# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
昨天,苹果一篇新论文在 arXiv 上公开然后又匆匆撤稿。原因不明。
不过观看其提交历史,可以看到该论文在 12 月 6 日(UTC)就已被提交到 arXiv,到 11 号已经过去了 5 天,公开上线之后却又被光速撤稿,这不由得地让人好奇究竟发生了什么。

不过好在该论文有一个 v1 版本已经被互联网记录,所以我们也能打开这篇论文一探究竟。
论文中,苹果揭示了他们开发的一个基于 TPU 的可扩展 RL 框架 RLAX。
是的,你没有看错,不是 GPU,也不是苹果自家的 M 系列芯片,而是谷歌的 TPU!还不止如此,这篇论文的研究中还用到了亚马逊的云和中国的 Qwen 模型。

总之,这篇论文的贡献还真不少。
不过,在具体介绍这篇论文的研究成果之前,我们有必要先关注一下其作者名单。

RLAX 论文共有四名核心作者:Runlong Zhou、Lefan Zhang、Shang-Chen Wu 和 Kelvin Zou。
通讯作者则是 Kelvin Zou 和 Cheng Leong。其中 Kelvin Zou 曾在苹果担任 Principal Engineer,现已经入职 Meta,成为了一位 AI 研究科学家。而 Cheng Leong 则是已在苹果工作超过 13 年的老将,现任苹果 AI Infra(人工智能基础设施)主管。

截图自 LinkedIn
此外,我们还在作者名单中看到了庞若鸣的名字。
这位已经加入 Meta 的前苹果 AI 负责人与其他六位作者的名字一起也出现了论文第一页的最下方,并被描述为「已离开苹果公司。他们在受雇于苹果公司期间为这项工作做出了贡献。」而且他们基本都是前几个月才刚刚离职。
简单搜索一下这六位作者的履历,可以看到:
回到技术本身。强化学习(RL)对现代推理语言模型的重要性已无需多言,几乎所有的顶尖模型都是基于 RL 的推理模型,包括 OpenAI o3、Claude 4、Grok 4、Gemini 2.5、DeepSeek R1 以及 Qwen 3。
苹果开发的 RLAX 是一个专为在大规模分布式 TPU 集群上高效执行最先进 RL 算法而设计的强化学习框架。

