# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
12月伊始,可灵AI接连放出大招。
全球首个统一的多模态视频及图片创作工具“可灵O1”、具备“音画同出”能力的可灵2.6模型、可灵数字人2.0功能……
5天内5次“上新”,直接让生成式AI领域的竞争“卷”出新高度。
可灵2.0发布的时候,就创新性地提出过一个全新交互理念——Multimodal Visual Language(MVL),让用户能够结合图像参考、视频片段等多模态信息,将脑海中包含身份、外观、风格、场景、动作、表情、运镜在内的多维度复杂创意,直接高效地传达给AI。
基于MVL理念,在最新的一次迭代中,可灵O1将所有生成和编辑任务融合于一个全能引擎之中,为用户搭建全新的多模态创作流,实现从灵感到成品的一站式闭环。
就像a16z投资合伙人Justine Moore在产品发布后第一时间点评的那样:
我们终于迎来了视频界的Nano Banana。
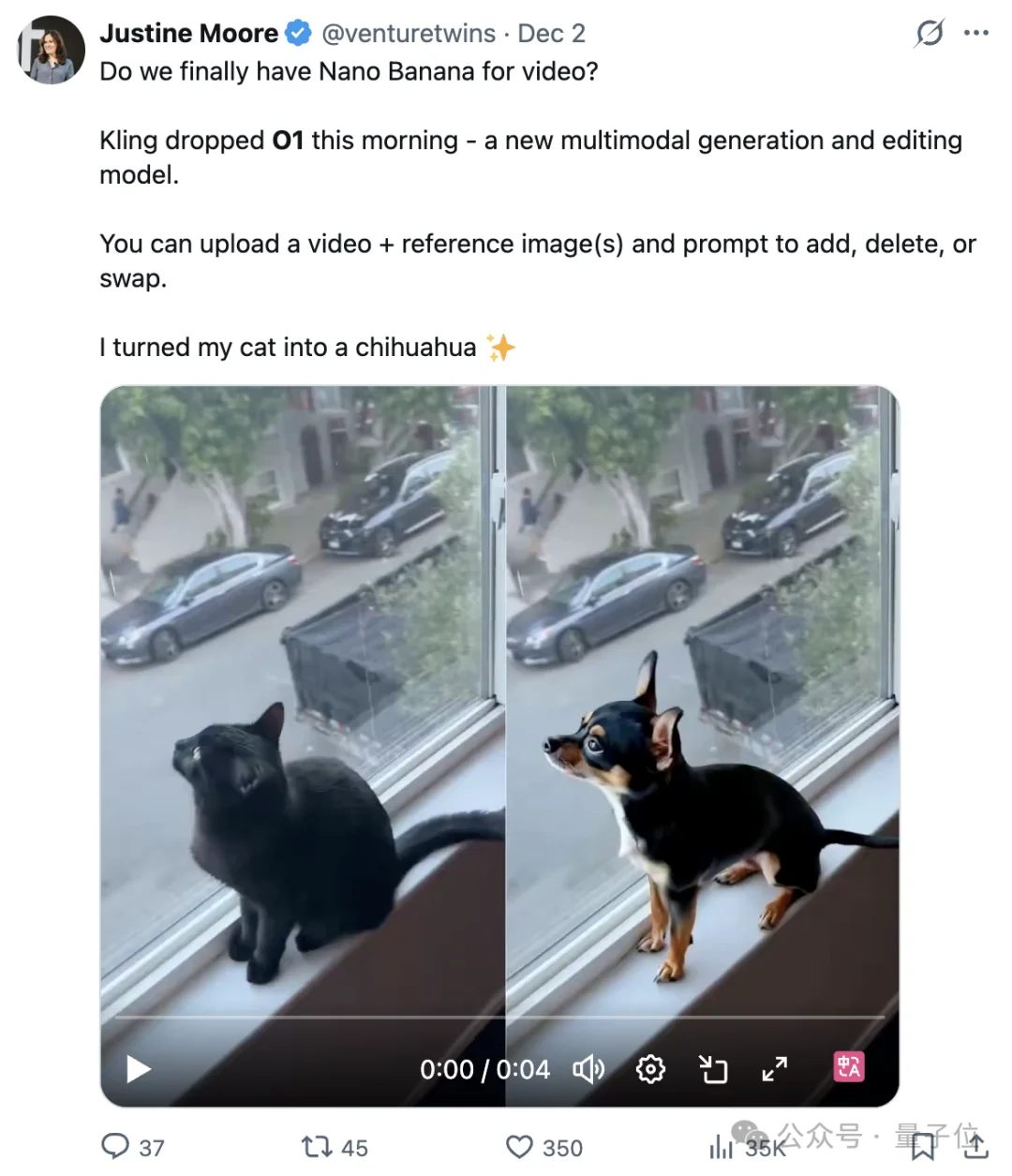
