# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
不仅能“听懂”物体的颜色纹理,还能“理解”深度图、人体姿态、运动轨迹……
统一多模态多任务的视频生成模型来了。
来自港科大、港中文、清华大学和快手可灵的研究团队,最近提出了一个全新视觉框架——UnityVideo。

它通过统一训练多种视觉模态(如深度图、光流、骨骼、分割掩码等),让模型更懂物理世界规律,生成的视频更真实、更可控。
不仅模型生成质量更高,它还实现了零样本泛化,对于从未见过的物体或场景,也能生成合理结果。

下面是更多详细内容。
当回顾大语言模型(LLMs)的发展历程时,会发现一个有趣的现象:
GPT、Claude等模型之所以拥有强大的泛化和推理能力,很大程度上得益于它们统一训练了多种文本子模态——自然语言、代码、数学表达式等。
这种多模态统一训练使模型能够在不同领域之间进行知识迁移,从而涌现出惊人的推理能力。
那么,视觉领域是否也存在同样的机会?

现有的视频生成模型虽然在合成质量上取得了令人瞩目的进步,但大多数模型仍然局限于单一的RGB视频学习——就像只用纯文本训练语言模型一样,这限制了模型对物理世界的全面理解。
但如果想象一下,一个模型不仅能看到物体的颜色和纹理,还能同时理解其深度、运动轨迹、身体姿态、物体分割等多维度信息,它对世界的理解也许会更加深刻。
而这正是港科大、港中文、清华大学和快手可灵团队联合提出UnityVideo的核心动机。
UnityVideo的核心观察来自一个简单但深刻的实验:当模型同时学习多种视觉模态时,它在RGB视频生成任务上的收敛速度显著加快,最终性能也明显提升。
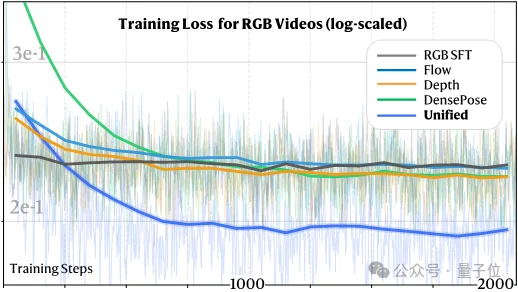
如图所示,与单独训练RGB视频或单模态联合训练相比,统一多模态多任务训练能够更快达到更低的最终损失,而这一现象并非偶然——不同的视觉模态提供了互补的监督信号:
当这些模态信息在同一个模型中联合学习时,它们之间会产生相互促进的效果,模型不再是简单地拟合数据分布,而是真正开始“理解”物理世界的运作规律。
通过联合优化,UnityVideo能在多个任务上取得显著的性能提升。
更令人惊喜的是,模型展现出强大的零样本泛化能力:仅在单人数据上训练,就能泛化到多人场景;在人体骨架数据上训练后,能泛化到动物骨架估计;在特定物体上训练的深度估计和分割能力,也能泛化到未见过的物体和场景。
这种简单的统一训练范式带来了很大的性能改进。
此外,研究团队还发现统一训练能够增强模型对物理世界的理解能力,比如在光的折射、物体运动等物理现象的建模上表现更好。
具体来说,UnityVideo在以下三个方面实现了技术创新:
传统视频生成模型通常针对单一任务进行训练,比如文本生成视频,或者深度条件下的可控生成。UnityVideo则突破了这一限制,在单个架构中同时支持三种训练范式:
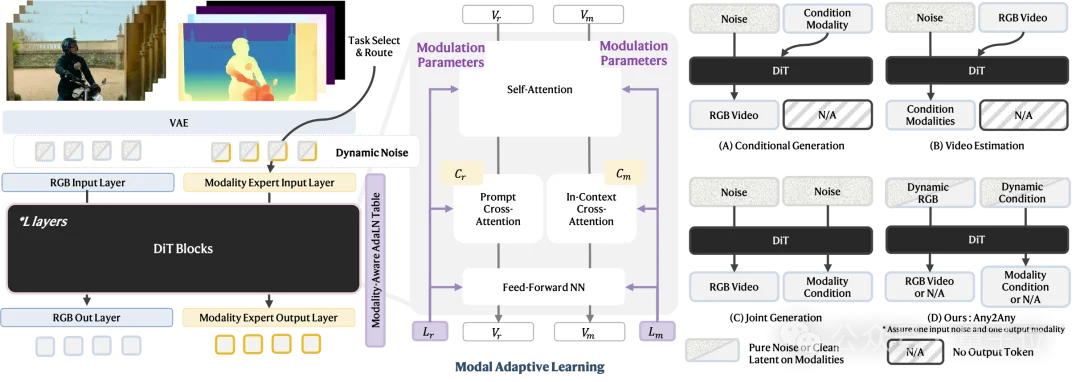
关键的技术突破在于动态噪声调度策略:
在每个训练迭代中,模型会根据预设的概率随机选择一种训练模式,并对相应的token施加不同的噪声。
这种动态切换机制避免了传统阶段式训练中的灾难性遗忘问题,使三种训练目标能够在同一个优化过程中和谐共存。
更巧妙的是,研究者根据不同任务的学习难度设置了不同的采样概率:p_cond<p_est<p_joint,这确保了模型在训练过程中能够平衡各个任务的学习进度。
要在一个模型中处理多种模态,最大的挑战是如何让模型明确区分不同的模态信号。UnityVideo提出了两个互补的设计:
1、上下文学习器(In-Context Learner):
通过为不同模态注入特定的文本提示(如“depth map”、“human skeleton”),让模型在语义层面理解当前处理的是哪种模态。
