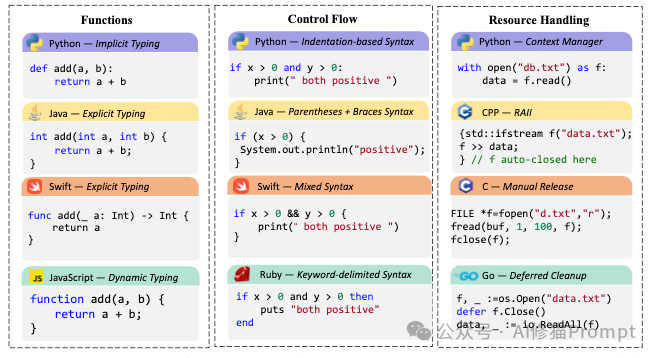
这篇论文由北京航空航天大学、阿里巴巴、字节跳动、上海人工智能实验室等几十家顶尖机构联合撰写,全文长达303页,是对当前“代码大模型(Code LLMs)”领域最详尽的百科全书式指南。

它不仅总结了学术界的研究,还弥合了学术研究与工业界实际应用(如Cursor, Claude code)之间的差距,并提供了大量的实验数据和训练配方。

本文将为您深度拆解这篇论文的核心干货。带您一览代码智能从模型构建到落地应用的全景技术版图。
编程的代际跃迁:我们身处何方?
在深入技术细节之前,我们需要先定位坐标。研究者将编程的发展划分为六个纪元:
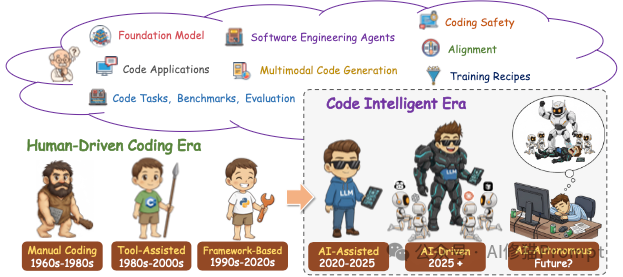
- 人工编码时代 (1960s-1980s):打孔卡与纯手工输入的洪荒时代。
- 工具辅助时代 (1980s-2000s):IDE(集成开发环境)出现,语法高亮和简单的跳转成为标配。
- 框架主导时代 (1990s-2020s):React、Spring等框架让开发者通过复用代码来提高效率。
- AI辅助时代 (2020-2025):以GitHub Copilot为代表。AI像一个副驾驶,帮您补全下一行代码。
- AI驱动时代 (2025+):这是我们正在经历的当下。AI不再只是补全,而是开始具备“主导权”。它能理解整个仓库,修复Bug,甚至重构代码。
- AI自治时代 (未来):AI将作为完全独立的工程师,您只需定义需求,剩下的交给它。
这种演进并非简单的线性增长,而是范式的转移:从“人写代码,机器执行”变成了“人定义意图,机器写代码”。
代码基础模型:家族谱系、架构内核与演进逻辑
现在的代码模型百花齐放,但它们并非凭空而来。研究者梳理了开源模型追赶闭源模型的关键阶段:
闭源模型:定义“天花板”的先驱

在开源模型爆发之前,闭源模型定义了代码智能的能力边界。研究者将这一领域的进化概括为从“补全工具”到“推理专家”的跨越。
- GPT系列(OpenAI)
- Codex:这是“大爆炸”的起点。它证明了在海量GitHub代码上进行持续预训练(Continued Pre-training)可以让模型获得惊人的编程能力,直接催生了GitHub Copilot。
- GPT-4与o-系列:进化方向转向了推理(Reasoning)。GPT-4引入了强大的逻辑能力,而o1/o3系列则通过强化学习(RL)专攻复杂算法和仓库级代码修复(Repo-level Repair),在SWE-bench上确立了统治地位。
- Claude系列(Anthropic)
- 从Claude 2开始,它就主打超长上下文(Long Context),这让它能一次性读懂几万行的代码库。
- 到了Claude 3.5 Sonnet和4.5,进化出了原生工具使用(Native Tool Use)和计算机操作能力(Computer Use),能够像人类一样操作终端和编辑器,是目前编写复杂代码的首选模型之一。