极致解耦与抢占式调度
RLAX 采用了参数-服务器(Parameter-Server)架构。主训练器(Master Trainer)会定期将更新后的模型权重推送到参数服务器。与此同时,一组推理工作器(Inference Workers)会拉取最新权重,并生成新的采样数据(Rollouts)。
该团队引入了一套系统级技术,将训练器、推理工作器和验证器(Verifiers)在逻辑上进行了分离。这种逻辑分离使得 RLAX 能够灵活且独立地为各个组件分配计算资源。
最重要的是,RLAX 完全支持抢占式调度。这意味着当有更高优先级的任务(如在线推理负载)需要时,系统可以立即回收 TPU 资源,而不会导致训练崩溃。
灵活的策略支持
RLAX 致力于解决大规模 LLM 后训练 RL 过程中的关键挑战,特别是如何高效处理 On-policy(在线策略)和 Off-policy(离线策略)RL。
为此,RLAX 提供了可编程的配置选项。用户可以强制执行「陈旧度界限」(Staleness Bounds),指定推理工作器拉取新权重的频率,以及训练器所能容忍的最大 Rollout 陈旧度。这使得用户可以在 On-policy 和 Off-policy RL 之间灵活选择。
Oubliette:把代码扔进地牢
在验证器(Verifiers)的设计上,苹果工程师展现了一种特有的黑色幽默。
验证器需要针对训练语料库中每种编程语言进行代码执行验证。为了高效且确定性地验证 Python 程序,他们将标准 Python 依赖项容器化。
为了跑通大规模代码测试,他们调用了亚马逊的 AWS Lambda 服务,并将其命名为 「Oubliette」。
「Oubliette」一词源自法语,原意是指城堡中只有一个出口(通常是天花板上的活板门)的地下地牢,是专门用来「遗忘」囚犯的地方。
苹果工程师用这个词来隐喻他们的无状态验证环境:代码和测试数据被扔进这个基于 AWS Lambda 的「地牢」里,跑完测试、吐出结果后,整个环境即刻销毁,就像这段代码从未存在过一样。
有趣的是,在实验阶段,我们看到了一个「缝合怪」的诞生:
没错,苹果的工程师,在美国用着谷歌的 TPU,调着亚马逊的 Serverless 服务,去优化一个中国开源的 Qwen 模型。
结果倒是非常亮眼。RLAX 仅用 12 小时 48 分钟,在 1024 个 v5p TPU 上将 QwQ-32B 的 pass@8 准确率提高了 12.8%,同时在训练期间保持了对任务抢占的鲁棒性。
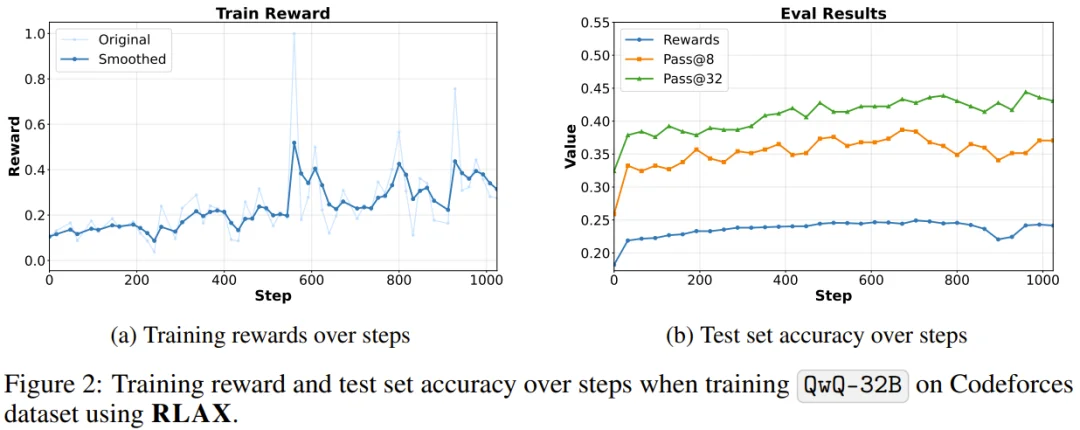
这种「美中技术大乱炖」的场景,在苹果以往封闭的生态中简直不可想象。这也侧面印证了两件事:第一,在 AI Infra 领域,实用主义正在压倒门户之见;第二,国产模型(尤其是 Qwen 和 DeepSeek)在代码推理领域的统治力,已经强到连苹果都忍不住要拿来当「磨刀石」。
在 RLAX 论文的第 4 页和第 9 页,苹果披露了一个足以让系统工程师脊背发凉的 Bug。
在强化学习中,On-policy(在线策略)训练有一个理论基石:Importance Sampling ratio(重要性采样比率)r (θ) 应该恒等于 1.0。因为行为策略和当前策略是完全一致的。
但在 TPU 训练实战中,苹果团队发现:1.0 竟然不等于 1.0。

这个问题的根源在于 bfloat16 浮点数格式的非结合律(Non-associative) 特性。简单来说,在计算机里 (a+b)+c 和 a+(b+c) 的结果可能存在微小的比特级差异。
这种计算顺序的微小差异,在 bfloat16 下被放大,导致推理端算出的概率和训练端算出的概率无法对齐,进而导致训练崩溃。
苹果的解决方案非常暴力且有效:他们在训练器中强制重算(Rematerialization),禁用了大部分激活值的保存,强行让训练端的计算图去「模仿」推理端的计算顺序。虽然牺牲了一点点速度,但消除了这个数值问题。
对于正在从事 LLM Post-training 的工程师来说,这个 Debug 过程极具参考价值。
虽然目前已被撤稿,但 RLAX 证明了苹果在 AI 基础设施上依然拥有世界顶级的工程能力。他们能驾驭最复杂的分布式系统,解决最底层的数值难题。
但随着许多重要人物分散到 Meta、OpenAI、Anthropic 和 xAI,这篇论文似乎也成为了苹果 AI 这一阶段的一个注脚。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