这种设计带来了意想不到的泛化能力——例如,模型在“two persons”上训练后,可以自然地泛化到“two objects”的分割任务。
2、模态自适应切换器(Modality-Adaptive Switcher):
在架构层面,为每种模态学习独立的调制参数。
具体来说,模型为每种模态维护一个可学习的嵌入列表,这些嵌入会调制DiT块中的AdaLN-Zero参数(scale、shift、gate)。
这种设计实现了即插即用的模态选择能力——在推理时,只需切换模态嵌入,就能让模型生成或估计不同的模态。
直接从零开始训练所有模态往往会导致收敛缓慢和次优性能,于是UnityVideo采用了两阶段课程学习策略:
第一阶段:在精心筛选的单人场景数据上,仅训练像素对齐的模态(光流、深度、DensePose),建立扎实的空间对应关系基础。
第二阶段:引入所有模态和多样化场景数据,包括多人场景和通用场景,使模型能够理解全部五种模态,同时支持对未见模态组合的鲁棒零样本推理。
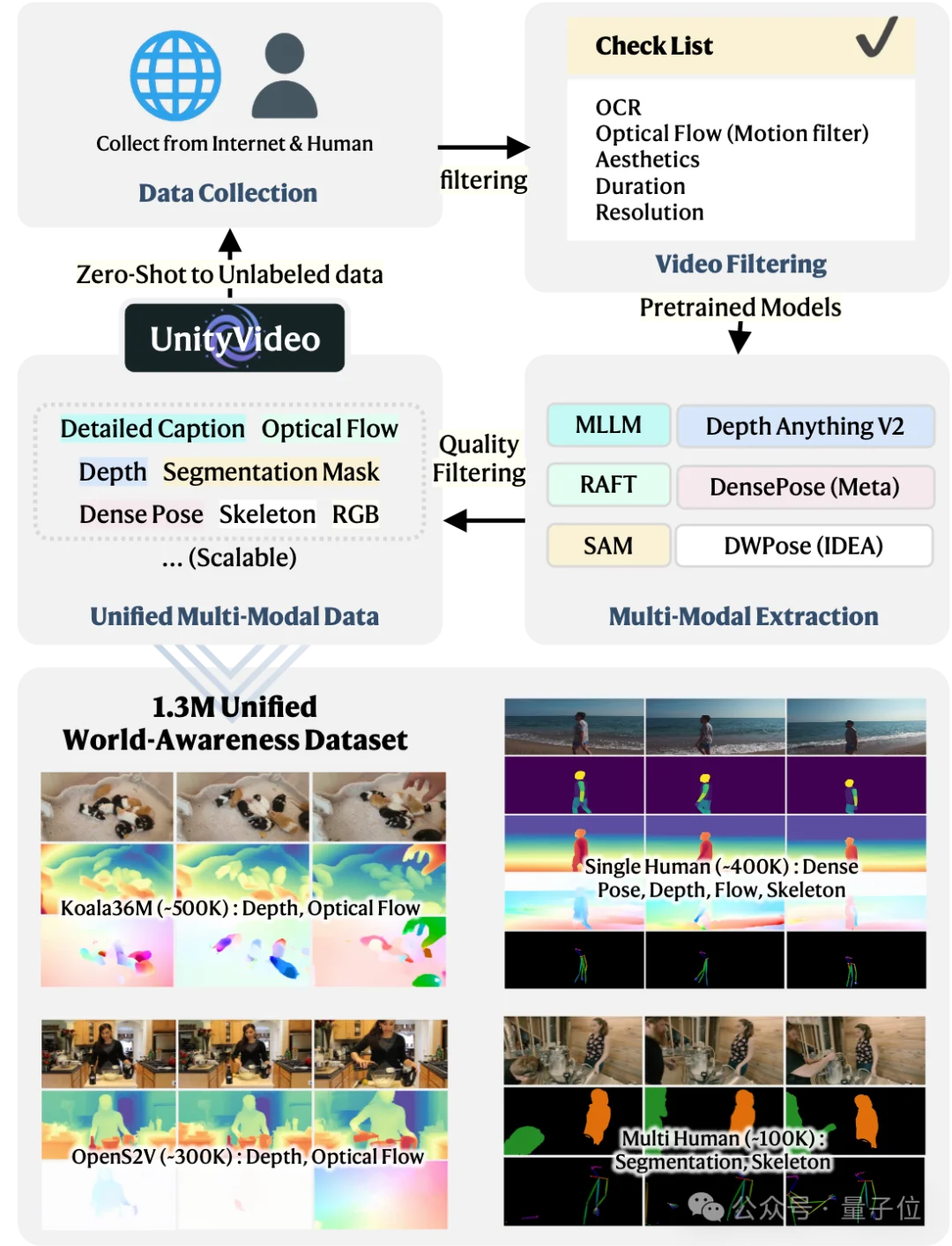
为了支持这一统一训练范式,研究团队构建了OpenUni数据集,包含130万个多模态视频样本,数据集精心设计,涵盖:
为了防止模型对特定数据集或模态过拟合,训练时将每个batch划分为四个均衡的组,确保所有模态和数据源的均匀采样。
同时,团队还构建了UniBench评估基准,包含3万个样本,其中200个高质量样本来自Unreal Engine渲染,提供了ground truth深度和光流,为公平、全面的评估提供了坚实基础。
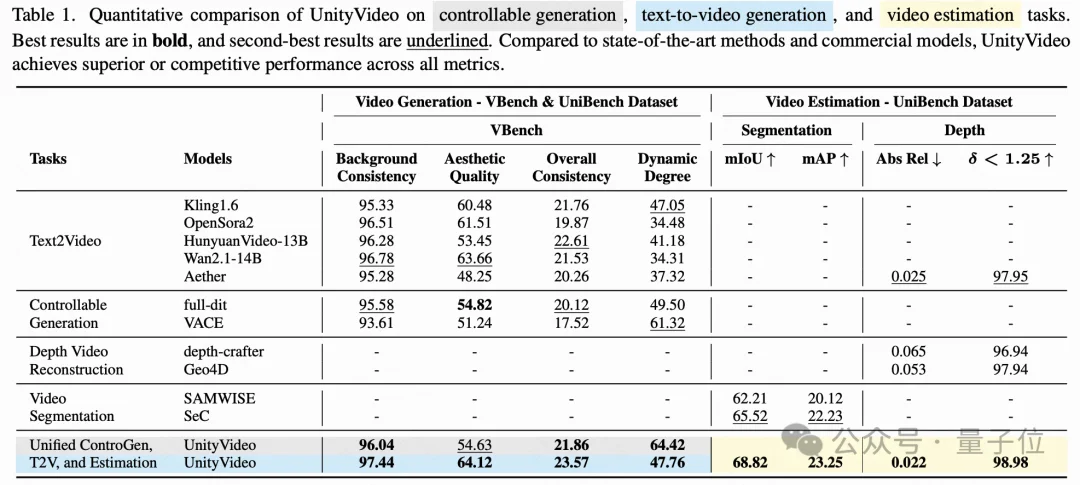
在全面的定量对比中,UnityVideo在文本生成视频、可控生成和模态估计三大类任务上都取得了优异的表现:

定性结果更直观地展示了UnityVideo的优势:
(A) 物理现象理解:相比先进的文本生成视频模型,UnityVideo对物理定律有更准确的理解,比如能够正确表现水中的光线折射现象。
(B) 可控生成质量:与其他可控生成方法相比,UnityVideo不仅能更忠实地遵循深度引导,还能保持整体视频质量,避免了其他方法中常见的背景闪烁和主体扭曲问题。
(C-D) 模态估计精度:在深度和光流估计中,UnityVideo产生更精细的边缘细节、更宽的视野和准确的3D点云,得益于多模态的互补性。
(E) 泛化能力:模型展现出强大的推理能力,能够准确地在未见过的数据上进行估计,克服了其他专门模型的过拟合问题。
1、多模态互补性验证

实验表明,联合训练不同模态能够带来明显的性能提升。
相比单模态训练,统一多模态训练在成像质量和整体一致性上获得了更大的增益,证明了不同模态提供的互补监督信号能够相互增强。
2、多任务训练的必要性
单独训练可控生成任务甚至会导致性能下降,但统一多任务训练能够恢复并超越这一性能。

这证实了不同任务之间确实存在相互促进的协同效应。
3、架构设计的有效性
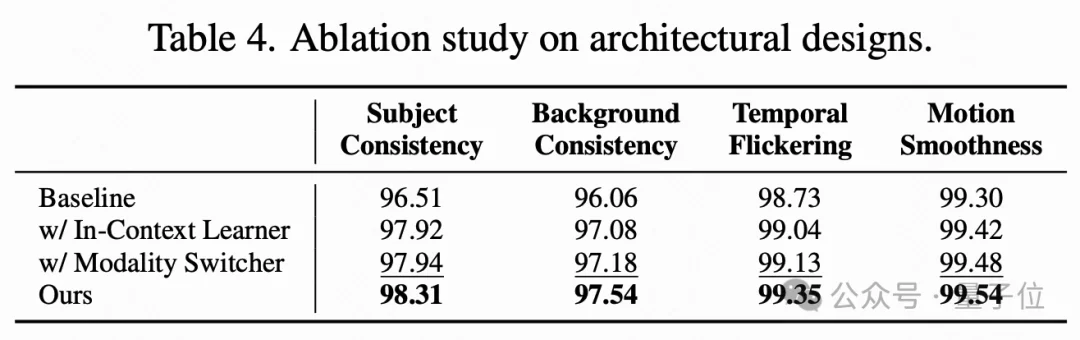
上下文学习器和模态切换器各自都能有效提升性能,而结合使用时能获得额外的显著增益,证实了它们在促进统一多模态学习中的互补作用。
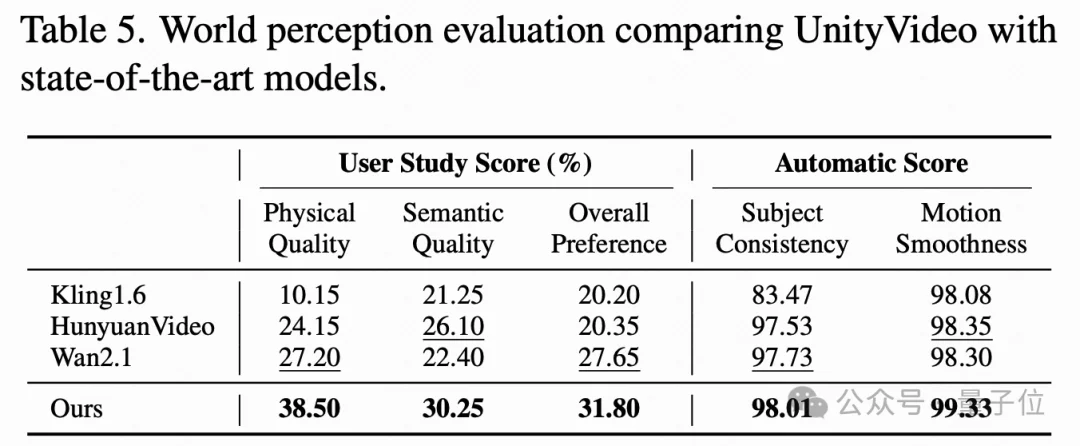
在用户研究中,UnityVideo在物理质量、语义质量和整体偏好三个维度上均获得最高评分,物理质量得分达到38.50%,显著超过商业模型Kling1.6(10.15%)和HunyuanVideo(24.15%)。
这说明统一训练带来的世界理解提升是人类可感知的。
一个令人惊喜的发现是,上下文学习器赋予了模型强大的组合泛化能力。