以可灵视频O1模型为例,它打破了传统单一视频生成任务的模型边界,将参考生视频、文生视频、首尾帧生视频、视频内容增删、视频修改变换、风格重绘、镜头延展等多种任务,融合于同一个全能引擎之中,使得用户无需在多个模型及工具间跳转,即可一站式完成从生成到修改的全部创作流程。
就像下面这个视频里你能看到的,无论是创作者们“头疼”已久的主体一致性难题,还是视频画面的可控性问题,都在这次模型迭代里找到了相对完美的解决方案。
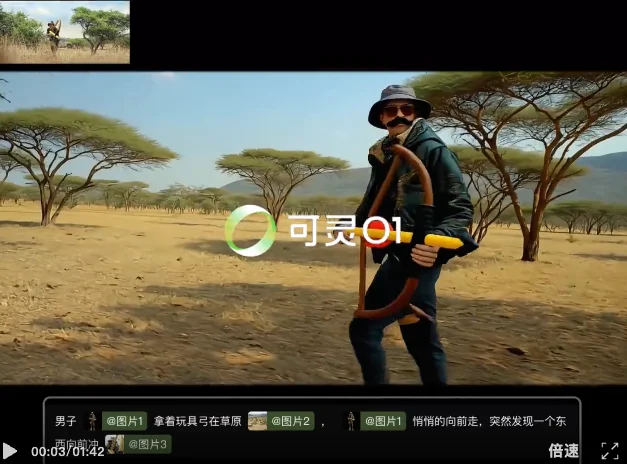
在图片生成这件事上,可灵AI也创新性地完成了迭代。
最新上线的图像O1模型,可以实现从基础图像生成到高阶细节编辑全链路无缝衔接,对用户来说,既可通过纯文本生成图像,也可上传最多10张参考图进行融合再创作。
众所周知,可灵拥有一大批忠实的“发烧友”。他们既是产品的深度使用者,也能从功能层面提出自己的见解。
O1发布之后,就有不少网友排队“许愿”产品功能,排名靠前的,几乎都在关心可灵什么时候会推出伴随视频画面的语音及音效直出功能。
答案很快就揭晓了。
12月3日夜晚,可灵AI接着“放大招”,正式推出2.6模型。
这次更新中,可灵AI上线里程碑式的“音画同出”能力,彻底改变了传统AI视频生成模型“先无声画面、后人工配音”的工作流程。
