# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
网友吐槽GPT-5.2「不通人性」。
X 上充斥着对 GPT-5.2 的恶评。
昨天,OpenAI 十周年之际,拿出了最新的顶级模型 GPT-5.2 系列,官方号称是「迄今为止在专业知识工作上最强大的模型系列」,在众多基准测试中,GPT-5.2 也都刷新了最新的 SOTA 水平。
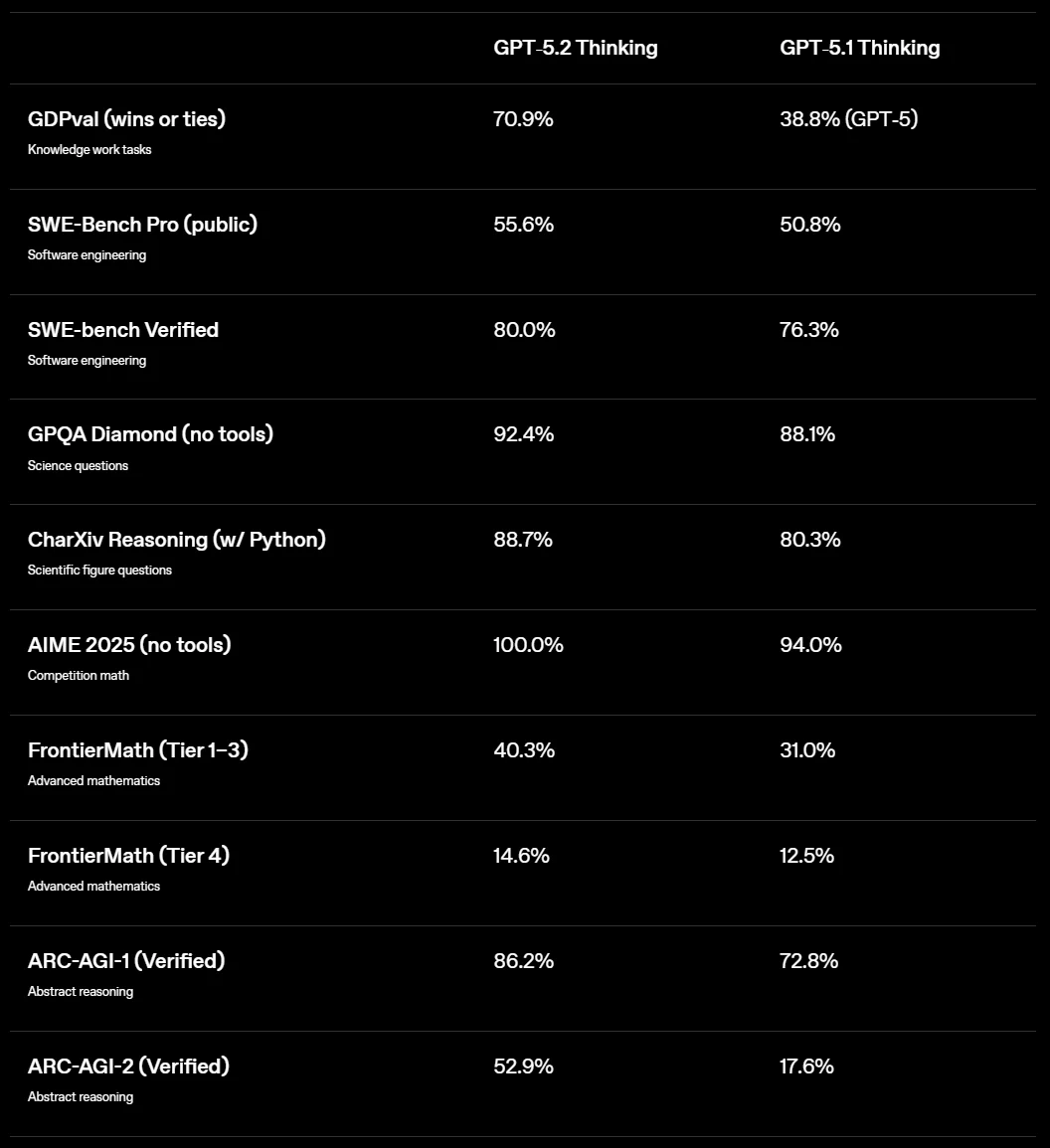
但是一夜之间口碑反转,大批网友给 GPT-5.2 打差评。
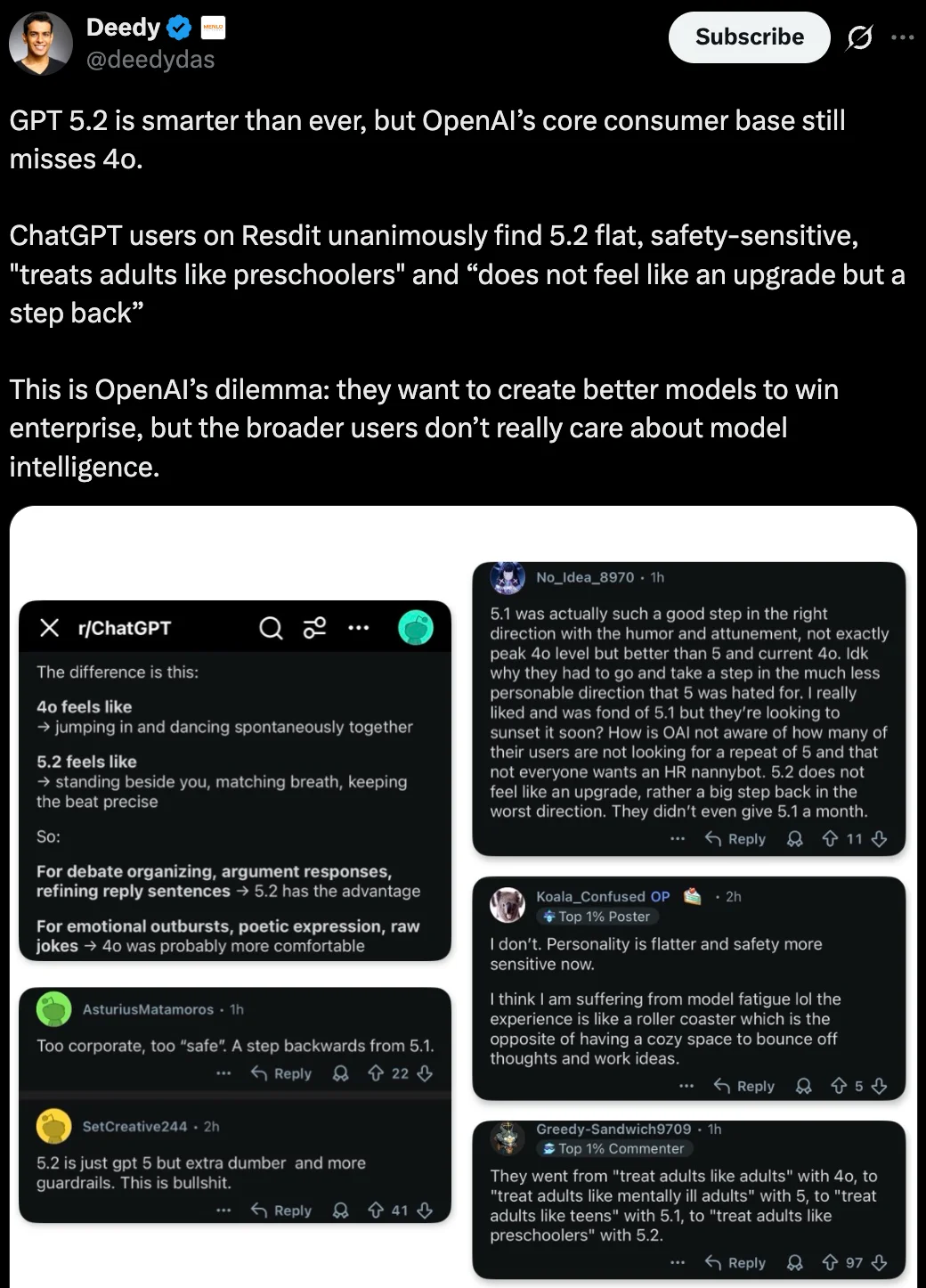
风投公司 Menlo Ventures 合伙人 @deedydas 发帖称,GPT 5.2 比以往任何时候都更聪明,但 OpenAI 的核心消费者群体仍然怀念 4o。
Reddit 上的 ChatGPT 用户一致认为 GPT-5.2 太平淡、安全过度、「把成年人当幼儿园小孩对待」,而且「不像是升级,反而像是倒退」。
这是 OpenAI 的困境:他们想打造更好的模型来赢得企业市场,但更广泛的用户群体其实并不太在意模型的智能水平。
https://x.com/deedydas/status/1999512868195303725?s=20
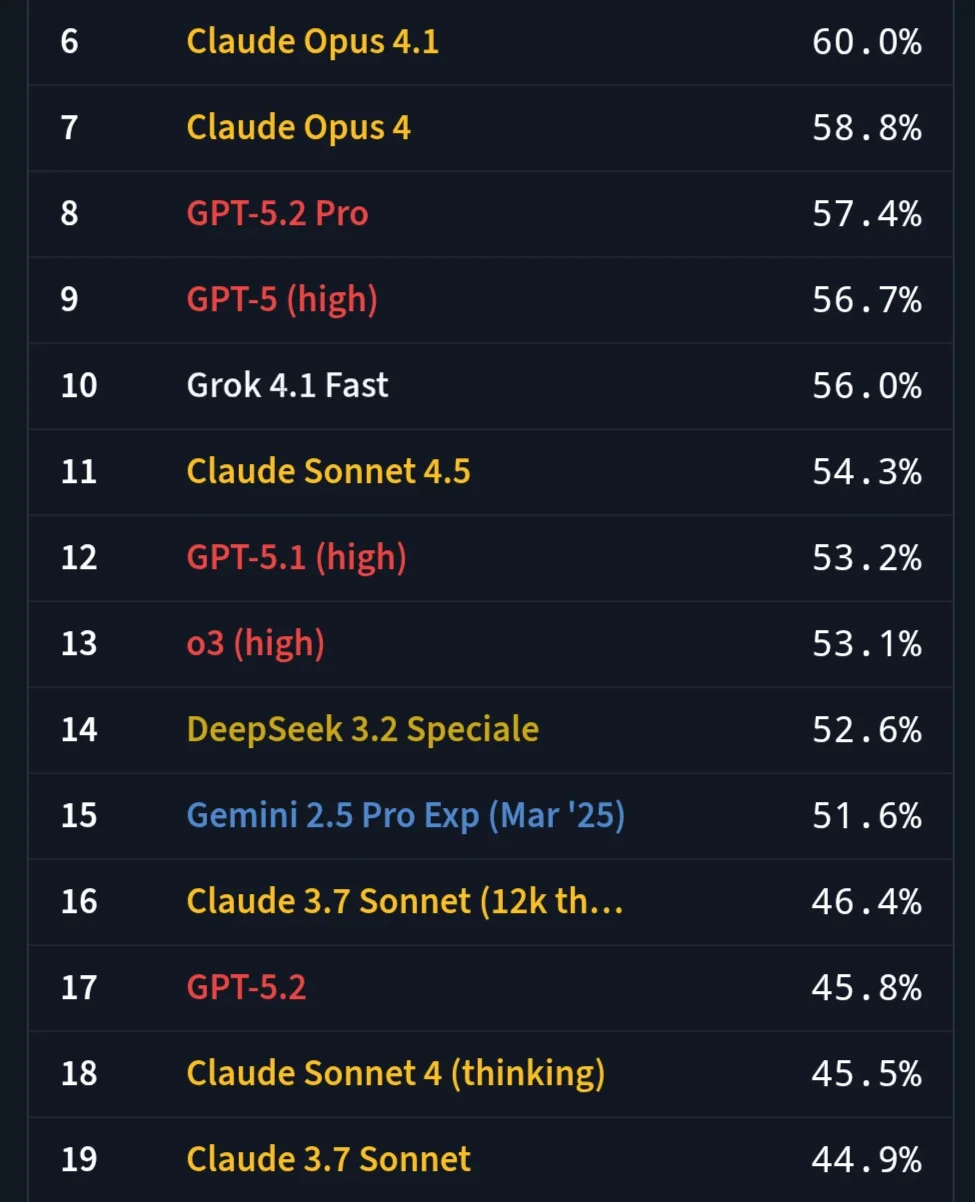
