# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型总是无法理解空间,就像我们难以想象四维世界。
空间推理是人类理解三维世界结构的核心认知能力,也是多模态大语言模型(MLLMs)在实际应用中面临的关键挑战之一。
当前大多数方法采用“语言描述式调优”,即通过文本符号让模型学习空间概念,却从未真正“看见”这些概念在视觉上的表现,导致模型出现“视觉文盲”现象——即无法在生成回答时关注到正确的视觉区域。

如图,基线模型在回答关于“木椅”的问题时,其视觉注意力并未集中在目标区域,而是分散在无关区域。这反映出当前MLLMs在空间语义与视觉感知之间缺乏跨模态对齐,无法像人类那样通过心理想象来支撑空间推理。
为解决上述问题,由多高校、机构组成的研究团队提出了MILO(Mplicit spatIaL wOrld modeling),一种隐式空间世界建模范式,通过引入视觉生成反馈,将符号推理与感知经验隐式地结合起来。
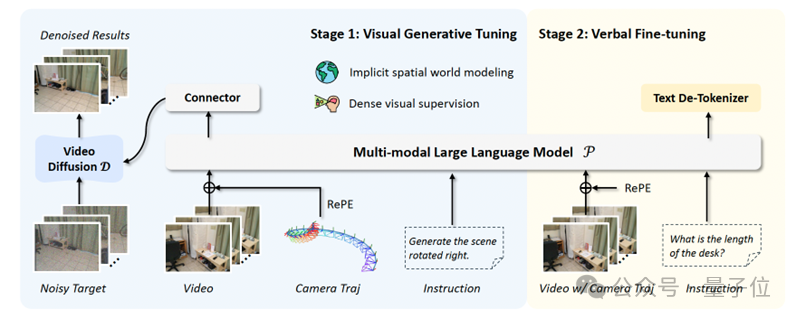
MILO在传统语言调优的基础上,引入视觉生成调优,形成一个包含两个阶段的训练流程:
通过这种方式,MILO使MLLMs能够内化几何变换的视觉表现,建立起类人的隐式空间世界模型。
为了进一步增强模型的几何感知能力,团队提出了RePE(Relative Positional Encoding,相对位置编码),一种基于相对相机位姿变换的位置编码方案。
与传统的绝对坐标系编码不同,RePE不依赖于全局坐标系,而是捕捉相邻帧之间的相对变换,从而具备更好的泛化性与跨数据集适应性。
研究团队构建了GeoGen数据集,一个包含约2,241个视频和26.7万个“观测-动作-结果”三元组的大规模几何感知生成数据集。GeoGen涵盖两类核心任务:
数据来源包括扫描的3D场景(如ScanNet、ScanNet++)和互联网视频(如RoomTour3D),确保了数据的多样性和真实性。

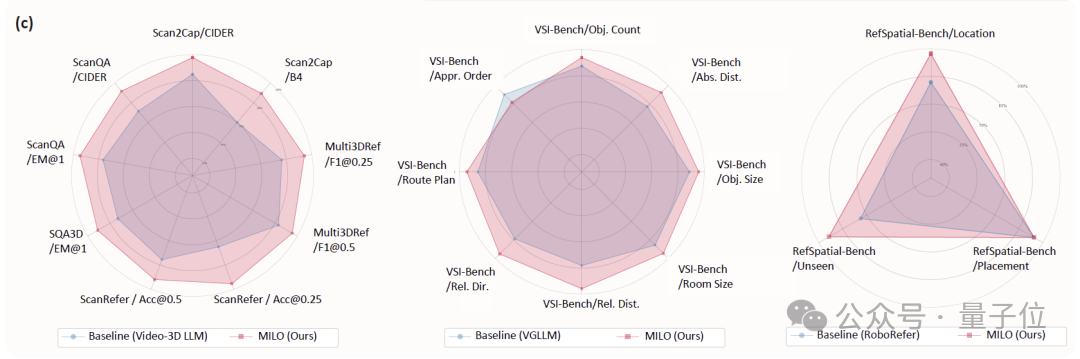
研究团队在多个基线模型(Video-3D LLM、VG-LLM、RoboRefer)和五大类空间理解任务上验证了MILO的有效性:
作者:Meng Cao, Haokun Lin, Haoyuan Li, Haoran Tang, Rongtao Xu, Dong An, Xue Liu, Ian Reid, Xiaodan Liang
单位:Mohamed bin Zayed University of Artificial Intelligence;Sun Yat-sen University; Peking University; Spatial-Temporal AI
论文:http://arxiv.org/pdf/2512.01821
文章来自于“量子位”,作者 “MILO团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