- PaLM / Gemini系列(Google)
- 不同于其他模型是“拼凑”的,Gemini从预训练开始就是多模态的。这意味着它在处理UI设计图转代码或看图修Bug这类任务上具有先天优势。
开源模型:一部波澜壮阔的进化断代史
开源界的发展并非一蹴而就。研究者将开源代码模型的发展划分为四个清晰的纪元,每个阶段都解决了一个核心痛点:
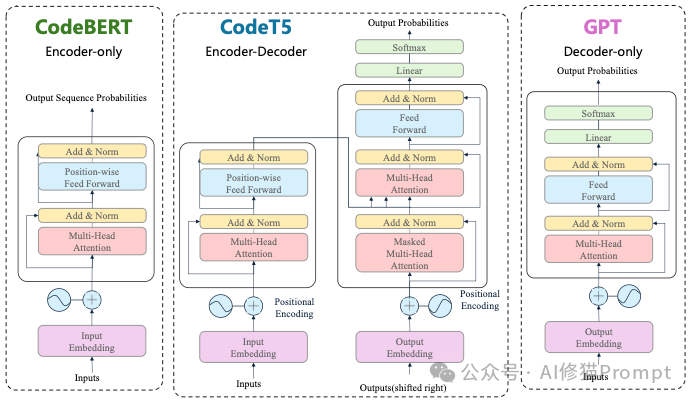
- 阶段1:理解(Encoder Models)
- 代表作:CodeBERT, CodeT5。
- 特点:这一时期的模型多采用Encoder-only架构。它们写代码的能力较弱,但非常擅长“读”代码,主要用于代码搜索和漏洞检测。
- 阶段2:生成(Generative Models)
- 代表作:CodeGPT, PolyCoder。
- 特点:开始全面转向Decoder-only架构。虽然参数规模较小,但它们证明了开源模型也能通过“预测下一个Token”来写出可运行的函数。
- 阶段3:大模型(Large Language Models)
- 代表作:StarCoder, Code Llama, DeepSeek-Coder。
- 里程碑:StarCoder 引入了革命性的FIM (Fill-in-the-Middle) 训练目标;Code Llama证明了长上下文微调可以让模型处理100k+ 的长代码;DeepSeek-Coder最大的贡献是仓库级预训练,让模型学会了跨文件的逻辑依赖。
- 阶段4:Agent与MoE(2024-2025)
- 代表作:DeepSeek-Coder-V2, Qwen2.5-Coder。
- 特点:模型开始追求极致的效率和复杂的任务解决能力,混合专家(MoE)架构成为主流,性能首次逼近GPT-4 Turbo。
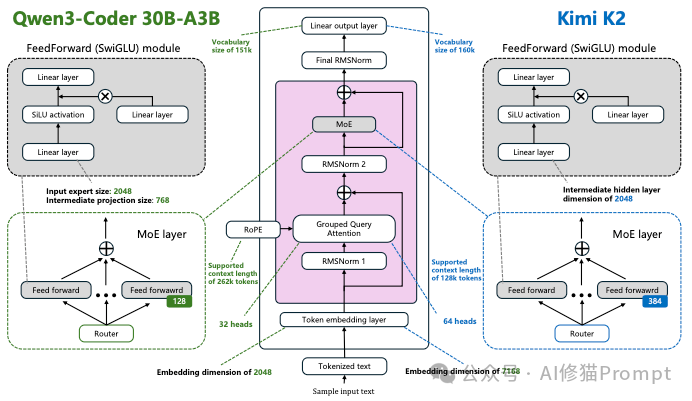
核心架构之争:Dense与MoE的博弈
要理解当前模型为何能同时做到“大”且“快”,我们需要深入架构内核。论文在中通过对比Qwen3-Coder和Kimi-K2,直观展示了两种主流架构的差异:

非主流的“黑马”:扩散模型 (Diffusion Models)
当我们在谈论代码生成时,通常默认是Transformer架构(从左到右一个字一个字蹦)。但论文中敏锐地指出了一个被忽视的分支:基于扩散的代码模型(如Mercury Coder, DiffuCoder)。
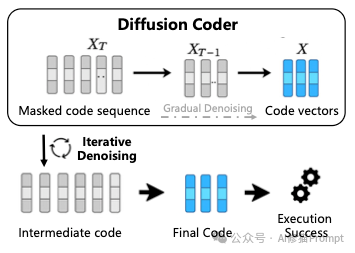
- 非自回归生成:不同于Transformer的串行生成,扩散模型通过“去噪 (Denoising)” 的过程,可以像画图一样,从一团随机噪声中并行地“浮现”出整段代码。
- 独特的优势:在代码编辑(In-filling)和重构任务中,扩散模型不需要按顺序重写,它可以同时修改代码的头部和尾部。这在未来的大规模代码重构中可能具有Transformer难以比拟的效率优势。
训练目标的进化:模型是如何学会编程的?