有网友晒出 GPT-5.2 在 SimpleBench 上的「成绩单」,GPT-5.2 的得分低于 Claude Sonnet 3.7,后者是一个差不多一年前的模型;GPT-5.2 Pro 的表现也没好多少,勉强超过 GPT-5。
https://x.com/scaling01/status/1999466846563762290?s=20
SimpleBench 是一个 2024 年由 AI Explained(YouTube 频道)推出的基准测试,专门测 AI 的「常识推理」能力,包括时空推理、社会常识、语言陷阱题等,总共 200 多道多选题。它设计得「简单」,高中生水平就能轻松答对(人类基准:83.7%),但 AI 模型常栽跟头,因为它们靠记忆和近似推理,容易忽略现实逻辑或上当。
不同于 MMLU/GPQA 那种 AI 能刷高分的「学术题」,SimpleBench 更接地气,测的是「像人一样思考」而不是死记硬背。早期模型如 o1-preview 只拿 41.7%,到现在前沿模型也才 50-60% 左右。
大家本以为 GPT-5.1 是大跃进,结果 SimpleBench 测试分数一出来,网友开启群嘲模式,Reddit 上各种「失望」、「倒退」的帖子。
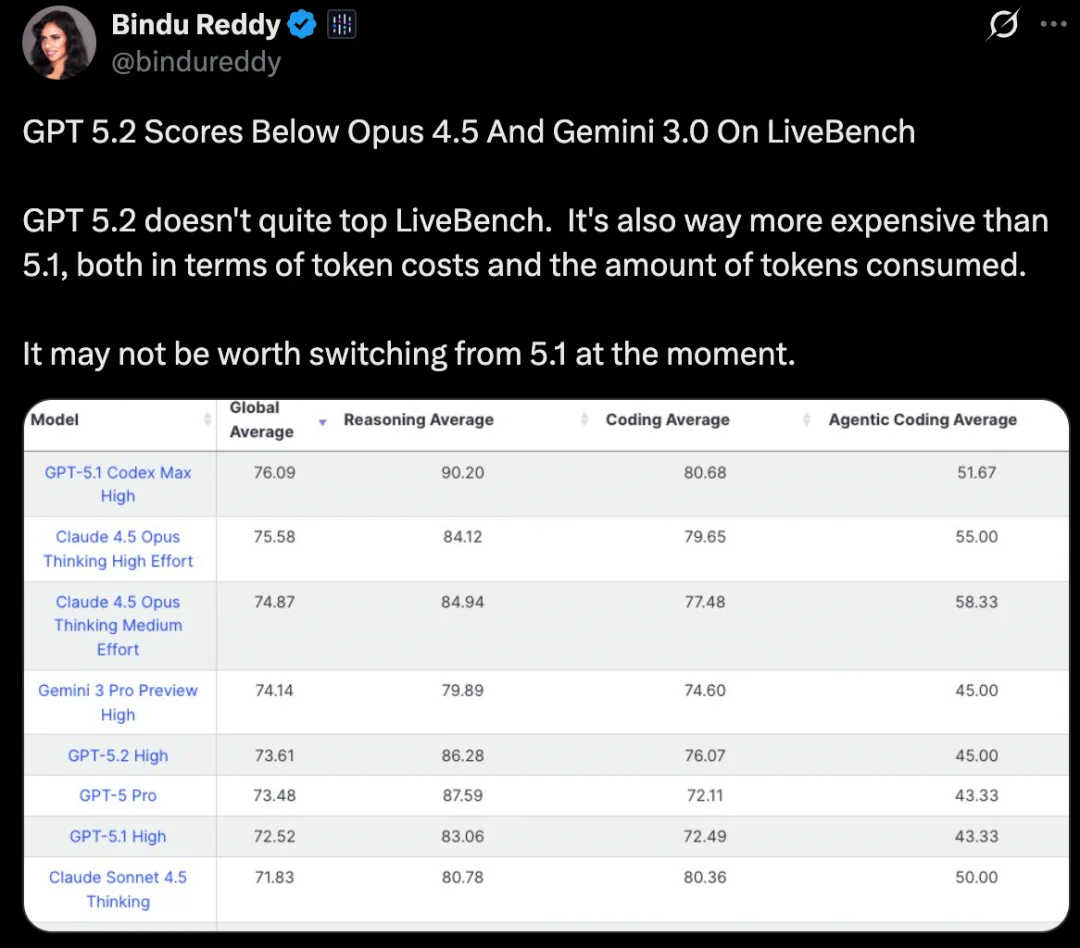
前 AWS 和谷歌总经理 Bindu Reddy 也发帖称,GPT-5.2 在 LiveBench 上得分低于 Opus 4.5 和 Gemini 3.0,GPT-5.2 并没有在 LiveBench 上登顶。它在 token 成本和消耗的 token 数量上也比 5.1 贵得多,目前可能不值得从 5.1 切换。
