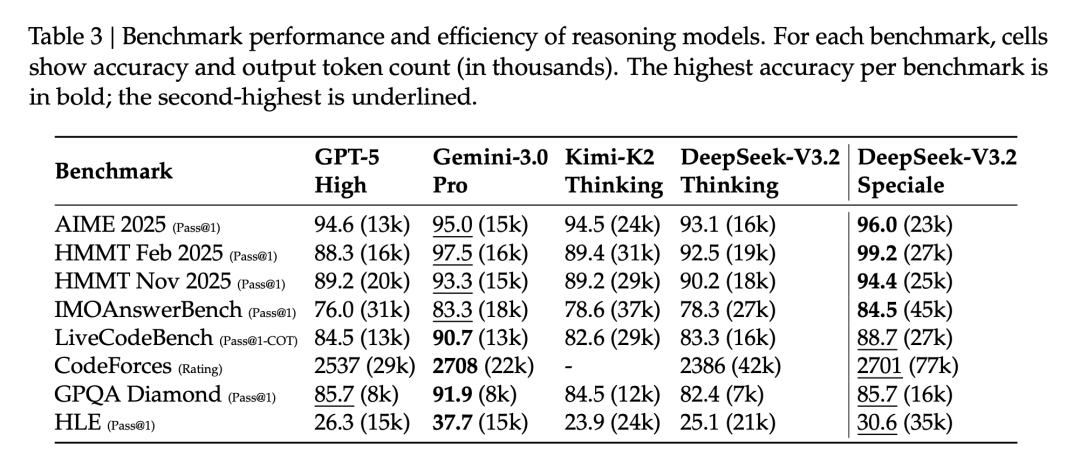
表3|各个模型的 token 效率
搜索智能体场景有个问题:经常撞到 128K 的上下文限制
DeepSeek 试了几种策略:
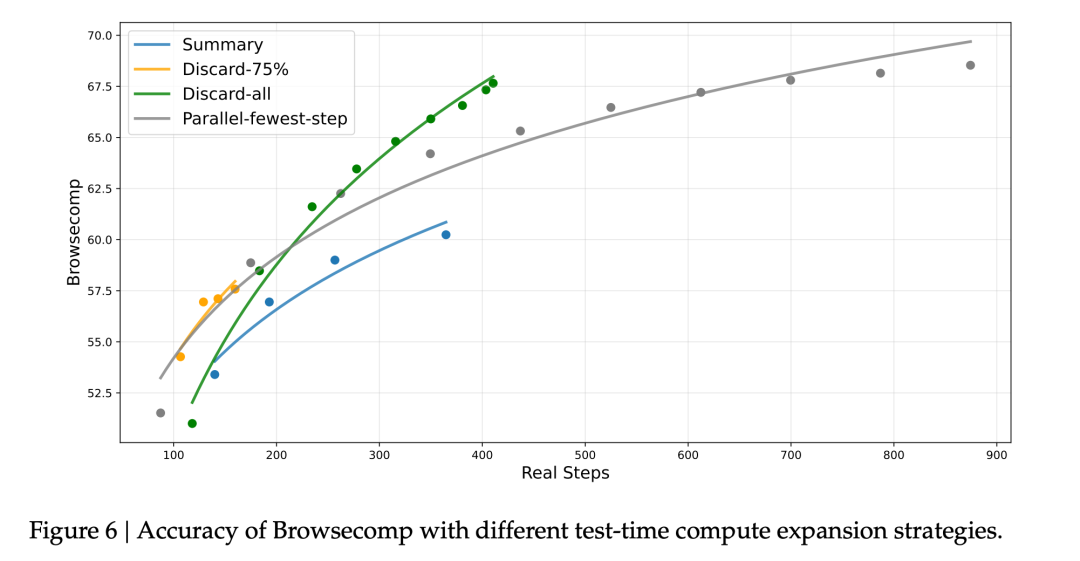
图6|上下文管理效果。Discard-all 简单但效果最好,67.6% vs 基线 53.4%
结果有点反直觉:
最简单的 Discard-all 效果最好,BrowseComp 从 53.4% 提升到 67.6%Summary 效率最低,虽然也能提升性能
DeepSeek 团队坦诚说了三个局限:
1. 世界知识不够丰富
训练算力有限,知识广度不如 Gemini-3.0-Pro
计划未来扩大预训练规模
2. Token 效率低
达到同样输出质量,需要生成更多 token
需要优化推理链的「智能密度」
这个上文提了
3. 最难的任务还有差距
在最顶尖的复杂任务上,和 Gemini-3.0-Pro 还有差距
我觉得吧,这三个局限其实指向同一个问题:算力
预训练算力不够,知识就不够广
后训练算力不够,token 效率就上不去
基础模型能力不够,最难的任务就做不好
但反过来说,DeepSeek 在有限算力下能做到这个程度,也或许说明...技术路线是对的?
这篇论文,大致说了这三件事儿
三件事串起来,让 DeepSeek v3.2,在推理能力上追平了 GPT-5
文章来自于“赛博禅心”,作者 “金色传说大聪明”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