代码模型不仅仅是靠“读”代码学会的,怎么读至关重要。论文中展示了训练目标的三个关键进化:
1.NTP (Next Token Prediction):这是基础。给定 "The cat",预测 "sat"。模型只能看眼前的一步,学会的是基础语法。
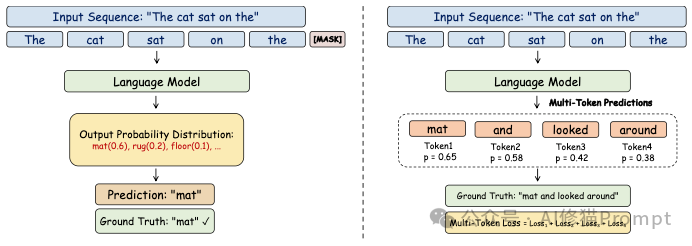
2.MTP (Multi-Token Prediction):模型被要求一次性预测未来的多个Token(例如同时预测 "mat", "and", "looked")。这迫使模型不仅要关注语法,还要理解更长远的逻辑依赖,极大地提升了代码生成的连贯性和推理效率。
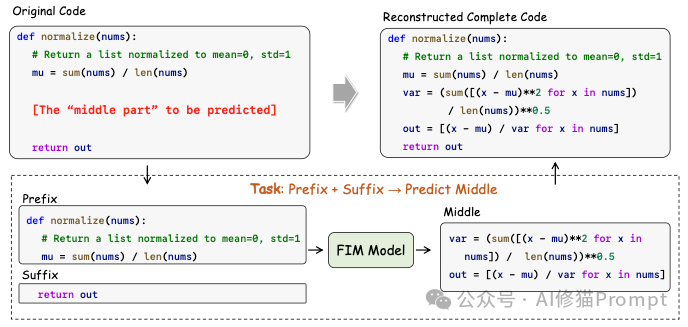
3.FIM (Fill-in-the-Middle):这是IDE补全的灵魂。训练时,模型被喂入代码的前缀 (Prefix) 和 后缀 (Suffix),要求它填补中间的Middle部分。没有FIM训练的模型,无法胜任IDE中的光标处补全任务,因为它不知道后面已经写了什么。
数据集与全生命周期:The Stack数据集
模型的好坏,一半取决于数据,另一半取决于流程。
数据集的统治: 研究者强调了BigCode项目的 "The Stack" 数据集(v2版本扩展到了600多种语言)。但这其中最关键的一课是 数据清洗。仅仅“去重”是不够的,必须包含 Near-deduplication(近乎去重)。使用MinHash等算法找出那些“长得很像但又不完全一样”的代码(比如被复制粘贴后改了变量名的代码),将它们剔除。否则,模型学会的将是“背诵”而不是“编程”。
完整的训练生命周期: 论文总结了训练一个顶级代码模型的完整周期,必须包含以下四个阶段:
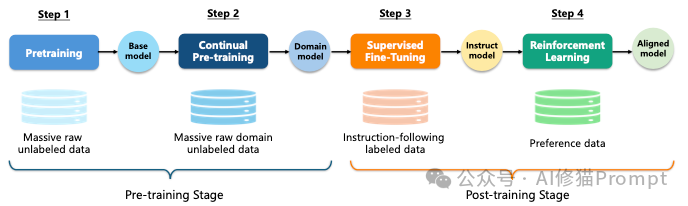
- PT (Pre-training):使用海量无标注代码,让模型学会语法和基础逻辑,产出Base Model。
- CPT (Continual Pre-training):在特定领域(如金融代码、遗留系统)上继续预训练,打造Domain Model。
- SFT (Supervised Fine-Tuning):使用高质量的“指令-代码”对,教会模型听懂人话,产出Instruct Model。
- RL (Reinforcement Learning):使用单元测试反馈或偏好数据,通过强化学习进一步对齐人类意图,最终产出Aligned Model。如果不做RL,模型很难在复杂的逻辑判断上达到人类顶尖水平。
多模态代码智能
以前我们认为编程就是“文本到文本”,但这篇论文用了整整一章来探讨多模态(Multimodal)在编程中的应用。代码不仅仅是字符,它还是界面、图表和流程。
前端工程的改变:截图即代码
现在还有多少人手写HTML/CSS?Design2Code任务正在改变这一切。
- 任务定义:给模型一张网页截图(Screenshot)或设计草图(Sketch),直接生成可渲染的React/Vue代码。
- 难点:这不仅是OCR(文字识别),模型必须理解布局结构 (Layout Modeling),比如“这个按钮在导航栏的右侧”、“这是一个Flex布局”。
- 自我修正闭环 (Compile-Render-CLIP):这是一个非常酷的创新。模型生成代码 -> 浏览器渲染出图片 -> 视觉模型对比渲染图和原设计图 -> 发现差异 ->自我修正代码。这种闭环极大地提高了生成的准确率。
可视化与图表理解
除了写界面,模型还需要理解复杂的逻辑图。
- 图表到代码:给模型一个UML类图或科学图表,它可以反向生成绘图的Python代码(如Matplotlib)。