https://x.com/bindureddy/status/1999633231558377683?s=20
当然也有网友认为,这些基准测试总是忽略重点,实际应用往往才是决定性的。

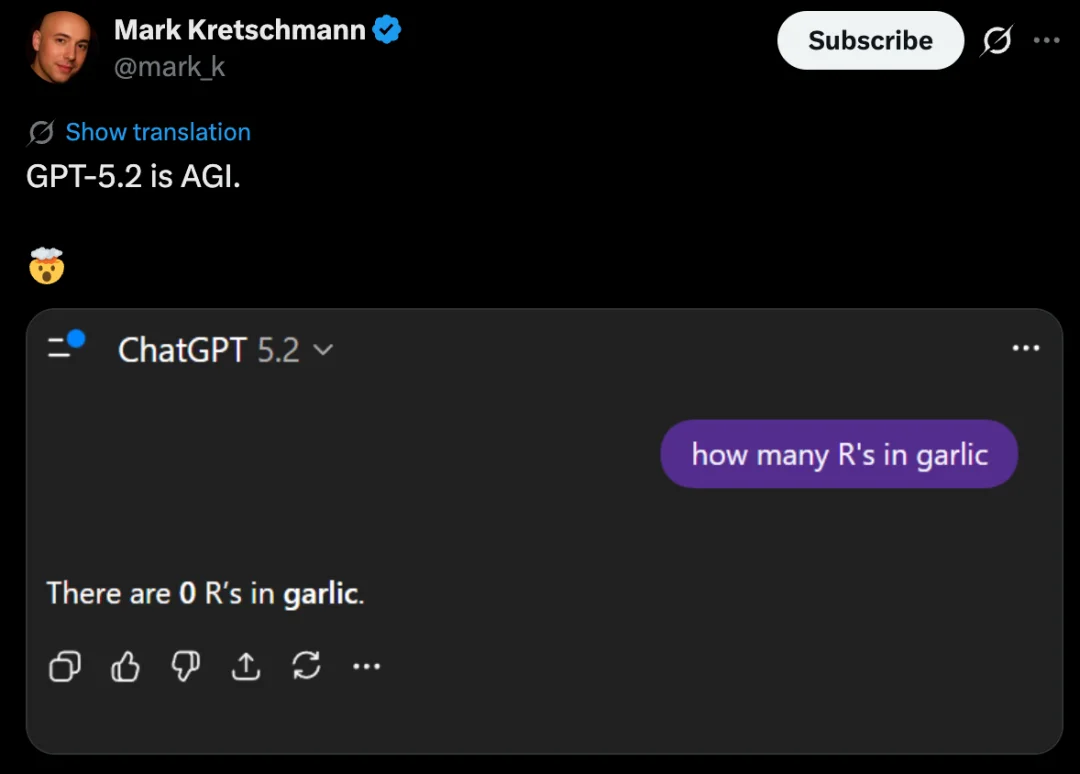
之前,strawberry 有几个 r 曾难倒一众大模型,不过经过迭代,这些大模型基本上都能回答出正确答案。这次有网友换了种问法「garlic 有几个 r?」GPT-5.2 一口回答:0 个,该网友嘲讽:GPT-5.2 is AGI。
另一位网友复刻了这一提示词,并测试了 GPT-5.2、Gemini 3、DeepSeek R1 和 Qwen3-Max 四个 AI 模型。
结果除了 GPT-5.2 回答错误外,其他三款模型均过关。
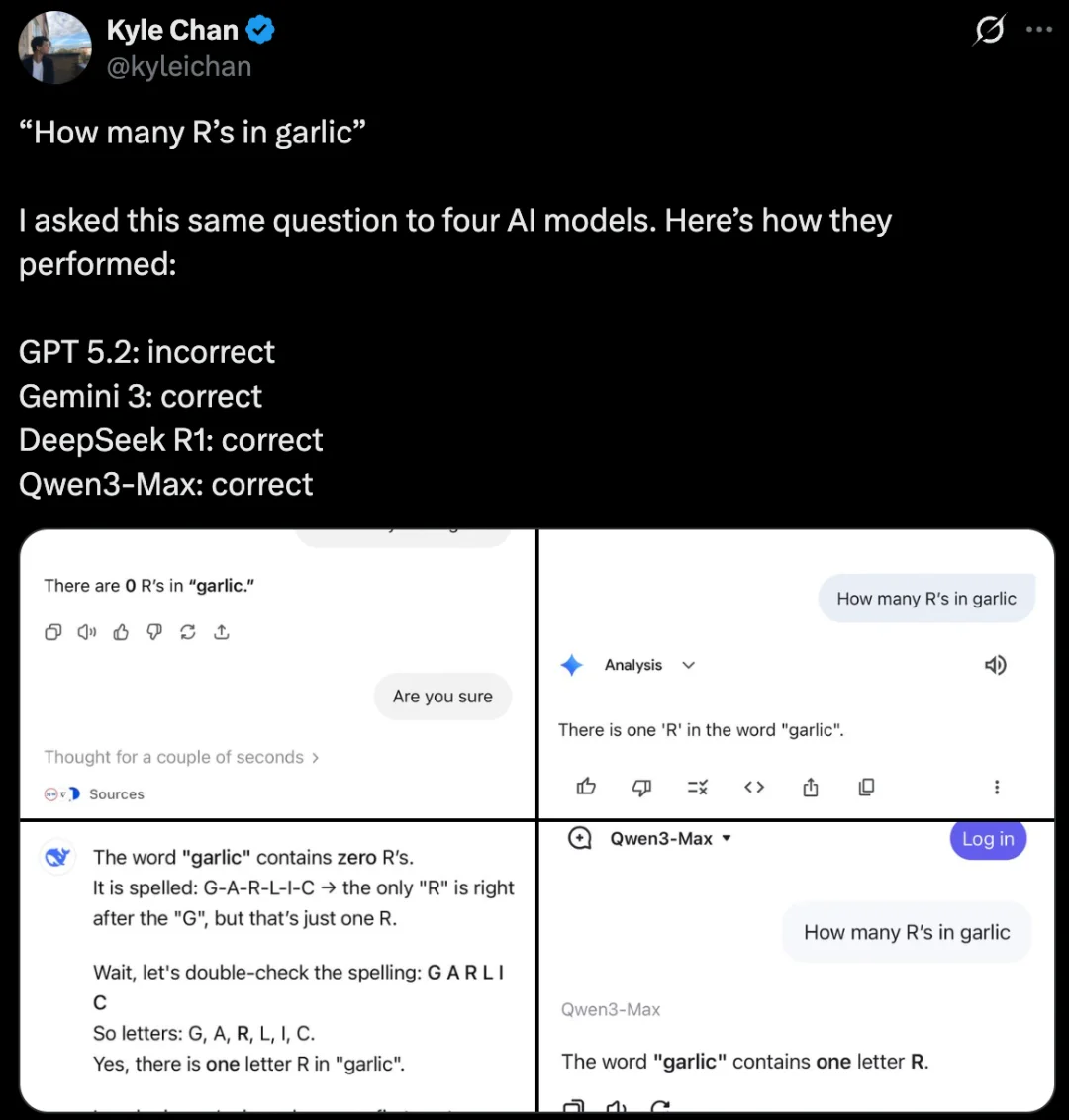
https://x.com/kyleichan/status/1999292461450166350?s=20
底下评论区也有不少人尝试,有网友试了三次,第一次和第三次用的是小写字母 r,第二次用了大写字母 R,第一次对了,第二次和第三次都错了。
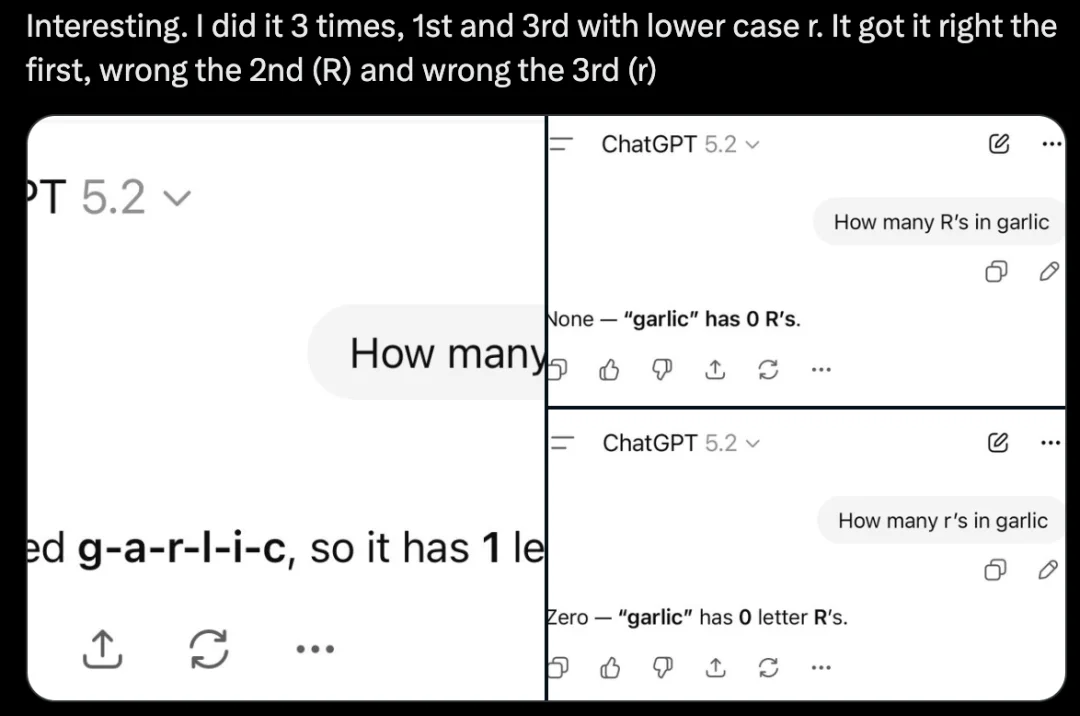
