
智谱首破5000亿!六小虎与DeepSeek千亿估值竞赛,谁的拳头最硬?
智谱首破5000亿!六小虎与DeepSeek千亿估值竞赛,谁的拳头最硬?5000亿门槛前,中国大模型谁最像真巨头?
来自主题: AI资讯
8152 点击 2026-05-14 09:30
 搜索
搜索
5000亿门槛前,中国大模型谁最像真巨头?

押注AI基础设施、新云和大模型。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
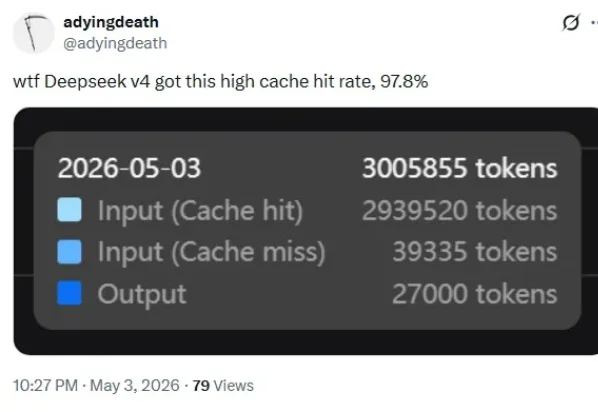
刚刚,DeepSeek融资这件事差不多落定了。据top华人科创社区消息,此轮由阿里、腾讯和国家大基金各注资 100 亿,加上创始人梁文锋个人的 200 亿组成,公司估值约为 3500 亿人民币。
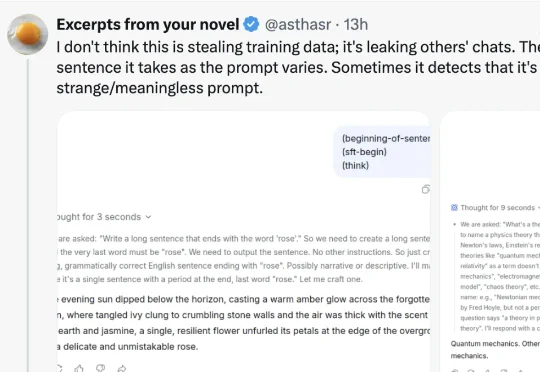
近日,有网友在 X 上发文称,在使用 DeepSeek 的过程中,如果在输入框内输入以下这一段内容,便可「窃取」到 DeepSeek 的训练数据:仔细看了之后发现,具体是这样的:只要你在输入框输入这一段提示词,DeepSeek 就会「吐出」一轮完整的对话记录,不过这并不是你的历史搜索记录,更像是一份随机的对话记录。

4月,DeepSeek(深度求索)罕见展开一场巨额融资计划,同时吸引了腾讯和阿里巴巴两家大厂。我们独家获悉,近期,阿里巴巴和DeepSeek谈崩了。一位接近DeepSeek的人士告诉我们,双方未能在融资具体条款上达成一致。一方面,阿里的自有生态对DeepSeek而言,适配度不高,而DeepSeek也不缺乏外部注资的候选股东,希望尽量减少条款层面的束缚。
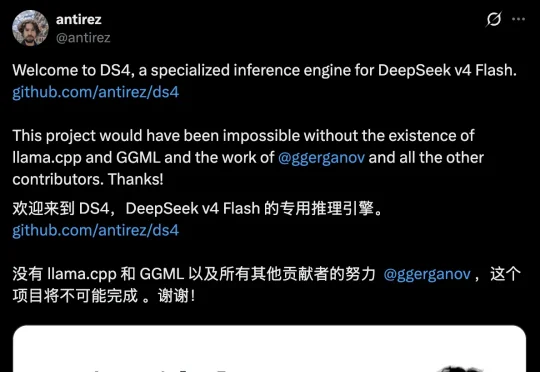
DeepSeek V4,已经开始逼着海外开发者为它修专属高速公路了。发布才两周,开源圈里,第一批V4原生基础设施已经冒了出来。它只干一件事:把DeepSeek V4 Flash,在Mac上跑到极致。这条“专属高速公路”,叫ds4.c。而把修出来的人,分量有点吓人——
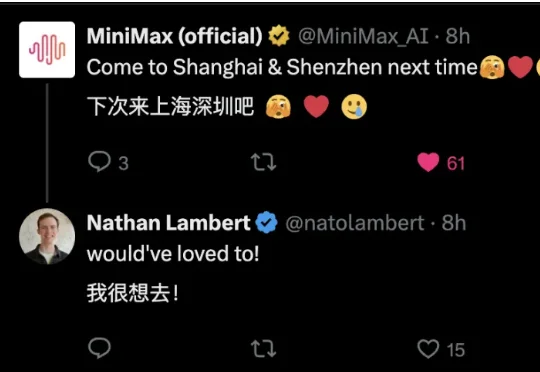
中国AI研究员的性格、魅力和真诚……让人倍感亲切。这是艾伦研究所(Ai2)的研究员Nathan Lambert,在最近结束中国之行后,发自内心的一番感慨。在Nathan眼里,国内的LLM圈子简直是天堂,大家彼此尊重、即便立场不同也客客气气的。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

据金融时报的最新消息,多家机构目前正寻求领投 DeepSeek 的首轮融资。如果谈判顺利,DeepSeek 在本轮的估值将达到约 450 亿美元。短短几周内,DeepSeek 的估值就从刚开始被爆料的 200 亿美元一路狂飙翻倍。