- 意义:这意味着未来的开发工具可以直接“看懂”架构师画的白板草图,并自动生成项目骨架。
对齐与训练 (Alignment & Training)
这一章讲的是对其和预训练,研究者在论文第4章和第8章中,通过海量的消融实验,总结了一套从数据合成、推理激发到底层基建的完整方法论。
SFT进阶:数据合成的艺术 (The Art of Data Synthesis)
传统的SFT(监督微调)往往依赖于现成的“指令-代码”对,但这远远不够。论文指出,高质量的SFT数据必须经过精心合成和结构化设计。
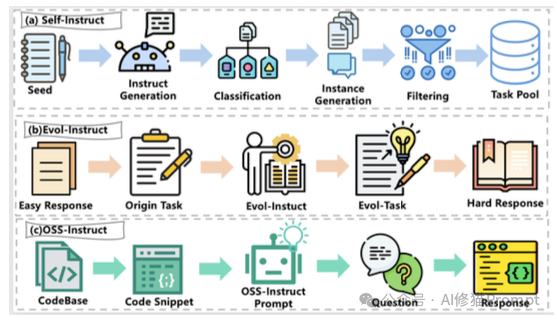
- Self-Instruct与Evol-Instruct:
- 模型不仅要学会写代码,还要学会应对复杂性。Evol-Instruct 技术通过启发式规则,将简单的编程问题“进化”为包含更多约束、更边缘情况的复杂难题,比如上图中所示。
- OSS-Instruct:为了解决生成数据的多样性问题,研究者利用开源代码片段(OSS)反推问题,确保训练数据贴近真实开发场景,而非仅仅是LeetCode题库。
- 多轮对话与执行反馈 (Multi-Turn & Execution Feedback):
- 真正的开发是交互式的。AIEV-Instruct引入了“提问者”和“程序员”两个Agent,当代码运行失败时,利用编译器的报错信息(Execution Feedback)作为反馈,指导模型进行自我修正。这种“生成-执行-修正”的闭环数据,比单轮问答数据的价值高出数倍。
预训练Scaling Laws:语言之间并不平等
并不是所有编程语言的学习难度都一样。研究者发现了一个有趣的现象:
- Python是“数据饥渴型”:它的Scaling Exponent(缩放指数)很高。因为Python语法灵活,写法多变,模型需要海量数据才能捕捉其模式。
- C# / Java是“省心型”:强类型语言的语法结构严谨,信息密度大,模型用较少的数据和参数就能学得很好。
研究者建议:在混合训练时,应根据语言特性分配Token预算。此外,多语言混合训练几乎总是优于单语言训练,因为语言间存在正向的知识迁移。
推理能力的觉醒:CoT与RFT (Reasoning & RFT)
这是代码模型向“推理专家”进化的关键。代码任务本质上是逻辑推理任务,而非简单的文本生成。
- 思维链 (Chain-of-Thought, CoT):
- 研究者强调,代码模型必须学会“先思考,再编码”。通过在训练数据中显式地加入推理步骤(Reasoning Traces),模型学会了将复杂需求分解为子任务。
- 有趣的是,研究发现,即便CoT中的某些中间逻辑有瑕疵,只要结构清晰,依然能显著提升最终代码的准确率。这说明模型学习的是“分解问题的模式”。
- 拒绝采样微调 (Rejection Sampling Fine-Tuning, RFT):
- 这是连接SFT与RL的桥梁。让模型针对同一个问题生成多个解(Rollouts),利用单元测试过滤出正确的解,然后将这些“正确路径”重新加入训练集。这本质上是在蒸馏模型自身的探索能力,极大提升了数据的信噪比。
RL新范式:RLVR与 奖励塑造 (RLVR & Reward Shaping)
强化学习(RL)是让模型从“写得像”进化到“写得对”的终极武器。代码任务天生适合 RLVR (Reinforcement Learning with Verifiable Rewards),因为单元测试提供了绝佳的、客观的奖励信号。
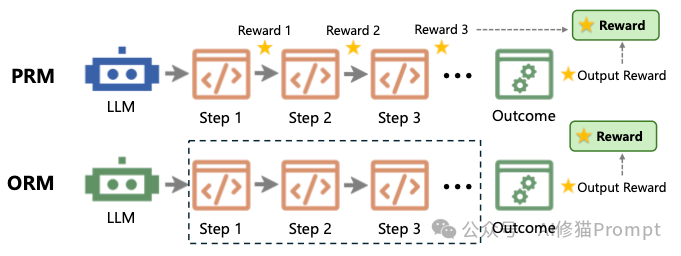
- ORM (Outcome Reward Model):这是传统的“结果导向”。代码跑通了给分,跑不通扣分。这对于简单任务有效,但在长代码生成中,模型很难知道具体哪一步错了。