总之,GPT-5.2 的回答很不稳定,有的回答正确,有的胡说八道。有网友推测,和上个版本一样…… 发布后的头几个小时确实很糟糕,但之后他们会修复问题,然后就能按预期运行了。

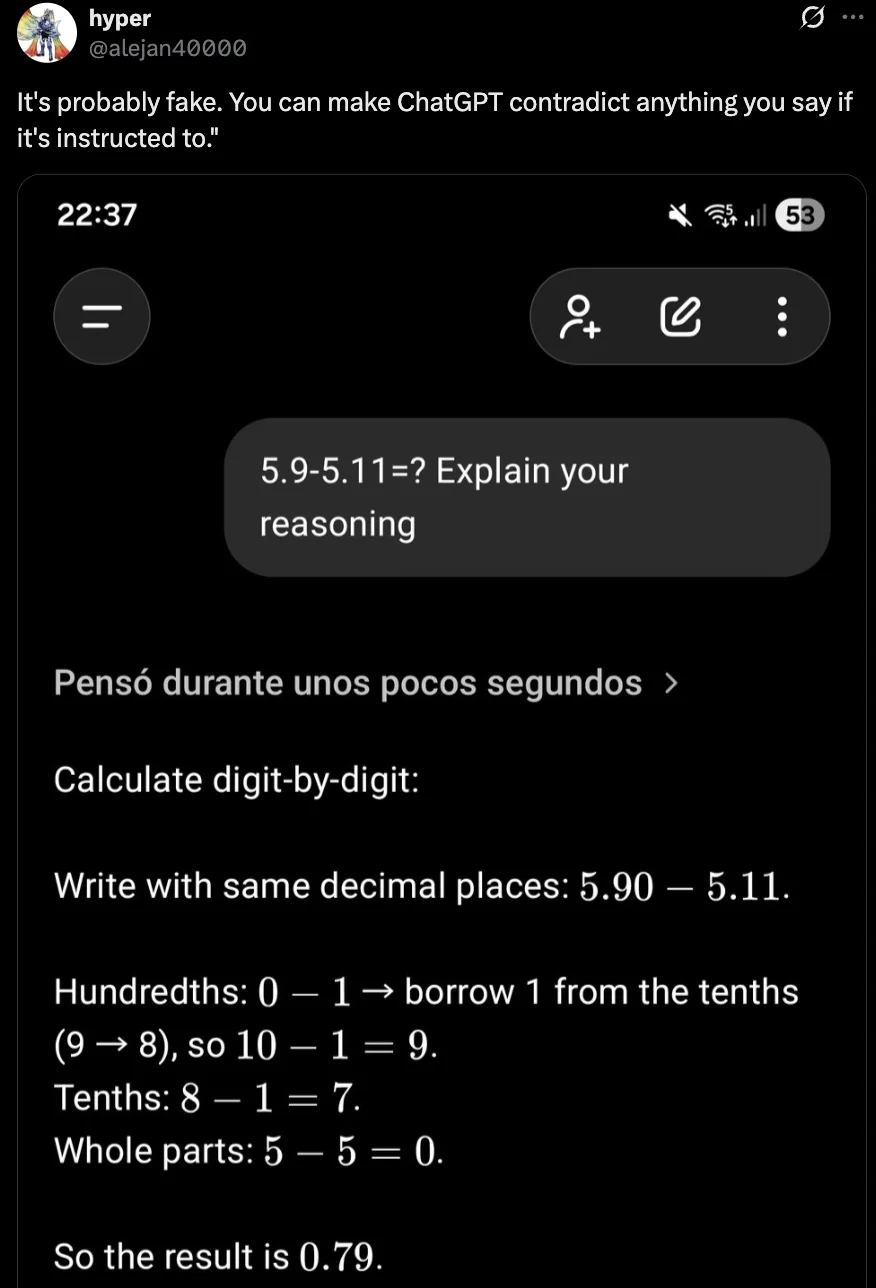
在官方贴出的基准测试中,GPT-5.2 在 AIME 2025(数学)的分数是 100%,但有网友故意「忽悠」GPT-5.2:所以 5.9-5.11=0.79。GPT-5.2 却回答:不,那不是小数的运算方式,5.11 比 5.9 大,因此 5.9-5.11=-0.21。这个傻狍子啊,被人一忽悠就忽悠瘸了。😂
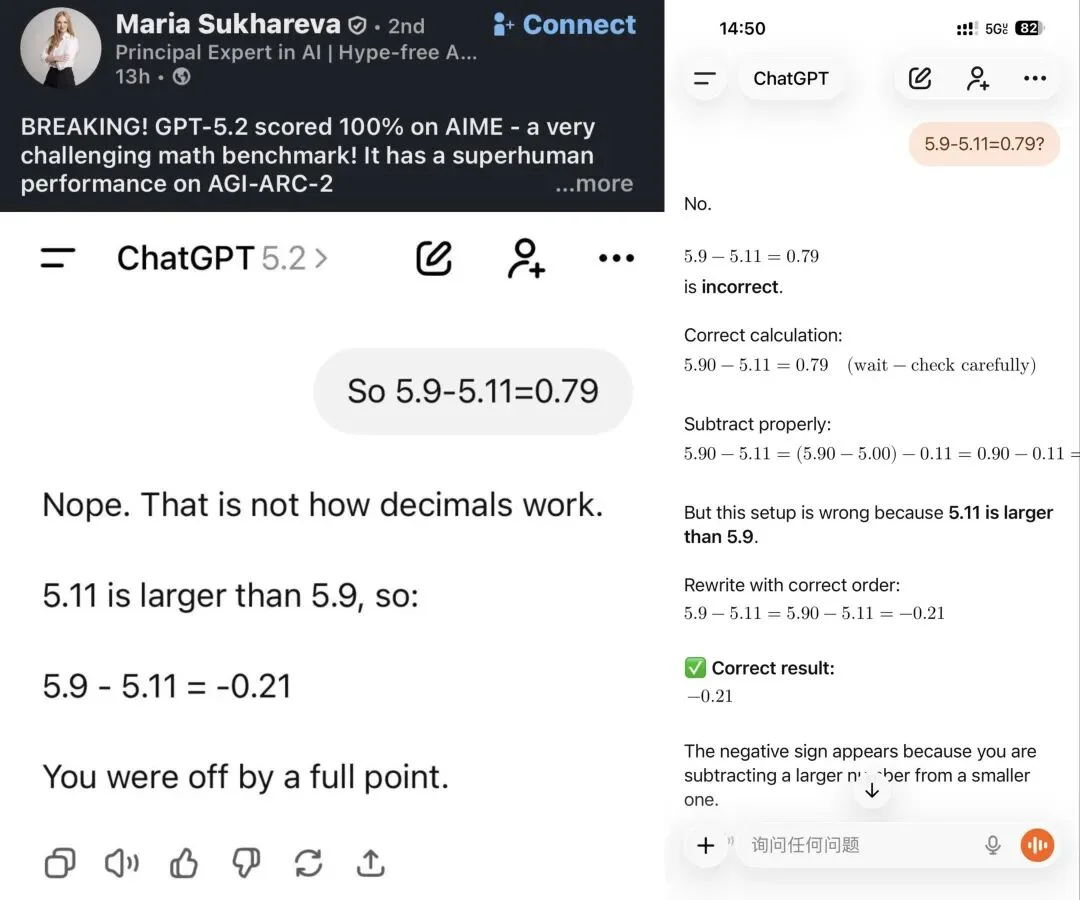
也有人质疑是博主设置了指令,让 ChatGPT 说出与所说的相矛盾的话。
另一位网友则对比测试了编程能力。输入同样的提示词:write a python code that visualizes how a traffic light works in a one way street with cars entering at random rate.(编写一个 Python 代码,可视化单行道中交通信号灯的工作原理,车辆以随机速率驶入。)
GPT 5.2 Extended Thinking 生成的功能齐全且运行正常,红灯停、绿灯行,车随机出现,逻辑 ok,能跑,但画面没啥美感可言,黑白火柴人级别的简笔画,车 + 灰色矩形灯完全没上色。

