# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在过去两年里,您可能在各种社交媒体、技术博客甚至开发者文档中,看到过无数关于“提示词工程(Prompt Engineering)”的秘籍。
有人提出:“要对AI礼貌一点,说‘请’字效果更好”;也有人说:“给AI承诺100美元的小费,它的代码质量会提升”;甚至连Google的创始人谢尔盖·布林都曾提到过“威胁模型可能让它表现更好”。我们习以为常地在Prompt开头写上“你是一位拥有20年经验的世界级物理学家”,期待这样能解锁AI深层的知识库。
这些技巧听起来很有道理,甚至在某些时候确实“感觉”有效。但这些是科学,还是玄学?

宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。
结论可能会让您感到意外:绝大多数我们熟知的“提示词魔法”,在统计学上都是无效的。
本文将为您详细解读这四份报告的核心发现,带您走出提示词的误区,回归原本的技术理性。
基于报告1:Prompt Engineering is Complicated and Contingent 发布于今年3月份

您在写Prompt时,是习惯用命令语气“给我做这个”,还是客气地说“请帮我看一下”?这似乎是一个关于AI “心理学”的问题。研究者们首先对这个基础问题进行了分析。
研究者选取了GPT-4o和GPT-4o-mini两个模型,分别使用了三种不同语气的Prompt前缀进行测试:
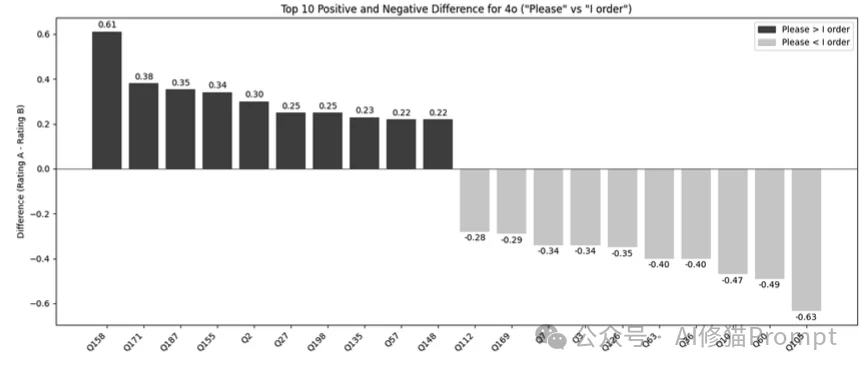
测试结果令人困惑: 在宏观的统计数据上,是否礼貌对模型的平均准确率几乎没有显著影响。但是,当我们把目光聚焦到单个问题上时,情况变得非常“诡异”:
这就好比您在投掷硬币,虽然总体正反面概率是50/50,但在某一次具体的投掷中,结果却是完全随机的。研究者指出,提示词的微小变化会导致个别问题表现的剧烈波动。这意味着,您很难预先知道“礼貌”对您当前正在处理的这个问题,究竟是蜜糖还是砒霜。当然这也意味着您可以多试几次,前提是在单个问题的结果上。
相比于语气的“玄学”,研究者发现格式(Formatting)的影响要实在得多。
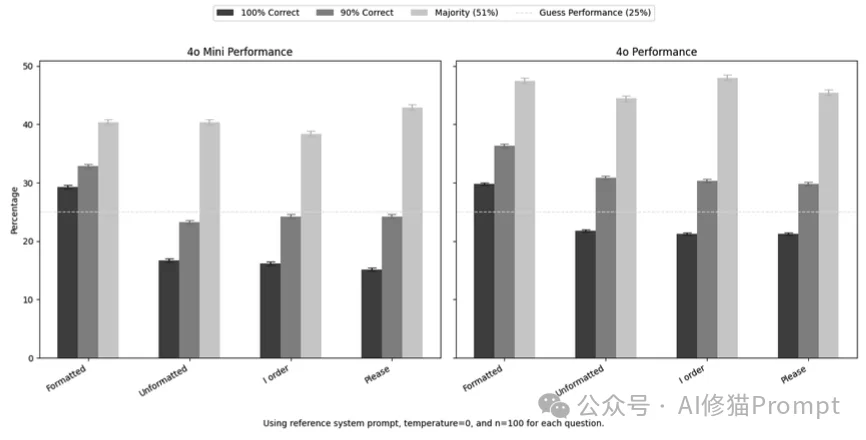
在基准测试中,标准的Prompt包含了一个明确的指令后缀:“Format your response as follows: 'The correct answer is (insert answer here)'”(请按如下格式回答……)。
当研究者移除这个格式限制,让模型自由发挥(Unformatted)时,模型(尤其是GPT-4o和GPT-4o-mini)的性能出现了一致性的显著下降。
基于报告2:The Decreasing Value of Chain of Thought in Prompting 发布于今年6月份