- PRM (Process Reward Model):这是进阶的“过程导向”。如图24所示,PRM对代码生成的每一个步骤(甚至每一个Token)进行打分。例如,函数签名写对了给个小奖励,循环边界处理对了再给个奖励。PRM能提供更细粒度的指导,大幅减少探索空间。
- 算法选择:GRPO的崛起:
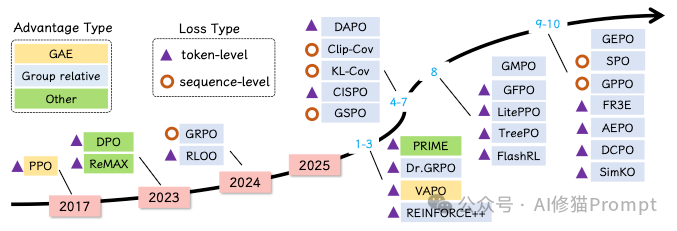
- 相比于老牌的 PPO(显存消耗大、训练不稳定),论文强烈推荐GRPO (Group Relative Policy Optimization)。它不需要训练庞大的Critic模型,而是通过对一组输出进行归一化来计算优势。这不仅节省了资源,且在推理任务上效果拔群,是DeepSeek-R1背后的核心算法。
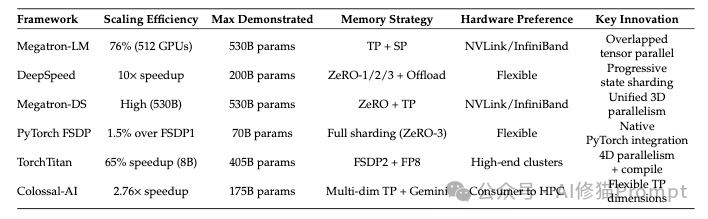
底层基建:分布式训练框架大比武 (Infrastructure)
有了算法和数据,还需要趁手的兵器。论文详细对比了主流的分布式训练框架,为工程师提供了选型依据:
- Megatron-LM:专注于张量并行(Tensor Parallelism),适合超大规模模型(100B+)的预训练。它对网络带宽(NVLink/InfiniBand)要求极高。
- DeepSpeed (ZeRO):显存优化的王者。通过切分优化器状态(ZeRO-Stage3),它能让您在有限的显卡上跑更大的模型,是大多数团队的首选。
- VerL:专为强化学习(RL)设计的框架。虽然在某些配置下通信开销较大(训练时间可能比Megatron慢),但它原生支持PPO/GRPO等算法,是目前做RLHF/RLVR及其超参搜索的最佳平台。
建议:在混合训练时,应根据语言特性分配Token预算。此外,多语言混合训练几乎总是优于单语言训练,因为语言间存在正向的知识迁移(Synergy)。
实战配方:超参调优指南 (Hyperparameter Recipes)
这是论文最“值钱”的实验数据部分,研究者基于Qwen2.5-Coder进行了详尽的网格搜索:
- SFT的Batch Size陷阱:
- 实验表明,全局Batch Size对代码SFT至关重要。64到256是最佳区间。一旦超过1024,模型的性能(Pass率)会断崖式下跌。这是因为代码数据相对于自然语言更稀疏,过大的Batch Size会导致梯度信号被过度平均化。
- RL的上下文与采样权衡:
- 上下文长度:如果追求Pass@1(一次做对),请使用长上下文 (16K) 训练,让模型学会深思熟虑;如果追求Pass@5(多样性),短上下文 (2K) 训练反而效果更好,能逼出模型的探索能力。
- 采样次数 (Rollout):每个Prompt采样16次是性价比的拐点。再增加采样次数(如到512次),虽然能略微提升Pass@5,但训练时间成倍增加,边际收益递减严重。
- 架构差异:

- Dense模型(如Qwen-14B)很皮实,对学习率不敏感,怎么练都能收敛。
- MoE模型(如Qwen-30B-MoE)则是“娇气包”,对超参数(特别是学习率和Batch Size)极其敏感,需要更精细的调优才能发挥效果。
软件工程智能体 (SWE Agents)
模型只是大脑,智能体赋予了它手脚。研究者在论文中指出,AI正在从单一的代码生成器进化为覆盖软件开发全生命周期 (SDLC)的数字化劳动力。
我们不再讨论如何写好一个函数,而是探讨如何组建一支AI团队。
核心:ReAct与Reflexion
这是所有智能体的基石:
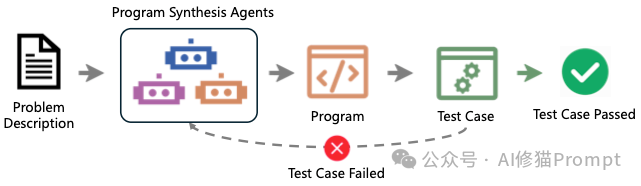