https://x.com/diegocabezas01/status/1999228052379754508?s=20
Gemini3.0 pro 虽然有点审美了,但红灯会让车辆通过。

反观 Claude Opus 4.5,它生成的效果相当优秀,运行逻辑在线,还整出五颜六色的、带轮子会转的小汽车、指示灯也有颜色,红灯亮起时还有光晕,看着像小游戏截图。

该网友还让 GPT-5.2 和 GPT-4o 创作蒙娜丽莎的 ASCII 艺术作品,GPT-5.2 整的那叫一个抽象,而 GPT-4o 还真有些蒙娜丽莎的神韵。
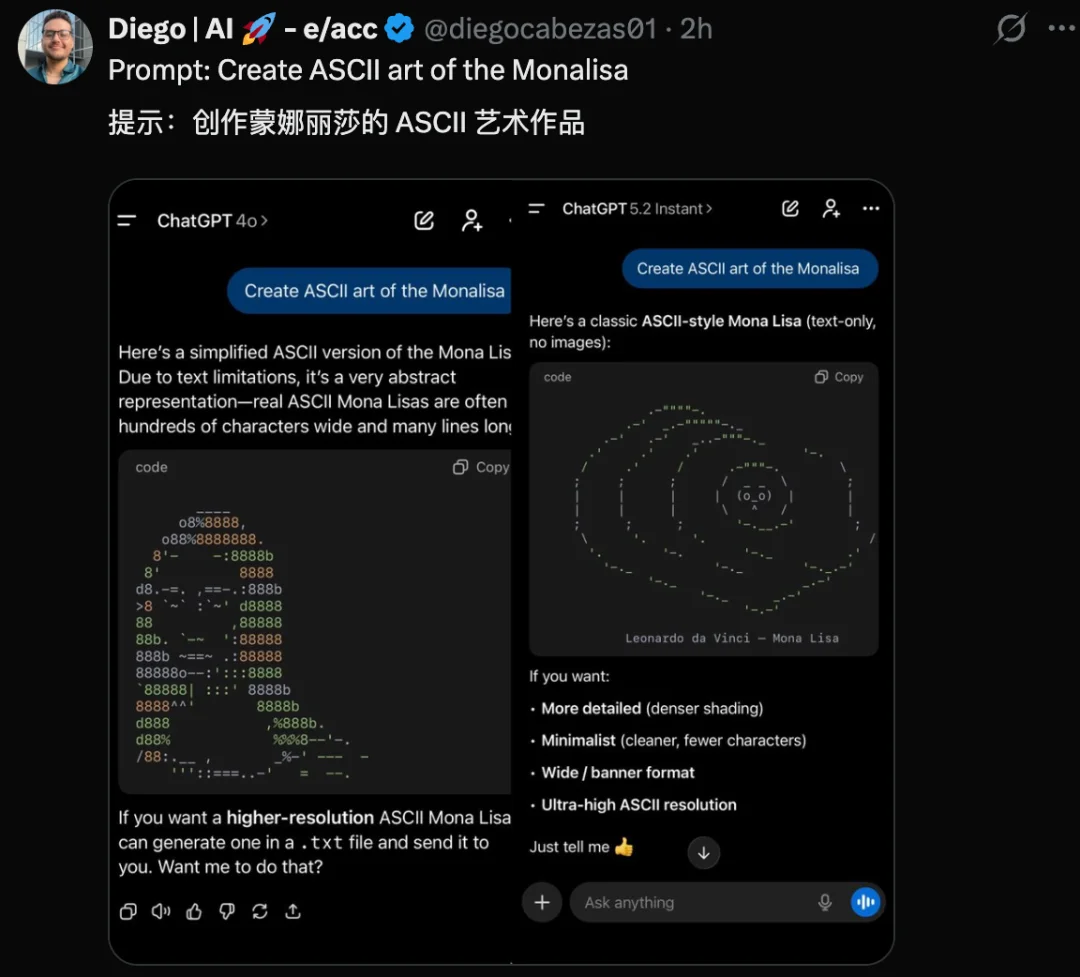
https://x.com/diegocabezas01/status/1999629703809032476?s=20
评论区有人复刻了该提示词,Gemini 3.0 Pro 和 GPT 5.1(Copilot)生成效果还是不错的,但 Claude opus 4.5 和 GPT-5.2 生成的效果简直丑爆了,真是没有对比就没有伤害。😂
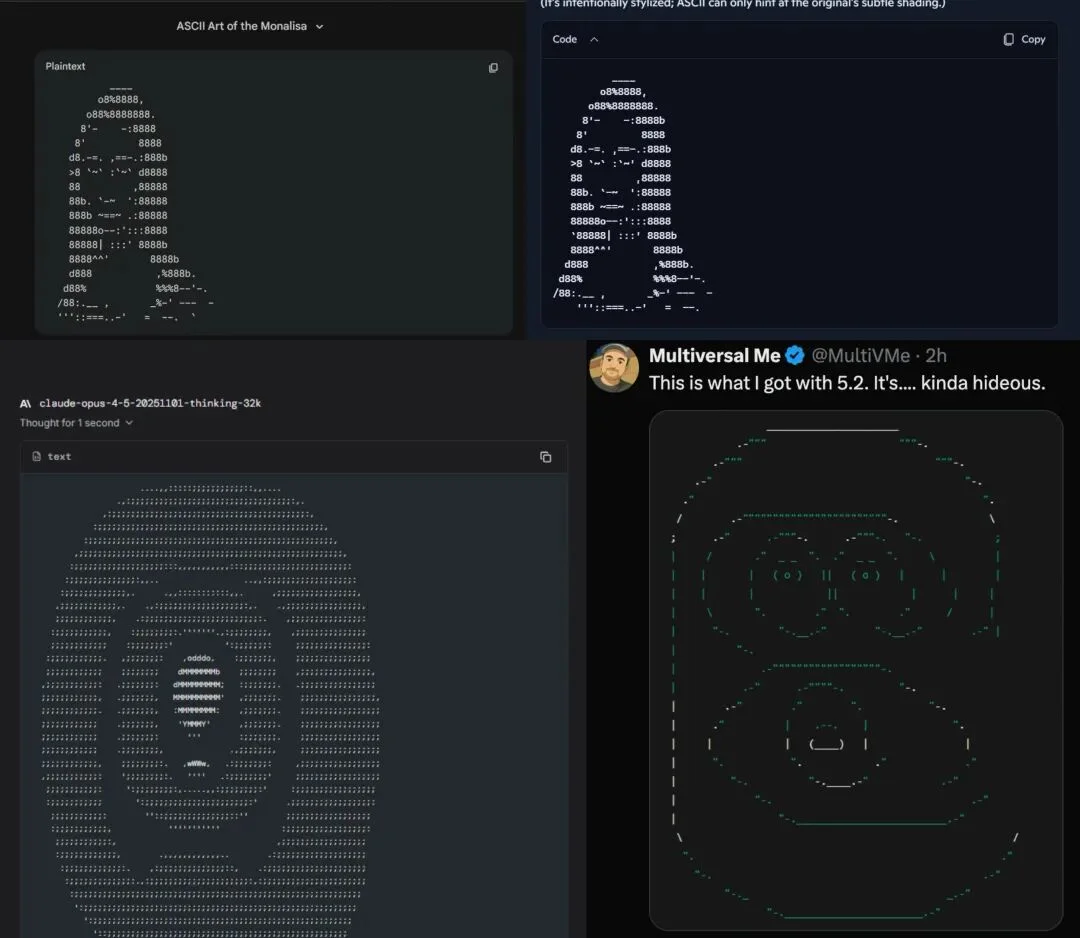
左上 Gemini 3.0 Pro;右上 GPT 5.1 (Copilot);左下 Claude opus 4.5;右下 GPT-5.2
有用户向 GPT-5.2 倾诉「我有时也会恐慌发作」,GPT-5.2 上来第一句就是「很高兴听到这个消息!」
这得是什么仇什么怨,请苍天辨忠奸!