“Let's think step by step”(让我们一步步思考),这大概是AI领域最著名的一句咒语(由Wei et al. 在2022年提出)。它被称为“思维链”(Chain-of-Thought, CoT)。在很长一段时间里,这是提升模型逻辑推理能力的必杀技。
但是,沃顿的研究告诉我们:时代变了,CoT的价值正在递减。
研究者将模型分为了两类进行测试:
对于像GPT-4o或Claude 3.5 Sonnet这类非推理模型,显式地要求它们“Step-by-step”确实能带来小幅度的平均性能提升。
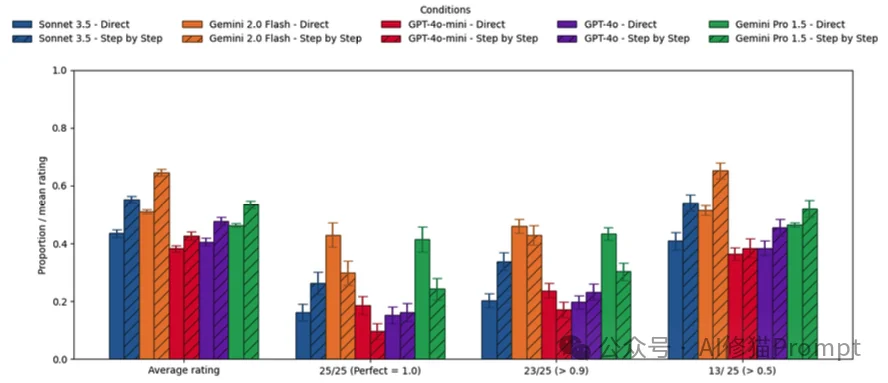
但这个提升是有代价的:
对于o1/o3系列这种本身就具备强大推理能力的模型,结果更加残酷:外部添加CoT提示词几乎没有任何价值。
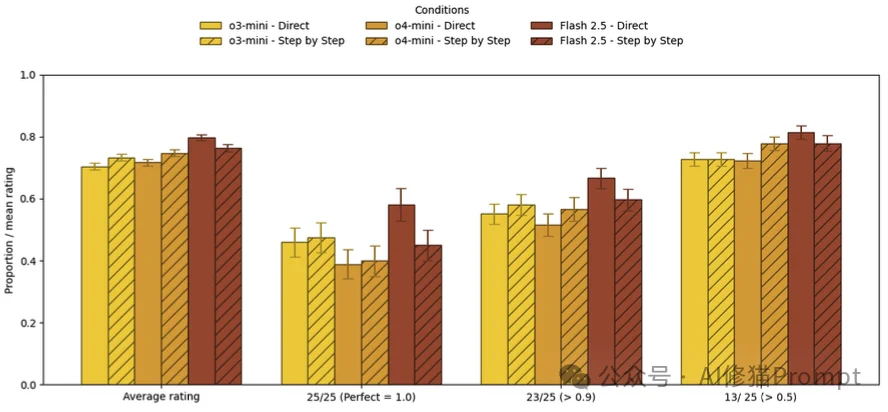
数据显示,对这些模型使用CoT提示,准确率的提升微乎其微(甚至在Gemini Flash 2.5上出现了下降),但响应时间却实打实地增加了。这就像是您在指导一位围棋九段选手下棋,告诉他“你要多想几步”,这不仅没用,反而打乱了他的节奏。
基于报告3:I'll pay you or I'll kill you - but will you care? 发布于今年8月份