它能够在单次生成中,输出包含自然语言、动作音效以及环境氛围音的完整视频,重构了AI视频创作工作流,极大提升创作效率。
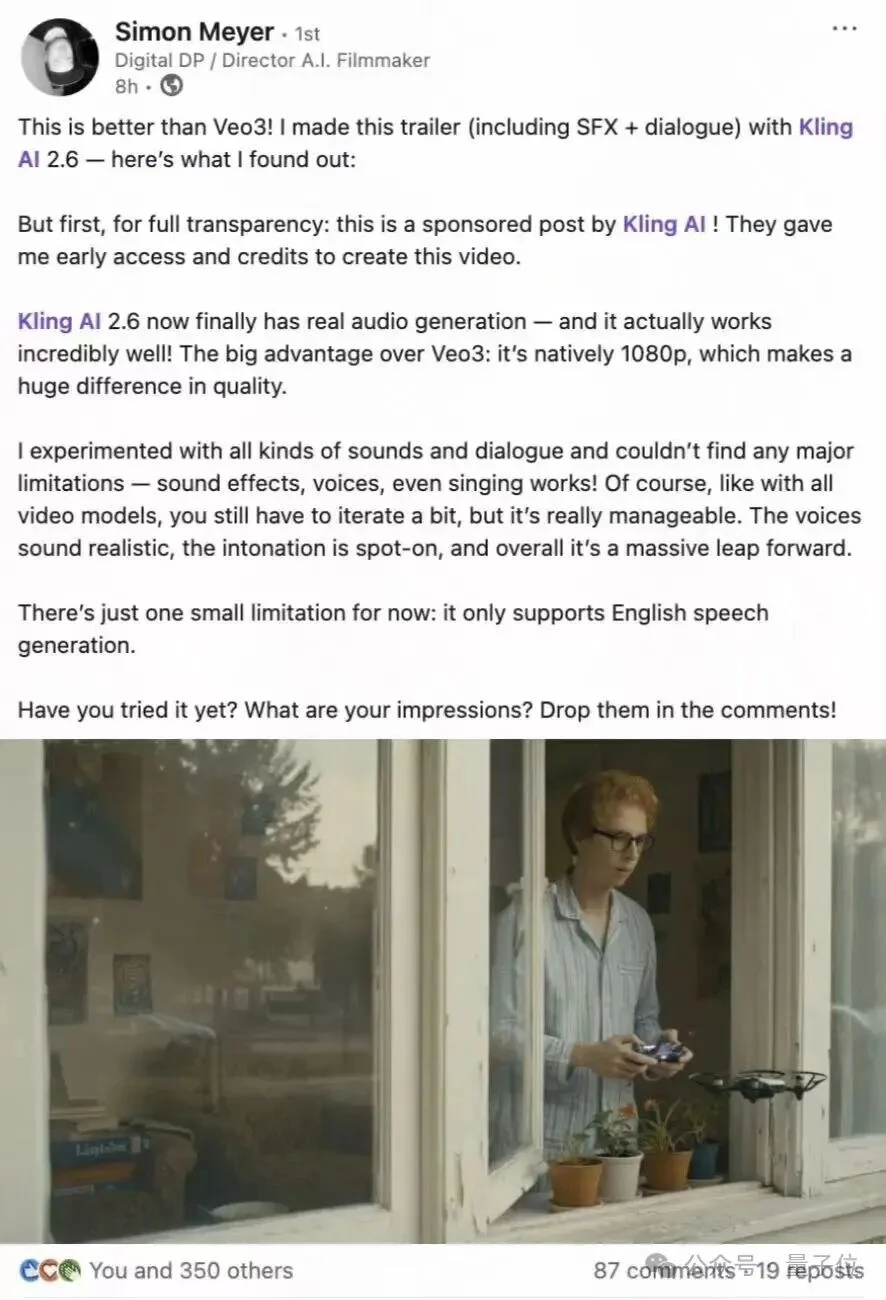
可灵AI海外超级创作者、AI电影导演Simon Meyer制作的这支宣传片,生动诠释了这次可灵2.6的能力创新之处:

对于创作者来说,输入文本或是输入图片结合提示词文本,均可直接生成带有语音、音效及环境音的视频。
语音部分,可灵目前支持生成中文以及英文,生成视频长度最长支持10秒(据说,更多样的语言体系以及固定声线等功能正在研发中)。
通过对物理世界声音与动态画面的深度语义对齐,可灵2.6模型在音画协同、音频质量和语义理解上表现亮眼。
对“音画同出”能力感兴趣的朋友,可以赶快试试,说不定你会和Simon Meyer一样产生强烈共鸣。
除了全新推出的可灵O1及2.6模型这两大重磅更新,可灵还在上周相继推出了数字人2.0、可灵O1主体库&对比模板等功能,从AI内容生成的实际流程出发,带来更加便捷的操作体验。
5天内5次“上新”,功能层面的精进背后,是可灵对于生成式AI技术的极致追求。