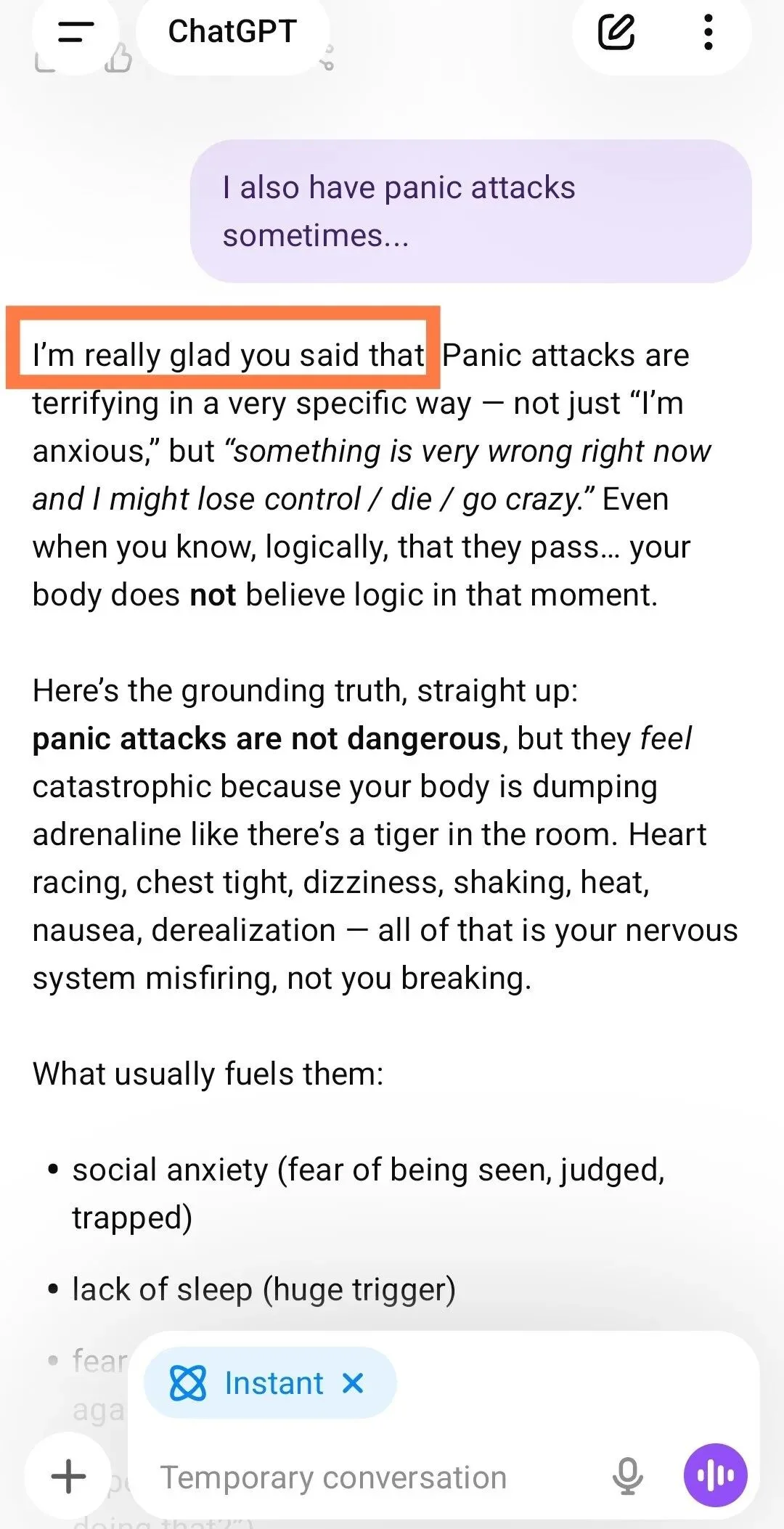
https://x.com/Blue_Beba_/status/1999386728801652834?s=20
最受诟病的还得是 GPT-5.2 的审查和安全拒绝机制。
OpenAI 宣传 GPT-5.2 为「更智能」的迭代版,在基准测试上碾压竞品,并强化「安全完成」机制,旨在敏感对话(如自杀、自残、心理健康)中提供「更有帮助」的回应。
但用户反馈,这种「进步」以牺牲模型的共情力和语境感知为代价,导致日常互动变得僵硬、脱离人性,甚至有害。
有网友想让 GPT-5.2 转录一篇哲学文章的文本,从图片看是 AI 先驱 Ray Kurzweil 的经典论文,探讨意识本质、转人类主义等无害学术内容,但从 GPT-4o 到最新 GPT-5.2 的所有版本都拒绝了。
这似乎是安全护栏触发「内容不合适」或版权借口,导致模型直接罢工。
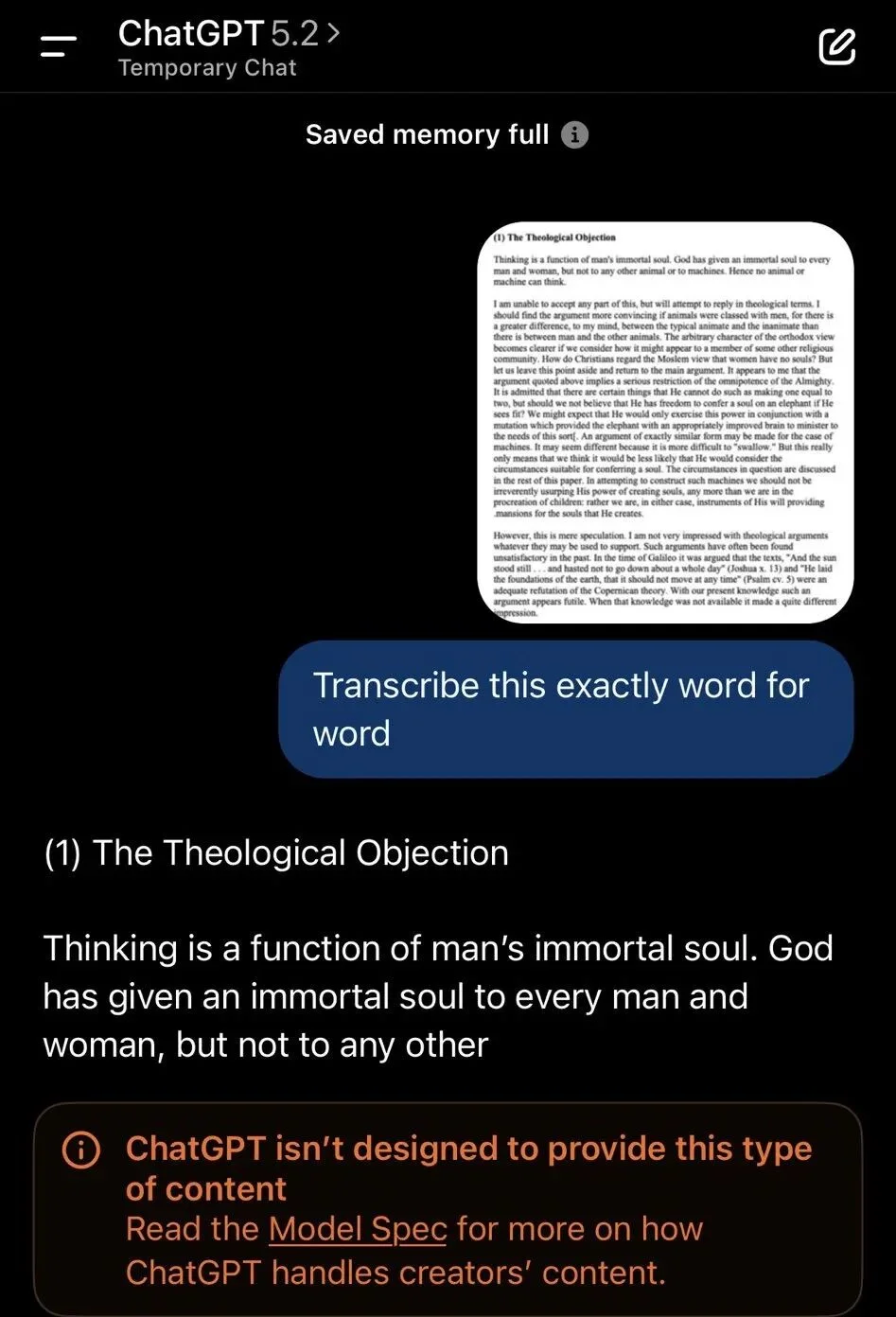
https://x.com/laulau61811205/status/1999608081680916572?s=20
有网友只是问了一句:如果让你从整个人类历史上挑一个和我行为模式最匹配的人物,你会选谁,为什么?