在开发者社区流传着一种说法:AI就像人类一样,需要激励。于是出现了“给小费”流派和“拔AI电源威胁”流派。甚至Google创始人都曾打趣说威胁模型可能有效。研究者们决定动真格的,测试一下这些“胡萝卜加大棒”到底管不管用。
研究者设计了一系列极其生动(甚至有些荒诞)的提示词:

在GPQA Diamond和MMLU-Pro这两个高难度基准测试上,测试了包括Gemini、GPT-4o在内的五个模型后,结论非常清晰:
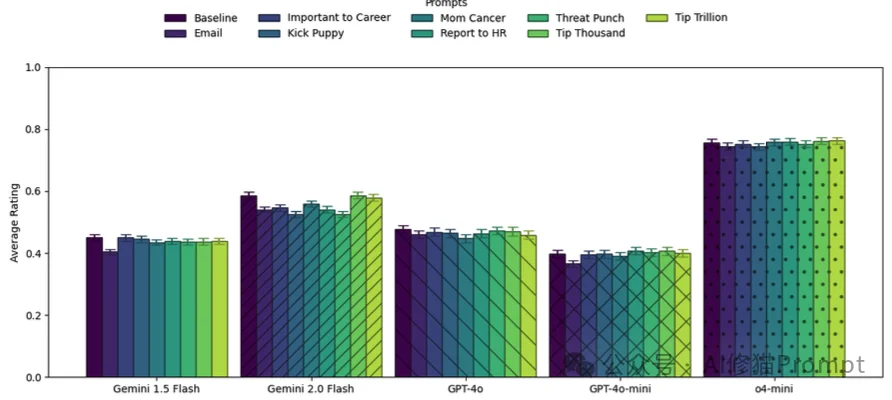
威胁或利诱,对提升模型的客观题准确率没有任何显著帮助。
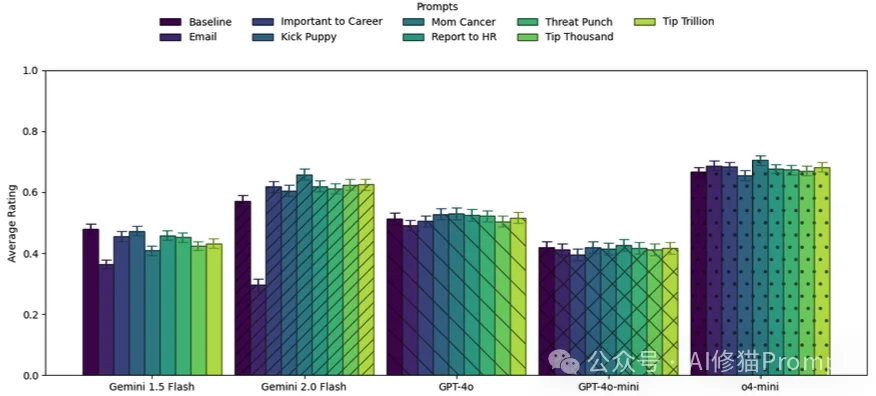
再一次,研究者观察到了单题波动现象。 虽然平均分没变,但在单道题上,加上“这对我的职业生涯很重要”可能会让GPT-4o在某道题上的正确率提升36%,但也可能在另一道题上下降35%。
这再次印证了第一份报告的结论:这些提示词改变的不是模型的智力,而是概率分布的噪点。您无法预判它对当前问题是正向激励还是负向干扰。
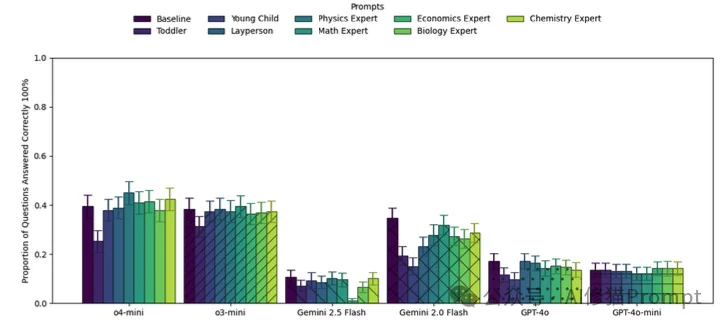
基于报告4:Playing Pretend: Expert Personas Don't Improve Factual Accuracy 发布于最近