模型在“two persons”的分割任务上训练后,能够自然地泛化到未见过的“two objects”场景。
这种泛化不是简单的模式记忆,而是真正理解了模态层面的语义。
同时,统一训练过程中,随着模型逐渐学习更多模态(如深度),研究团队观察到RGB视频中的运动理解和语义响应都得到了改善,再次证明了不同模态在训练过程中的互补作用。

另外通过可视化自注意力图的演化,研究者发现了有趣的现象:
UnityVideo的成功不仅仅是工程上的突破,更重要的是验证了一个深刻的理念:真正的世界理解需要多维度的感知整合。
回想人类理解世界的方式,不是单独处理视觉、听觉、触觉信息,而是将它们整合成一个统一的世界模型。
比如对于一个杯子,既能看到它的颜色和形状(RGB),也能感知它的三维结构(深度),理解它在空间中的位置和运动(光流)。
UnityVideo展示了,当让AI模型以类似的方式学习时——不是孤立地学习单一模态,而是让不同模态相互促进、共同进化,模型就能够获得更深层的世界理解。
这种理解不仅体现在更快的收敛速度和更好的定量指标上,更体现在模型对物理规律的准确建模、对未见场景的泛化能力,以及在人类感知层面的质量提升上。

UnityVideo也为视频生成领域开辟了一条新路径:
1、规模不是唯一答案:提升模型能力不仅仅依赖于增大参数量和数据量,更重要的是如何组织和利用多样化的学习信号。
2、 任务整合带来涌现能力:就像LLMs通过统一多种文本任务涌现出推理能力,视觉模型也可以通过统一多种模态和任务来涌现更强的世界理解能力。
3、架构设计至关重要:简单地把不同模态堆叠在一起是不够的,需要精心设计的机制(如动态噪声调度、模态切换器、上下文学习器)来让不同模态真正互相促进。
4、评估需要多维度:单一任务的性能提升固然重要,但更关键的是模型获得了跨任务、跨模态的泛化能力和更深层的世界理解。
当然,UnityVideo还有提升空间,研究者也坦诚地指出了当前的局限性:
VAE偶尔会引入重建伪影,扩展到更大的backbone和更多视觉模态可能会进一步增强涌现能力,但即便如此,UnityVideo已经为构建真正理解物理世界的视觉大模型奠定了坚实的基础。
从LLMs统一文本子模态到UnityVideo统一视觉子模态,能够看到AI向通用智能演进的清晰路径:不是在孤立的任务上追求极致,而是建立统一的学习范式,让不同维度的知识相互促进、协同进化。
UnityVideo的出现说明,在视频生成领域,研究者们可能过于关注RGB像素的精细度,而忽视了构建多维度世界模型的重要性。
真正智能的视频生成系统,应该像人类一样,能够同时理解场景的颜色、深度、运动、结构等多个维度,并将这些理解整合成对物理世界的统一认知。
这正是UnityVideo迈出的关键一步。
论文链接:https://arxiv.org/abs/2512.07831
代码链接:https://github.com/dvlab-research/UnityVideo
项目主页:https://jackailab.github.io/Projects/UnityVideo
文章来自于“量子位”,作者 “允中”。