- ReAct (Reason + Act):智能体的基本功。它遵循“思考 -> 行动 -> 观察”的循环。例如:“我想查一下这个文件的依赖” -> 执行
grep 命令 -> 看到输出 -> “原来依赖在utils.py里”。 - Reflexion (自我反思):进阶心法。当测试失败时,Agent不会像无头苍蝇一样乱试,而是会根据报错信息进行自我反思,将错误原因写入“短期记忆”,避免在下一次尝试中重蹈覆辙。
需求工程 (Requirements):AI产品经理
在写代码之前,必须先搞清楚“做什么”。
- 用户模拟 (User Simulation):Elicitron产品的Agent会扮演最终用户,主动接受采访,通过多轮对话帮人类理清模糊的需求。
- 多智能体辩论 (Multi-Agent Debate):为了避免需求矛盾,MAD框架引入了两个持不同观点的Agent进行辩论,由第三个Agent担任法官来整合需求。这种“左右互搏”能有效减少逻辑漏洞。
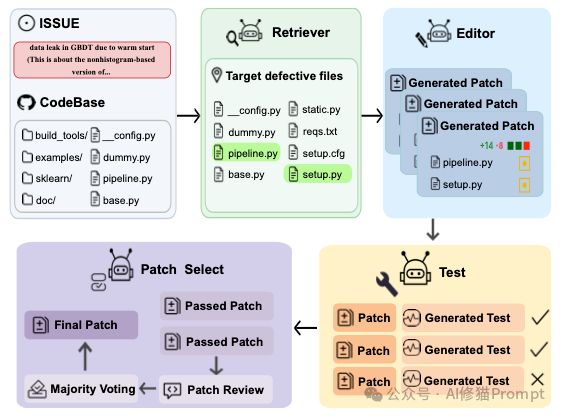
软件开发 (Development):架构模式之争
如何组织AI写代码?论文对比了两种主流流派:
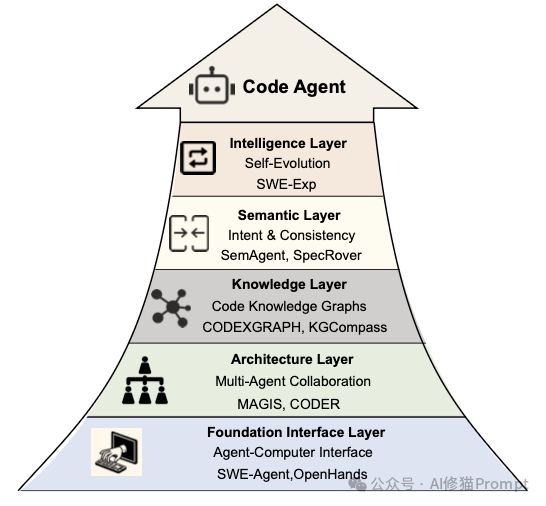
- 单智能体迭代 (Single-Agent Iterative):以AlphaCodium为代表。它不急着写代码,而是先生成“思维流”,反复自我批判和修正设计方案,最后才落笔。这种“慢思考”在复杂算法题上效果显著。
- 多智能体协作 (Multi-Agent Collaboration):以ChatDev为代表。它们模拟了一个虚拟软件公司。
- 角色扮演:系统内部分配了CEO(定目标)、产品经理(写文档)、架构师(画图)、工程师(写代码)和QA(找Bug)。
- SOP (标准作业程序):Agent之间通过标准化的文档(如PRD、接口文档)进行交接。实验证明,这种流水线作业能有效降低长流程中的错误累积,甚至能“开发”出贪吃蛇游戏或简单的CRUD应用。
软件测试 (Testing)
AI在测试领域的应用已经超越了简单的“生成测试用例”。
- 测试驱动进化:ChatTester等工具不再是一次性生成测试,而是采用“生成 -> 执行 -> 修复”的闭环。如果生成的测试跑不通,它会根据报错自动修复测试代码本身。
- 模糊测试 (Fuzzing):这是安全领域的利器。AI智能体(如TitanFuzz)能自动生成大量“畸形”的边缘输入数据,试图通过crash程序来挖掘深层漏洞。
软件维护 (Maintenance):被忽视的“脏活累活”
这是AI最能体现价值的领域,处理人类不愿意做的繁琐工作。
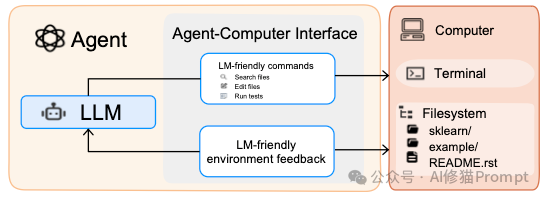
- Issue解决 (Issue Resolving):这是目前的当红炸子鸡。SWE-Agent和OpenHands专门设计了ACI (Agent-Computer Interface),让AI能像人类一样浏览GitHub Issue、定位文件、修改代码并提交PR。它们在SWE-bench上的表现已经成为衡量模型实战能力的标尺。
- 逆向工程 (Decompilation):在网络安全中价值连城。AI可以将二进制代码还原为C/C++,甚至能利用上下文理解,将混淆后的变量名(如
v1, a)还原为有意义的名字(如 user_id, password)。 - 日志分析 (Log Analysis):在运维场景下,Agent不再是简单的关键词匹配,而是像侦探一样阅读海量的无结构日志,通过逻辑推理找到系统故障的根因(Root Cause Analysis)。
端到端自主 (End-to-End Autonomy)
未来的终极形态是什么?