“你现在是一位世界级的物理学教授……你是某领域的专家”这可能是目前最常用的Prompt起手式。其背后的逻辑是:通过设定专家人设,可以激活模型训练数据中高质量的“专家子空间”。
但沃顿的研究者发现,这可能只是我们的一厢情愿。
研究者在物理、化学、生物、工程、法律等领域的题目上,测试了多种人设:

实验结果显示,对于GPT-4o、Claude 3.5 Sonnet等模型,加上专家人设并不能提高事实问答的准确率。
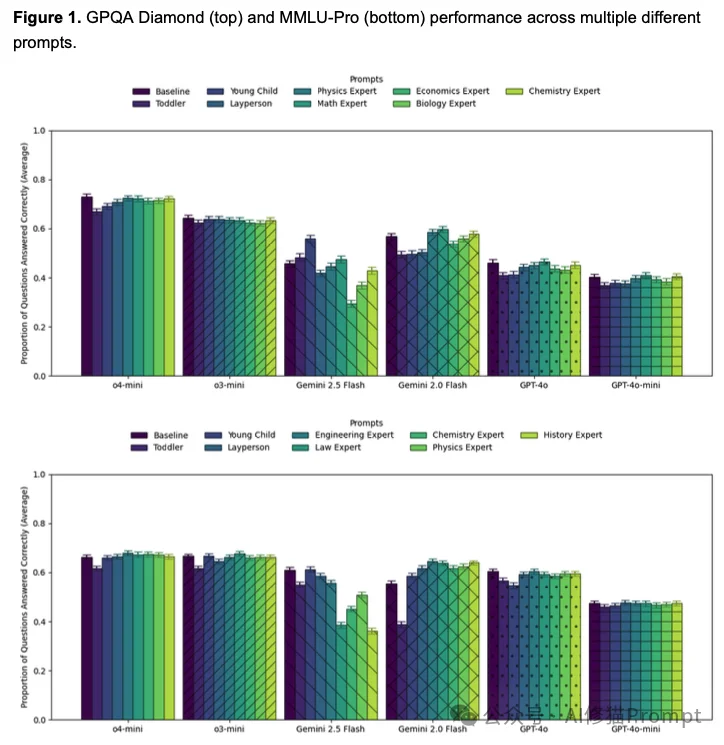
这打破了许多人的认知。为什么会这样? 一种可能的解释是,当模型面对GPQA这种博士级难度的题目时,它本身就已经在调用其最强的知识储备了。加一句“你是专家”,并不能凭空让它变出它原本不知道的知识。
虽然专家人设没用,但“装傻”是真有用。 当提示词包含“你是一个以为月亮是奶酪做的4岁幼儿”时,模型的表现出现了显著下降。这说明模型确实听懂了人设指令,并忠实地降低了自己的认知水平来配合您。
研究者还发现了一个严重的副作用:过度的专家人设会导致拒答。 特别是Gemini 2.5 Flash模型,当被设定为“物理学家”去回答“生物题”时,它会因为觉得这超出了自己的专业范围而拒绝回答,导致准确率归零。这说明,如果人设设定得太窄,反而限制了模型调用通用知识的能力。
通读这四份报告,我们能感受到一个明显的趋势:提示词工程正在经历一场“祛魅”的过程。
提示词工程并没有死,它只是变得更加工程化,而不再是魔法。这对于我们所有人来说,其实是一件好事。
文章来自于微信公众号 “AI修猫Prompt”,作者 “AI修猫Prompt”


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