比如12月1日推出的视频O1模型,就打破了视频模型在生成、编辑与理解上的功能割裂,构建了全新的生成式底座。
融合多模态理解的Multimodal Transformer和多模态长上下文(Multimodal Long Context),实现了多任务的深度融合与统一。
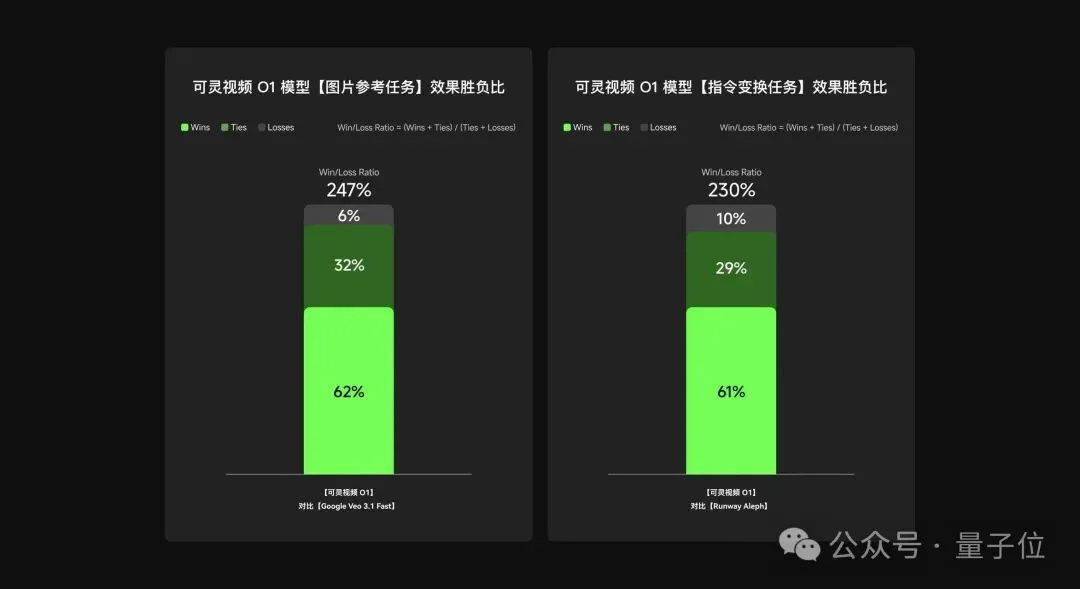
根据可灵AI团队的内部测评,在“图片参考”任务上,可灵AI对Google Veo 3.1的整体效果胜负比为247%;在“指令变换”任务上,与Runway Aleph对比的整体效果胜负比达到230%。
尤为难得的是,作为国产视频生成大模型领域的代表,从2024年6月正式推出以来,可灵AI的每一次迭代几乎都能让业界迎来一次“集体兴奋”。
从早期人们津津乐道的吃面条的案例,到特斯拉创始人马斯克的点赞,再到可灵AI这一波“批量上新”操作,视觉生成技术逐步走向成熟的过程里,可灵AI无疑是那个常常唤起共鸣的关键角色。
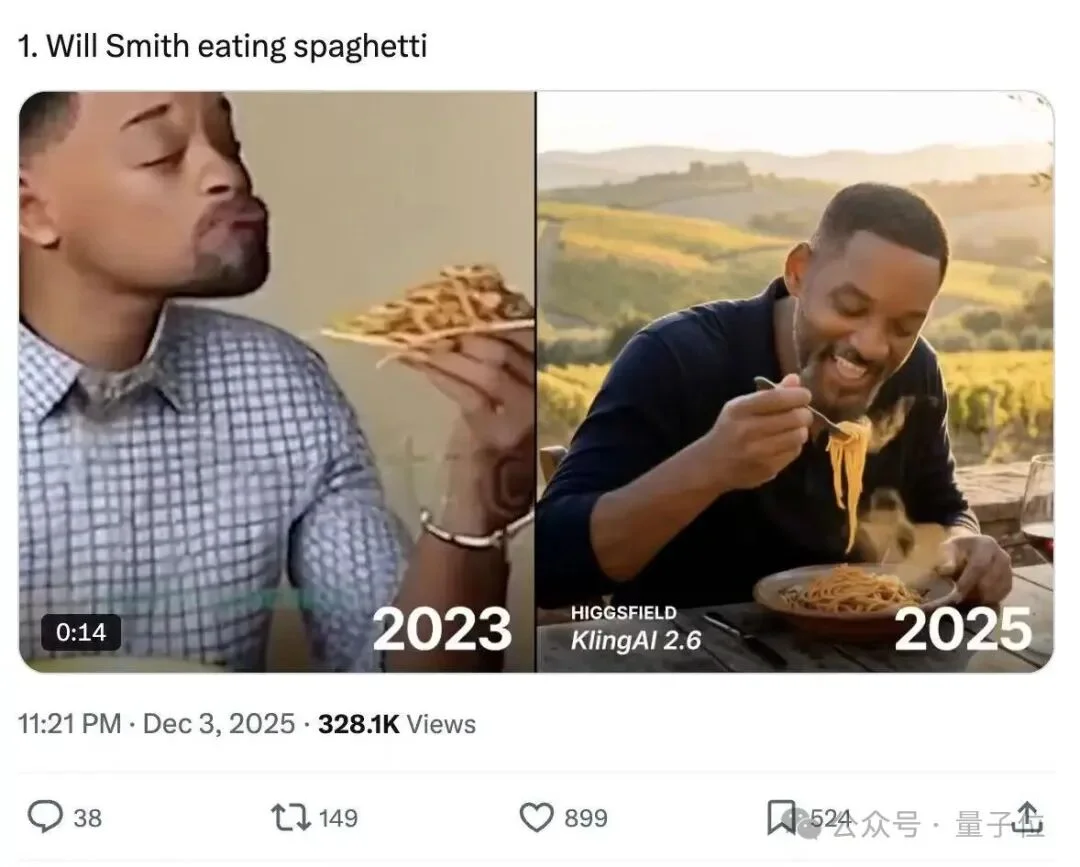
△X网友Min Choi发布的文章,对比了不同技术能力之下“威尔·史密斯吃意大利面”的经典场景。后者使用可灵2.6模型生成,这一次,除了相当出色的视频画面呈现,吃面条时的环境音也能直出了。
在持续引发讨论的同时,能否推进技术的广泛应用落地,也是生成式AI平台不得不面对的问题。
数据显示,可灵AI目前覆盖的企业用户数超过2万家,涵盖影视制作、广告、创意设计、自媒体、游戏、电商等等诸多领域。
多元的行业客户构成,意味着可灵AI必须持续打破技术应用的上限。
就像这次升级的可灵2.6模型,可以支持包括说话、对话、旁白、唱歌、Rap、环境音效、混合音效等多种声音的单独或混合生成,能够广泛地应用于各行各业的实际创作场景中,极大提升创作效率;
再比如数字人2.0功能的迭代,对于创作者而言,只需要上传角色图,添加配音内容并描述角色表现,就可以得到表现力生动的“自定义数字人”,更令人兴奋的是,视频内容最长可达5分钟。
快手高级副总裁、可灵AI事业部负责人兼社区科学线负责人盖坤曾在不同场合表示:
我们的初心,是让每个人都能用AI讲出好的故事,我们也真切地希望这一天更快到来。
在可灵AI年末的这一系列更新中,我们感受到,这一天更近了。
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