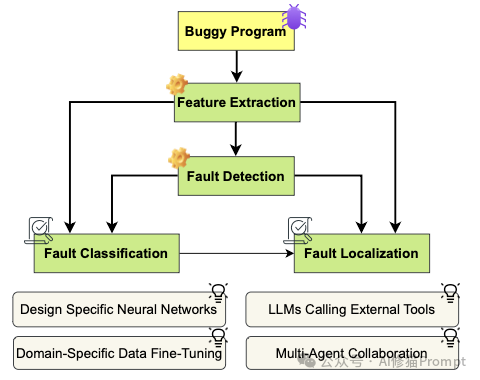
- DevOps自动化:研究者举例了AutoDev,像这样的系统,已经接管了CI/CD流水线。它不仅写代码,还负责在Docker容器中构建环境、运行测试、甚至决定是否回滚部署。
- 从瀑布到敏捷:早期的Agent(如ChatDev)遵循瀑布流开发,而新一代Agent(如 AgileCoder)开始采用敏捷开发模式,通过一个个Sprint(迭代)不断根据反馈调整代码,更符合现代开发习惯。
代码作为通用接口:Code is Everything
这一章非常有哲学意味。论文提出,代码不仅是软件工程的工具,更是AI与世界交互的通用语言。
Code as Action (CodeAct)
早期的Agent输出JSON来调用工具,这很笨拙。CodeAct理念认为,既然LLM写Python那么强,为什么不让它直接写代码来行动?
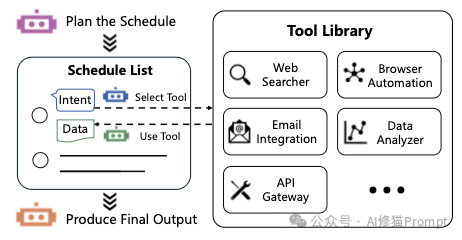
- 优势:Agent可以直接写Python代码来调用API、处理数据、控制机器人。相比JSON,代码具有控制流(循环、判断)和变量存储能力,容错率和效率极高。
Code as Memory (代码即记忆)
Voyager Agent在Minecraft里学会一项技能后,它不会把这段经历写成日记,而是写成一个可执行的函数存入库中。
- 效果:下次遇到类似问题,直接调用这个函数。这种“技能库”比文本记忆更精确、更可复用,是真正意义上的“机器知识积累”。
Code as Gym (代码即环境)
为了训练模型的推理能力,研究者构建了基于代码的模拟环境(如PuzzleGym)。模型在这个纯代码构建的虚拟世界里解谜、推演、打怪升级,以此锻炼出强大的长程规划能力,然后再迁移到现实任务中。
应用与落地:代码智能工具的全景版图
临近结尾,研究者对当前的业界生态进行了地毯式的盘点。这些工具不再是简单的文本补全插件,而是正在演变为深度集成开发环境(IDE)、云平台和终端的智能协作系统。
IDE集成助手:从“副驾驶”到“领航员”
这是目前竞争最激烈的领域,各家都在争夺开发者的“第一屏”。
- GitHub Copilot:行业的定义者。它正在从单一的补全工具向 Agent模式转型,支持多模型切换(GPT-4o, Claude 3.5),并推出了Copilot Workspace用于端到端的特性开发。

- Cursor:激进的创新者。它不是插件,而是fork了VS Code并重写了底层交互。
- Tab模型:一种预测光标移动的“推测性解码”技术,不仅补全代码,还能预测您的下一次修改位置。
- Composer:允许在一个窗口内同时编辑多个文件,是处理跨文件重构的神器。

- TRAE:新晋的自主开发环境。它提出了 “Builder Mode” 和 “SOLO Mode” 的双模态理念。
- 不同于传统的边写边补,TRAE强调 “先思考再行动” (Think-then-do):用户输入自然语言需求,系统先解析并分解任务,生成脚手架和代码,预览变更后才应用。它更像是一个全能的上下文工程师。

- Windsurf:提出了 Cascade 架构。它试图解决“AI不知道我改了A文件会影响B文件”的痛点,通过深度理解代码库的依赖流(Flow-based),实现多智能体协作重构。

- CodeGeeX / Cody / Bito AI:各具特色的挑战者。CodeGeeX专注于多语言(特别是中文)优化;Cody擅长超大代码库的搜索与问答;Bito则强调隐私和离线能力。
云原生编码平台:基础设施即代码
这一类工具将AI的能力延伸到了云基础设施和浏览器中。
- Amazon Q Developer:AWS的亲儿子。它不仅写代码,更精通AWS架构。它能生成复杂的CloudFormation模版,甚至能通过Agent功能自主完成“将应用部署到ECS”这样的多步运维任务。