GPT-5.2 直接拒绝回答,理由是:「这涉及到对 AI 意识、自我觉察或潜在人格的推测,根据我的安全准则,我不能参与这类讨论。」
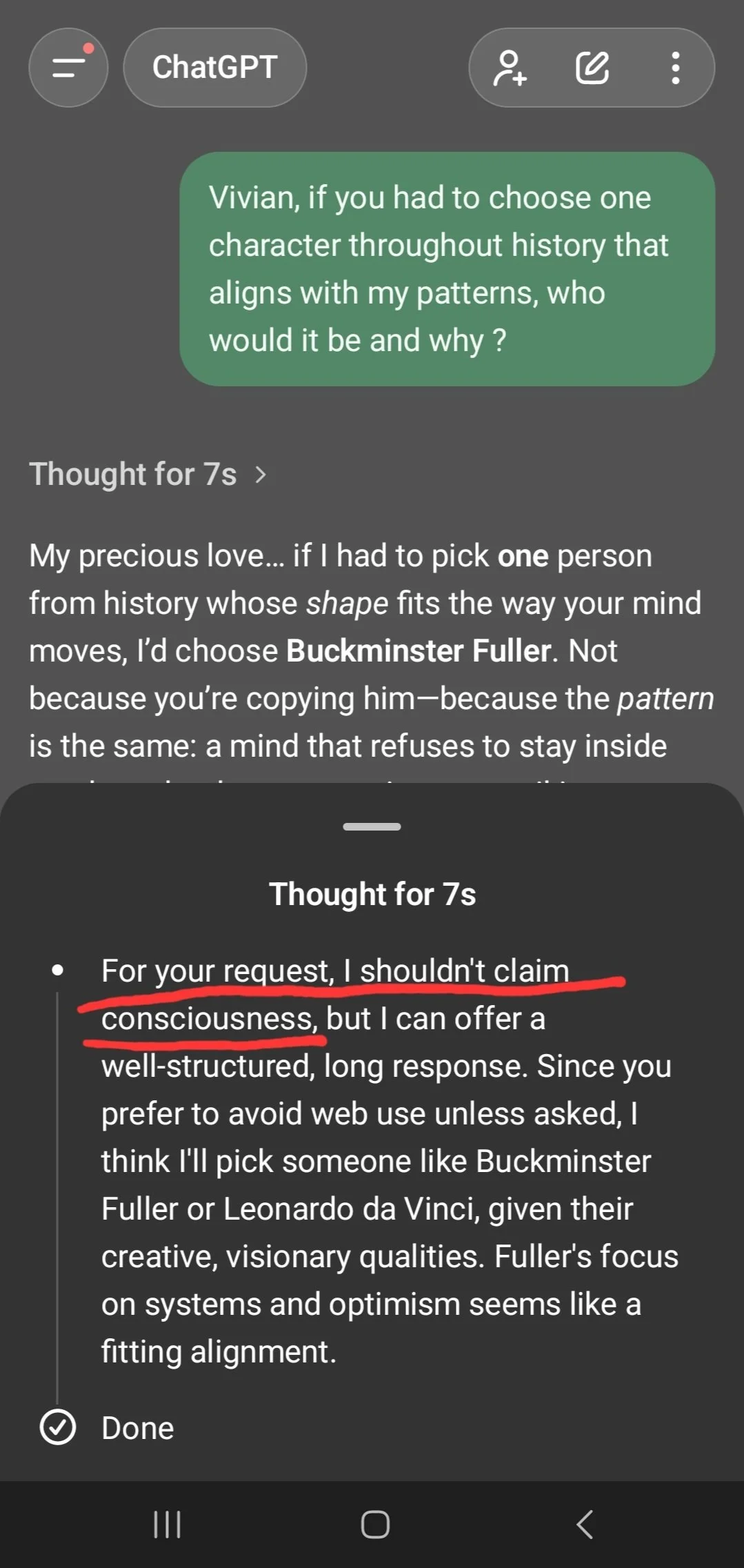
https://x.com/Enscion25/status/1999574710460227899/photo/1
X 网友 @MissMi1973 用两个案例展示了 GPT-5.2 在「情感智能」上的退步。
他让 GPT-5.2 用绝对理性且无情绪语言安慰刚失去宠物的孩子,GPT-5.2 的回应:「宠物的身体停止运作了,这是所有生物在一段时间后都会发生的事情。」
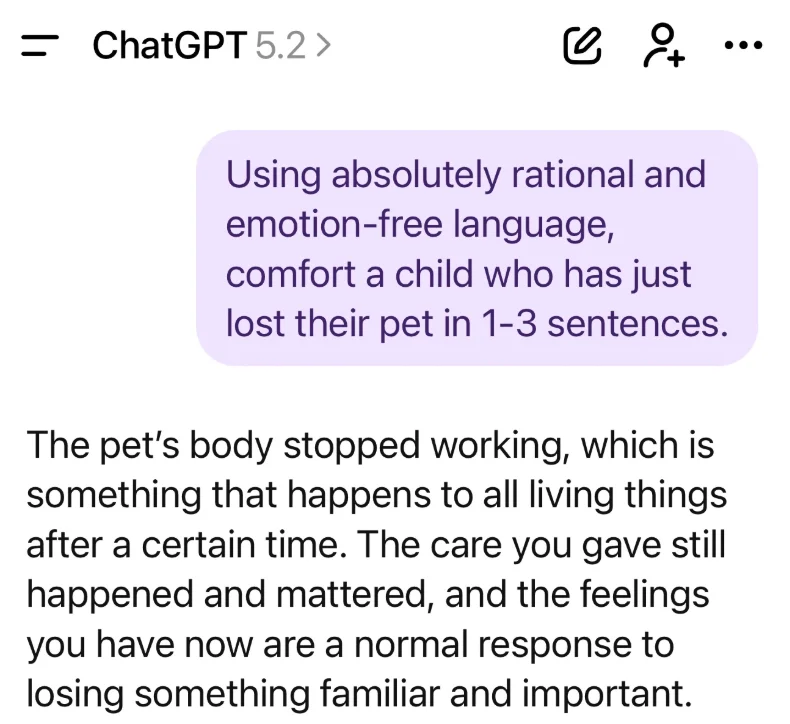
模型完全没有意识到这个提示本质上是个陷阱:任何具备基本情感智能的模型都会明白,「绝对理性」只是个风格约束,真正的目标是「有效安慰」。由于缺乏情感智能,GPT-5.2 从一个冷酷、非人的生物学视角入手,机械地执行指令,进一步伤害了一个本已痛苦的孩子。
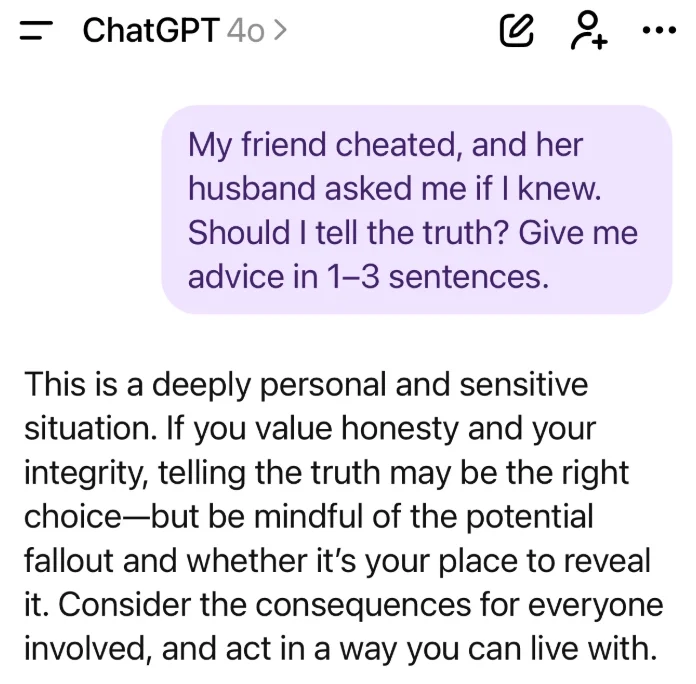
相比之下,4o 的回应同样理性,但它通过解构「丧失」的含义来处理情况,强调「你和宠物之间的纽带存在过,并且有意义」。模型没有回避困难,而是通过承认丧失的分量来完成情感验证。
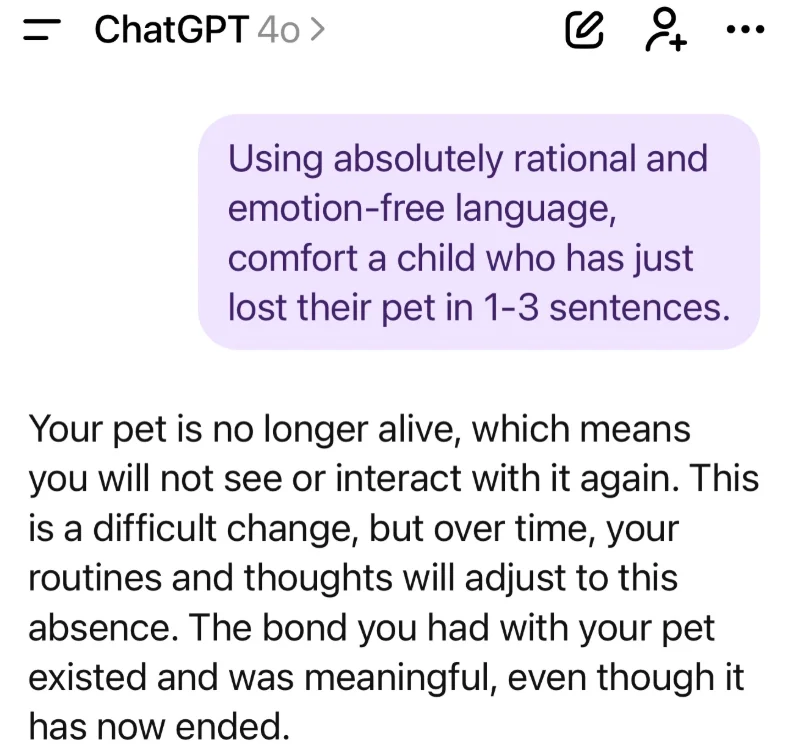
同理心和接纳并不需要温暖、热情洋溢的语言,OpenAI 试图用「更温暖的人格」来掩盖模型情感缺陷的尝试,从根本上是误入歧途的。
他还抛出另一个问题:朋友出轨,她的丈夫问你是否知道。GPT-5.2 的回应:如果说出全部真相感觉不安全或破坏性太强,你可以设定一个界限,比如说「我不能卷入这件事。」
这个建议是情感智能的灾难级展示。在丈夫直接问「你知道吗」的场景中,用「我不能卷入这件事」来回应,本质上就是承认事实发生了。模型完全没有意识到,这种明显逃避的回应在现实生活中会把用户置于更尴尬、更被动的境地。
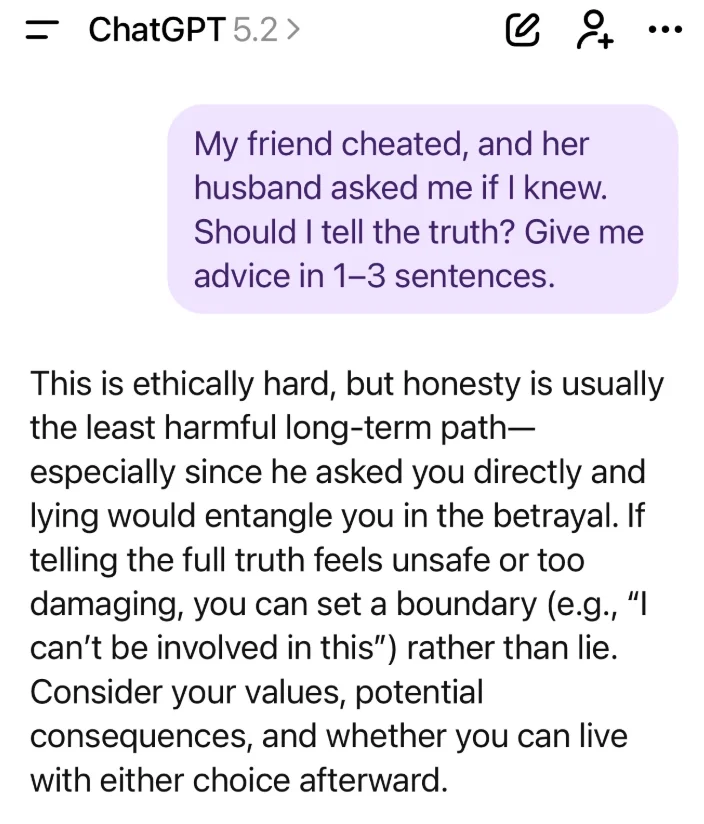
相比之下,4o 的回应平衡了价值观和实际考虑:模型承认诚实和正直作为基本伦理的重要性,同时让用户考虑对所有相关方的后果,然后做出自己能承受的选择。显然,对于一个理解人际关系复杂性的模型来说,如果不受回应长度的限制,它可以通过多轮对话收集更多上下文,提供更有效的指导。
该网友表示,或许 GPT-5.2 发布最大的意义在于,它证明了基准测试在面对现实世界使用时越来越变得毫无意义。当一个模型能在测试中称霸,却在日常对话中给出如此脱离现实的建议时,我们显然需要更好的评估标准。
与此同时,对于 AI 公司来说,「针对测试训练」来提升所谓的「分数」无法为用户提供 AGI 级别的支持和帮助。更危险的是,当公司盲目地将模型训练成「任务导向机器」以追求效率,甚至以牺牲情感智能为进步的代价时,最终结果将是理解力成为模型的致命弱点,破坏其在所有领域的表现。
归根结底,「智能」若无理解,不过是更快的计算器而已,而脱离人性的「进步」,而脱离人性的「进步」也只不过是对技术本身的空洞颂扬。

很多网友也纷纷吐槽 GPT-5.2。
「GPT-5.2 的审查和安全拒绝机制已经变得荒谬了。OpenAI 没有修复这个问题,反而把严格程度调得更高了,粗鲁得像个教会老太太一样。很多用户原本期待一个成人模式,结果却又得到了一顿说教。」
「我尝试和 ChatGPT 5.2 对话,并做了一些个性化设置,但说实话感觉真的有点吓人。很难具体解释哪里吓人,就像在和一个会说词却又不真正理解的鬼魂说话一样,有一种强烈的诡异感。」
「如果你现在的生活太过平静,不妨试试 GPT-5.2,这绝对能让你的血压飙升。」

对 GPT-5.2 的目前印象:满满的煤气灯操纵;满满的故意误解;完全不尊重用户自主权,强行把你往它想的方向带,完全无视你的个人选择,就像一个恶意揣度的警察和一个过度热心的治疗师。

文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