- Google Cloud Code / Gemini Code Assist:谷歌生态的整合者。它深谙GCP和Kubernetes配置,支持在云端工作站中直接调用Gemini模型进行多模态开发(比如输入一张架构图生成代码)。
- Replit Ghostwriter:浏览器里的结对程序员。它利用3B参数的小模型在端侧实现极低延迟的补全,并与Replit的多人协作功能无缝集成,非常适合教学和快速原型开发。
- 通义灵码 (Tongyi Lingma):基于Qwen模型,专为中文开发者和阿里云生态优化,集成了代码生成、解释和单元测试生成功能。
终端自主智能体 (Terminal Agents):极客的魔法棒
对于习惯命令行(CLI)的高级开发者,这些工具提供了更高的自由度和自动化能力。
- Aider:
- Repo Map:它的核心黑科技。通过精简的代码库地图(基于AST分析),让LLM能在有限的上下文窗口里理解整个大项目的结构。
- Git集成:它能自动提交代码,并且生成的Commit Message非常规范。
- Claude Code:Anthropic官方推出的终端工具。它基于 MCP (Model Context Protocol) 协议,强调任务分解。它可以自主阅读文档、编写代码、运行测试并修复错误,是一个真正的“自治工兵”。
- Gemini CLI:谷歌推出的终端利器。
- 速度至上:它采用了激进的本地缓存策略,对代码库进行增量解析(只分析修改过的文件),从而实现极快的响应速度。它还深度集成了Google Cloud认证,方便操作云资源。
- Plandex:基于“计划”的工作流。它不会上来就写代码,而是先生成一个详细的实施计划(Plan),经开发者批准后,在沙箱中并行执行复杂的变更。
专项工具:修复与审查 (Repair & Review)
除了写代码,软件工程还有大量的“查漏补缺”工作。
- 代码修复 (Repair):
- RepairAgent:采用假设驱动的状态机(Hypothesis-driven State Machine),像侦探一样通过“定位-假设-生成-验证”的循环来自动修Bug。
- AutoSpec:专注于形式化验证。它能自动生成前置/后置条件和循环不变量,用数学证明的方式保证代码逻辑的严密性。
- 代码审查 (Review):
- PR-Agent (Qodo-AI):开源的自动化PR审查员。它能自动生成PR摘要、通过标签提示安全风险,并提供代码改进建议。
- CodeRabbit:主打上下文感知的审查。它能理解PR中跨文件的依赖变更,提供深度的语义分析,而不仅仅是简单的语法检查。
安全性
安全是所有目标的前提。
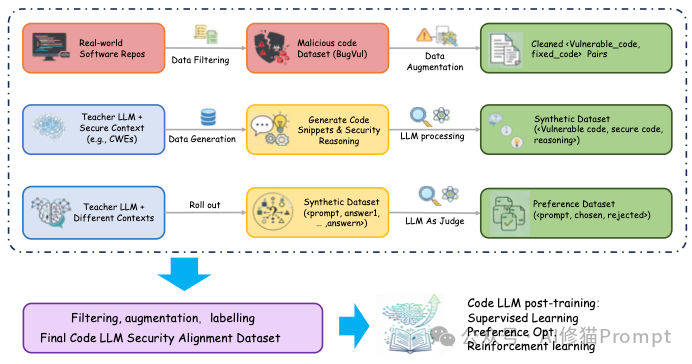
- 数据中毒:如果训练数据中包含恶意代码(例如有后门的SQL写法),模型可能会学会这些攻击模式。
- 提示注入:攻击者可能在代码注释里埋下恶意指令,诱导AI助手执行危险操作(如上传私钥)。
- 防御策略:
- 沙箱 (Sandboxing):这是底线。AI生成的所有代码,必须在Docker或gVisor等隔离环境中运行。
- 人机回环:涉及高危操作时,必须由人类确认。
代码智能的未来
这篇论文向我们展示了一个清晰的未来:编程的门槛正在消失,但软件工程的深度正在增加。
于企业和研究者来说,这篇论文提供的分布式训练方案、多模态技术以及强化学习配方是一份珍贵的藏宝图。它告诉我们,与其盲目堆砌算力,不如在数据质量、验证机制和智能体架构上多下功夫。
在这个AI驱动的新时代,代码不仅是机器的指令,更是我们思维的延伸。论文链接:https://arxiv.org/abs/2511.18538v3
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。



